AlexNet,VGG,GoogleNet,ResNet
AlexNet:
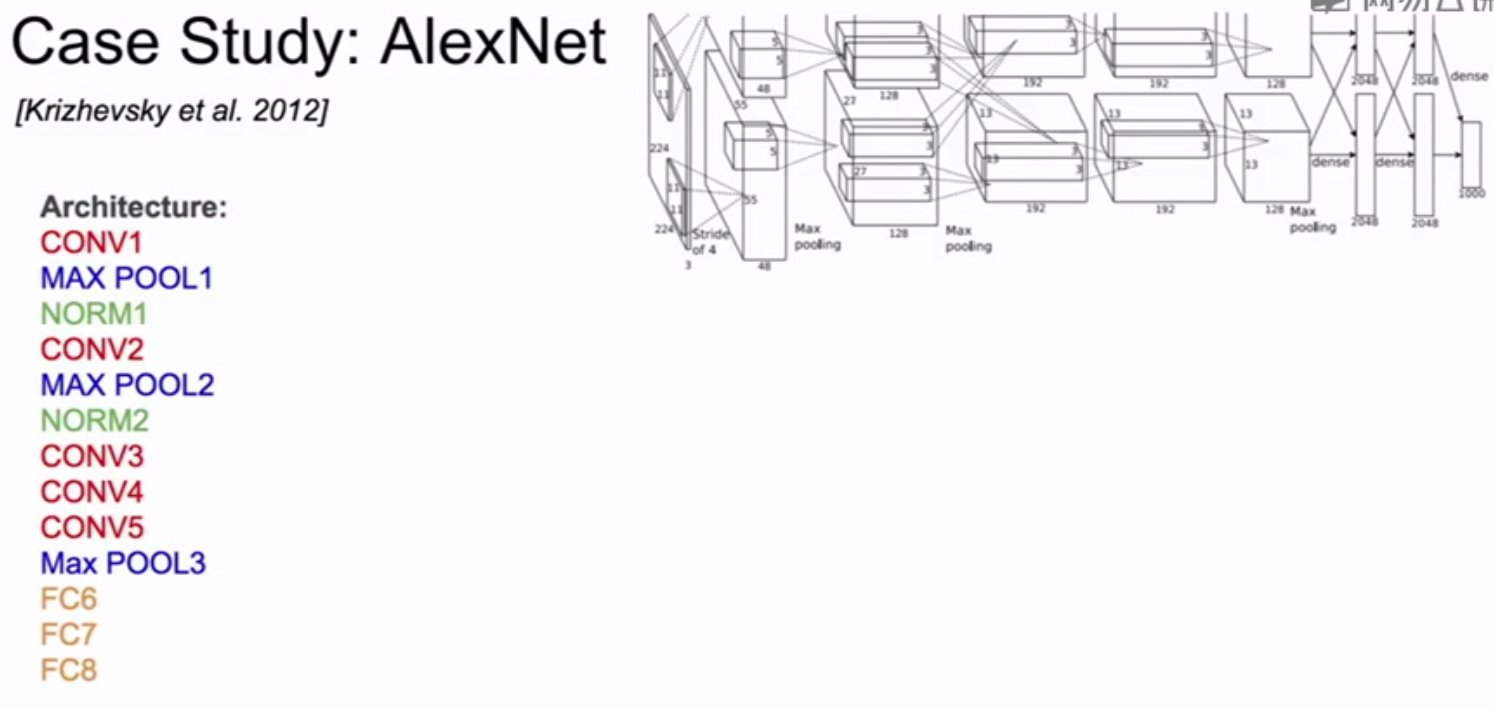


VGGNet:

用3x3的小的卷积核代替大的卷积核,让网络只关注相邻的像素

3x3的感受野与7x7的感受野相同,但是需要更深的网络
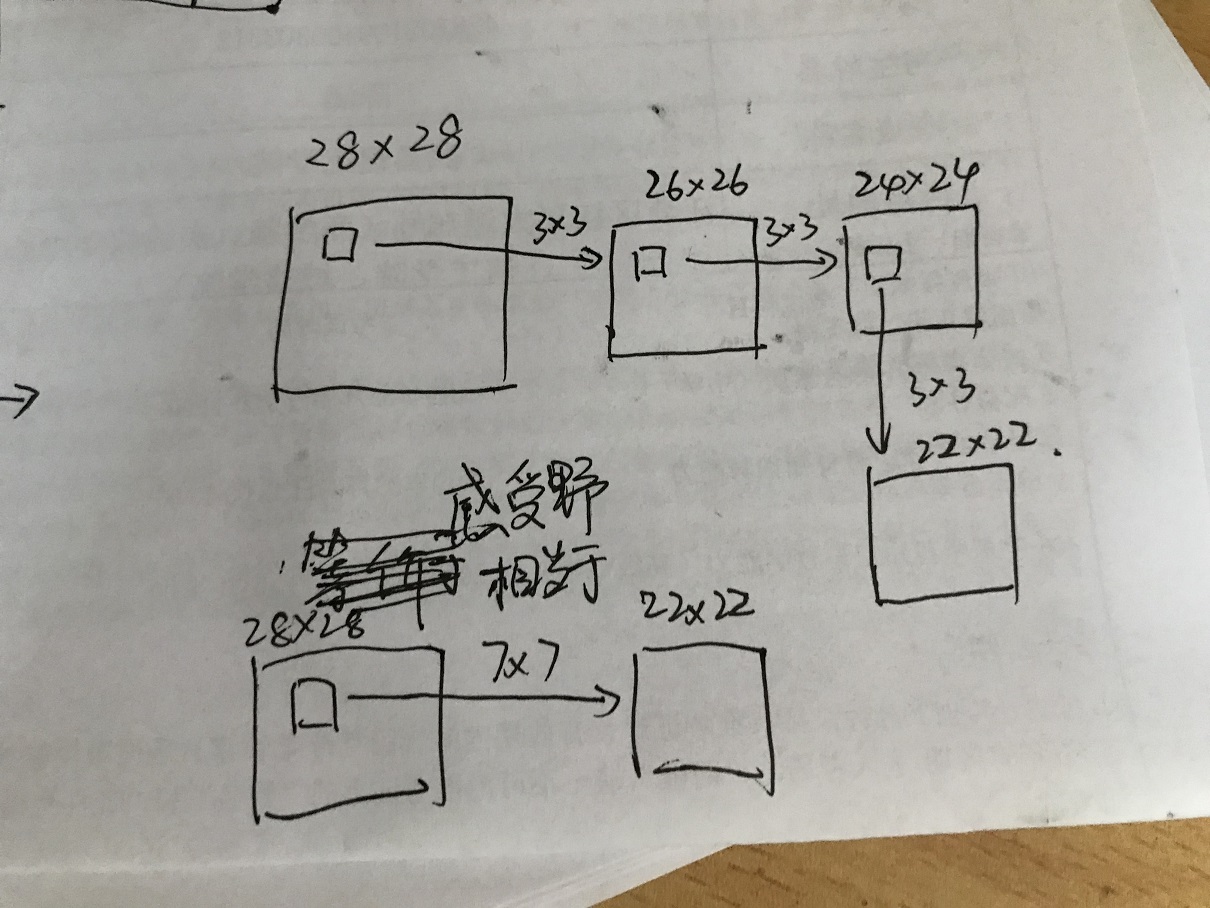
这样使得参数更少


大多数内存占用在靠前的卷积层,大部分的参数在后面的全连接层

GoogleNet:
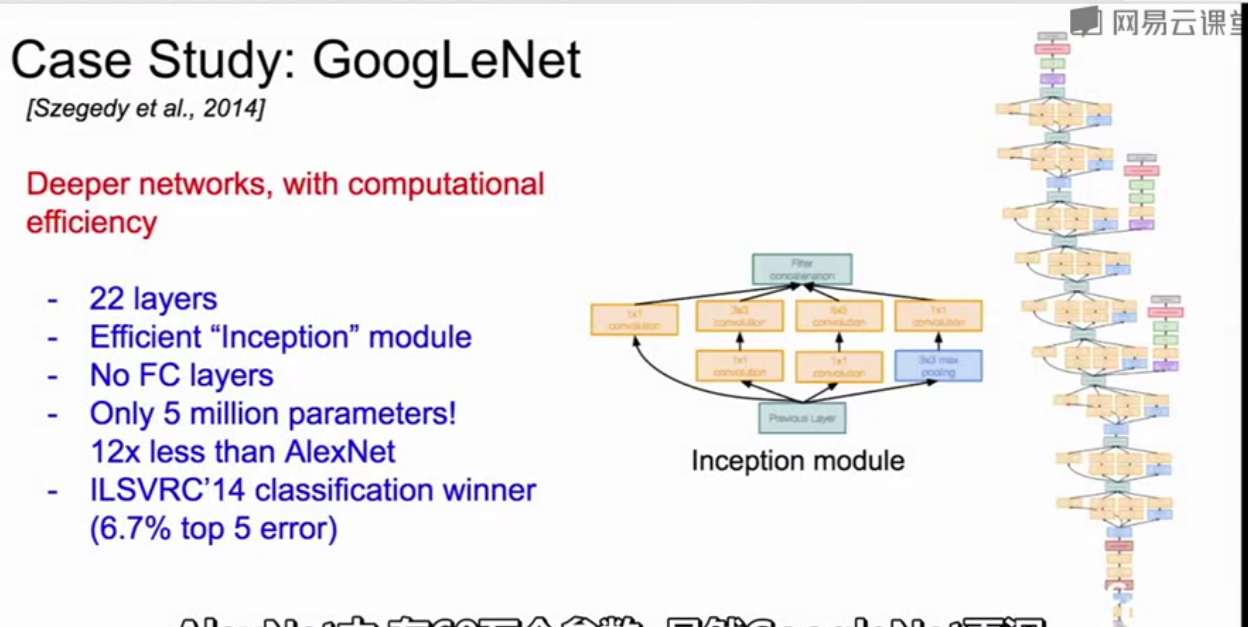

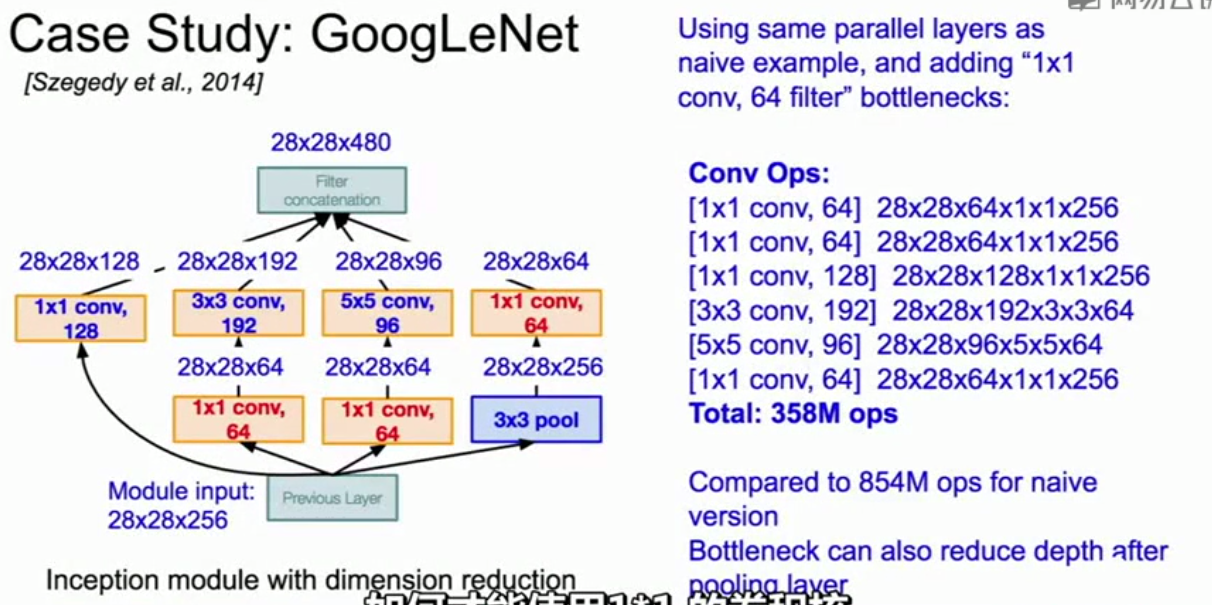
Inception模块:设计了一个局部网络拓扑结构,然后堆放大量的局部拓扑在每一个的顶部
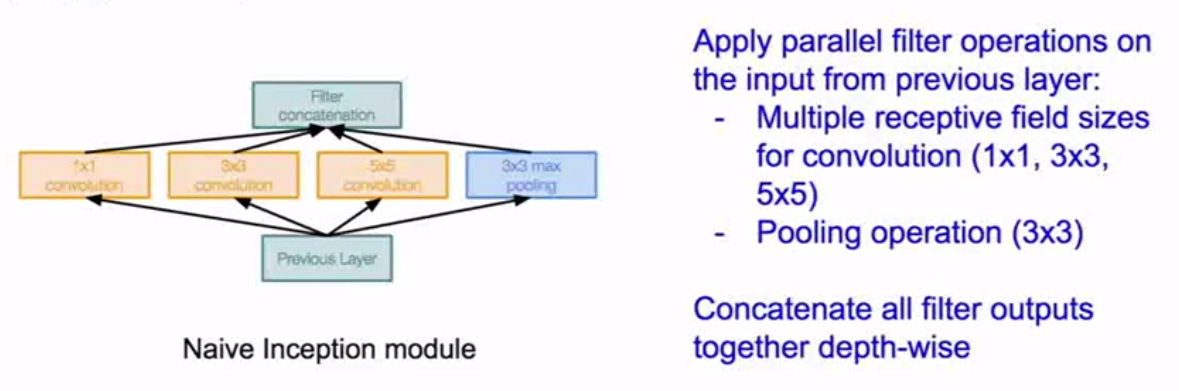
目的是将卷积和池化(filter)操作并行,最后在顶层将得到的输出串联得到一个张量进入下一层
这种做法会增加庞大的计算量:

(图中输入输出尺寸不变是因为增加了零填充)
为了降低计算量,会在inception之前增加一个瓶颈层通过1x1的卷积核进行降维操作

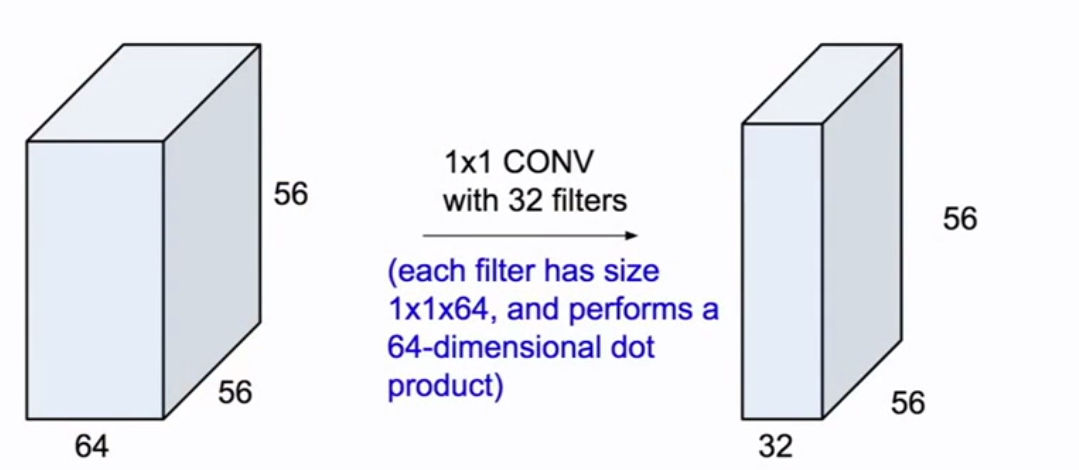


相比没有1x1卷积核的降维,计算量从8.54亿次减小到3.58亿次
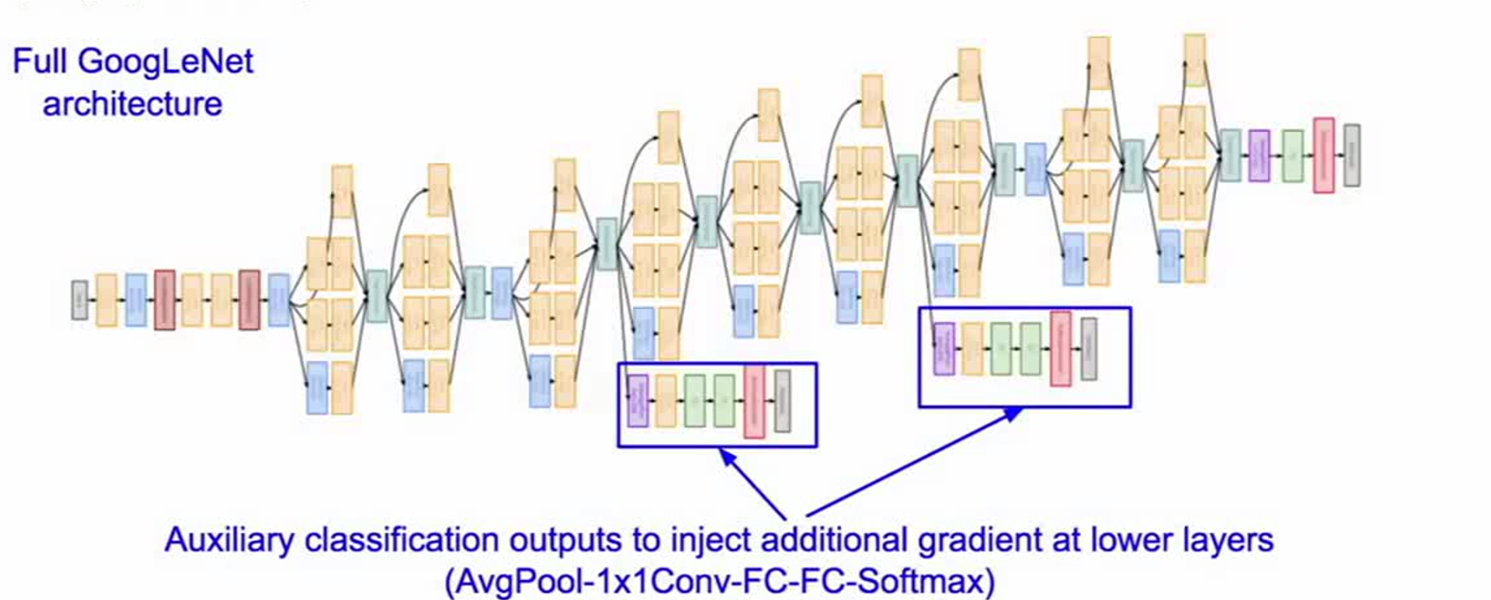
网络结构尾部完全移除全连接层,大量减少参数;有两个额外的辅助分类层

ResNet:

单纯不停的堆叠卷积层池化层plain convolutional neural network不使用残差结构)来加深网络的深度并不能表现得更好(不是因为过拟合,在训练集上表现得也不如20层的网络)
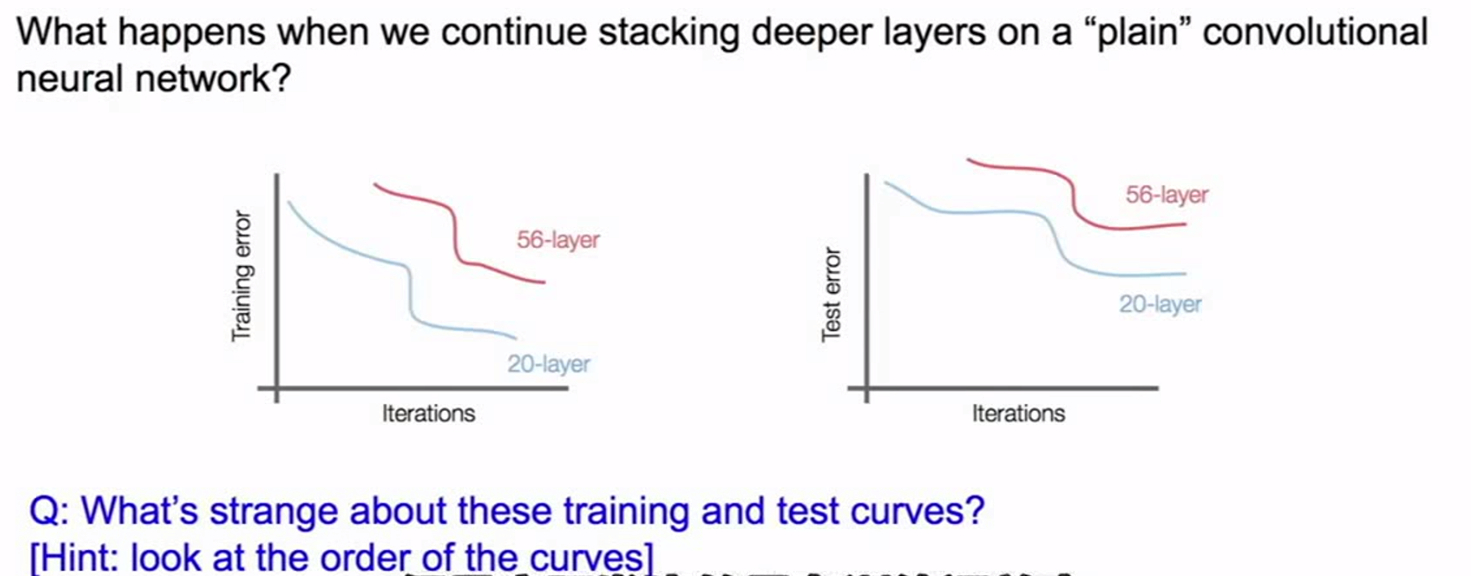
这是一个优化问题,深层的网络更加难以优化

深层的网络至少会跟浅层的网络表现的一样好,解决方案是将从浅层模型学到的层通过恒等映射copy到较深的层。
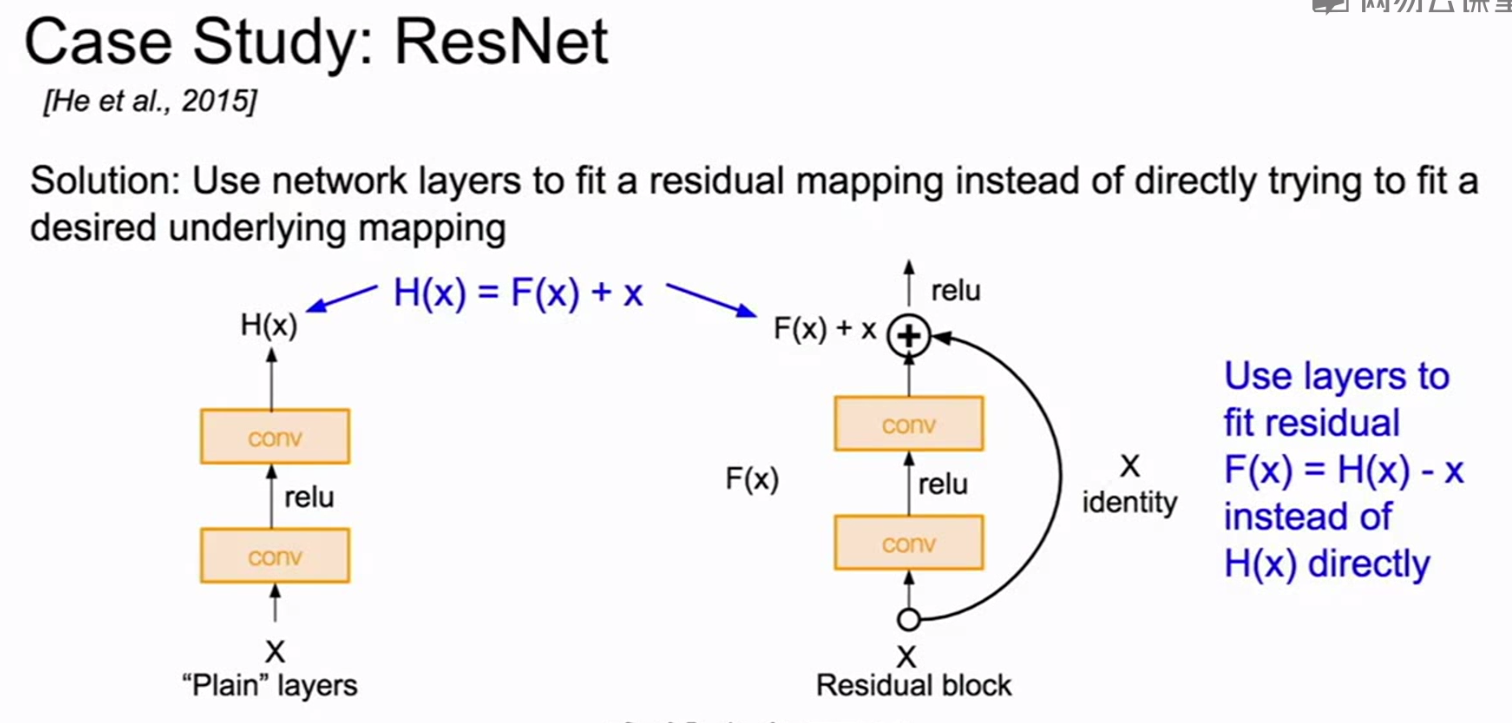
若将输入设为X,将某一有参网络层设为H,那么以X为输入的此层的输出将为H(X)。一般的CNN网络如Alexnet/VGG等会直接通过训练学习出参数函数H的表达,从而直接学习X -> H(X)。
而残差学习则是致力于使用多个有参网络层来学习输入、输出之间的参差即H(X) - X即学习X -> (H(X) - X) + X。其中X这一部分为直接的identity mapping,而H(X) - X则为有参网络层要学习的输入输出间残差。
残差学习单元通过Identity mapping的引入在输入、输出之间建立了一条直接的关联通道,从而使得强大的有参层集中精力学习输入、输出之间的残差。一般我们用F(X, Wi)来表示残差映射,那么输出即为:Y = F(X, Wi) + X。
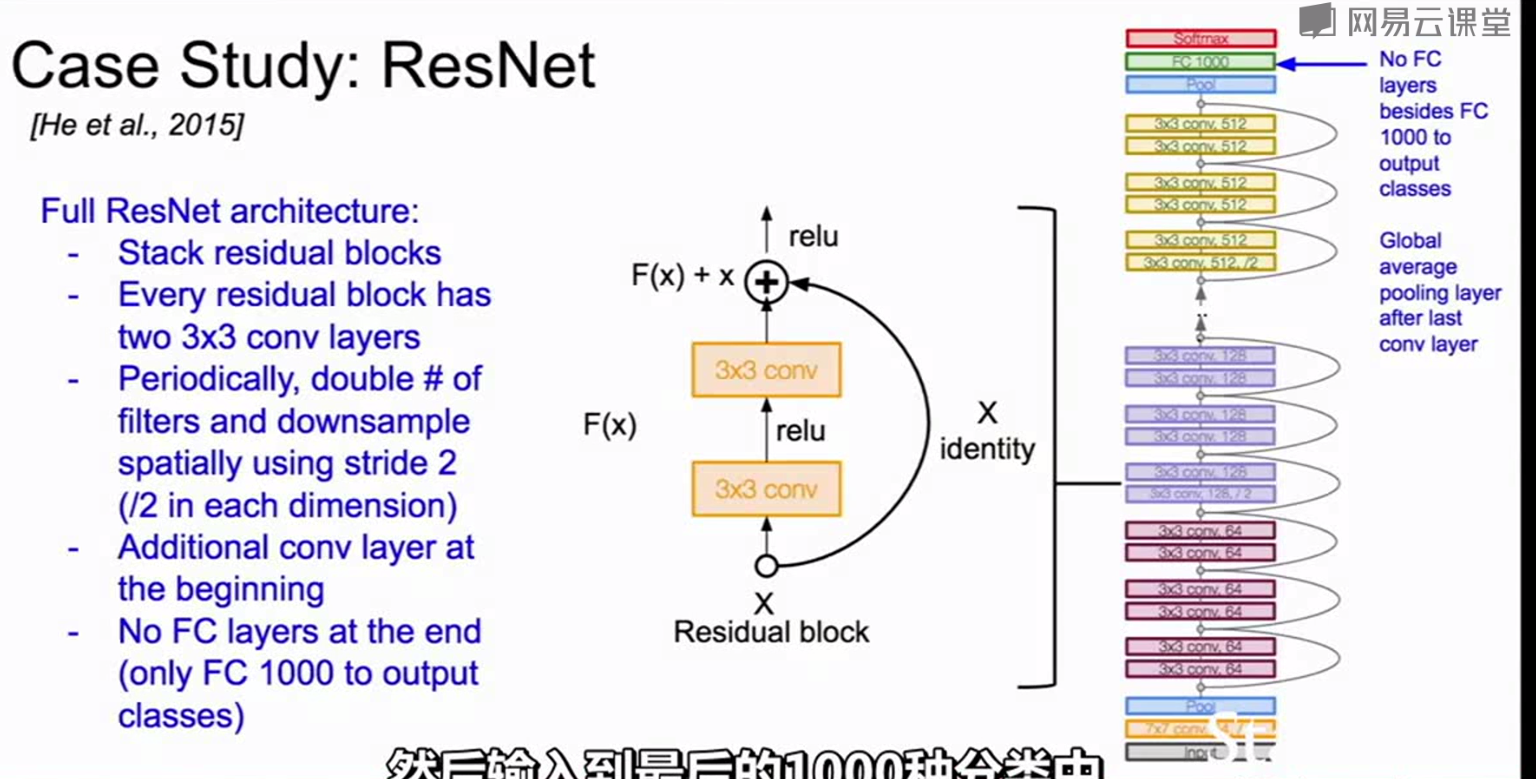
resnet也用到了GoogleNet中的瓶颈层操作


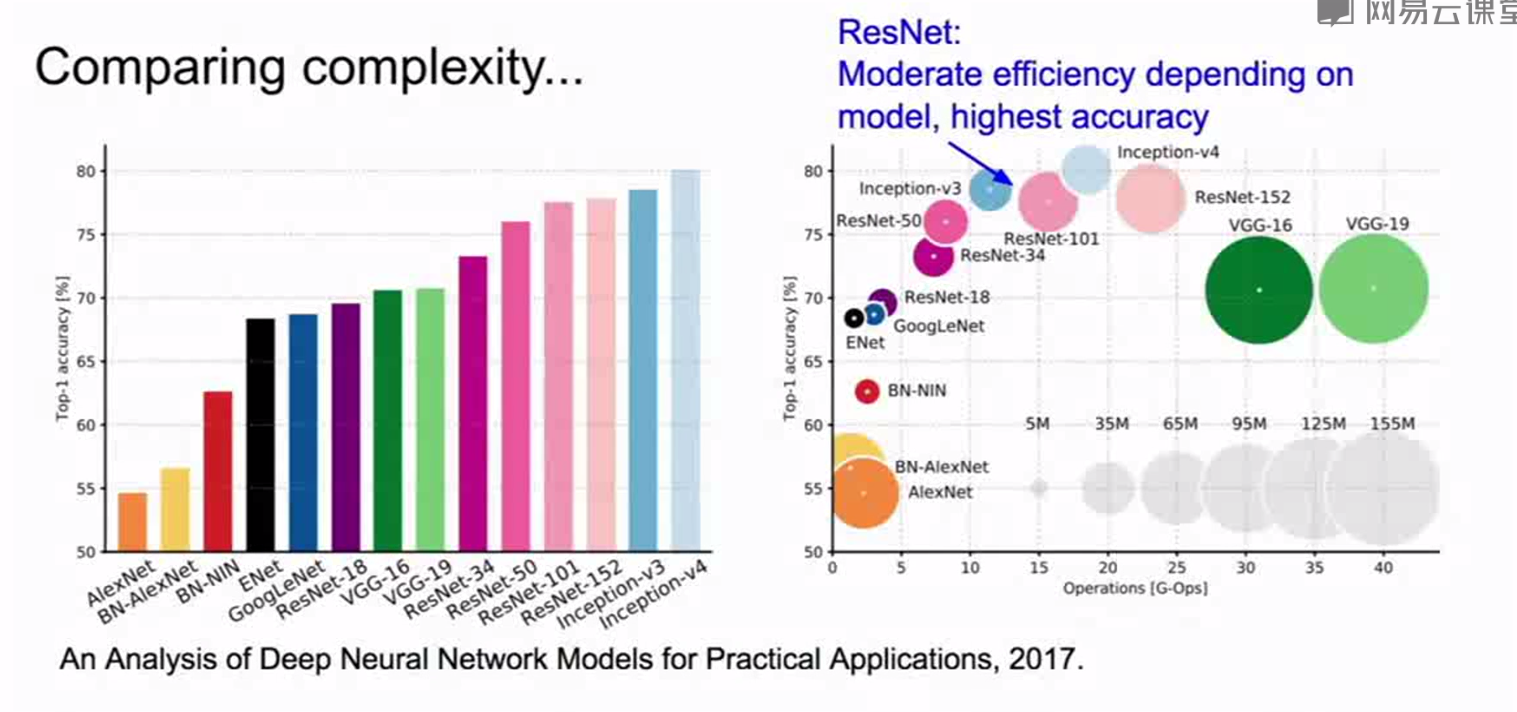
改进的残差:
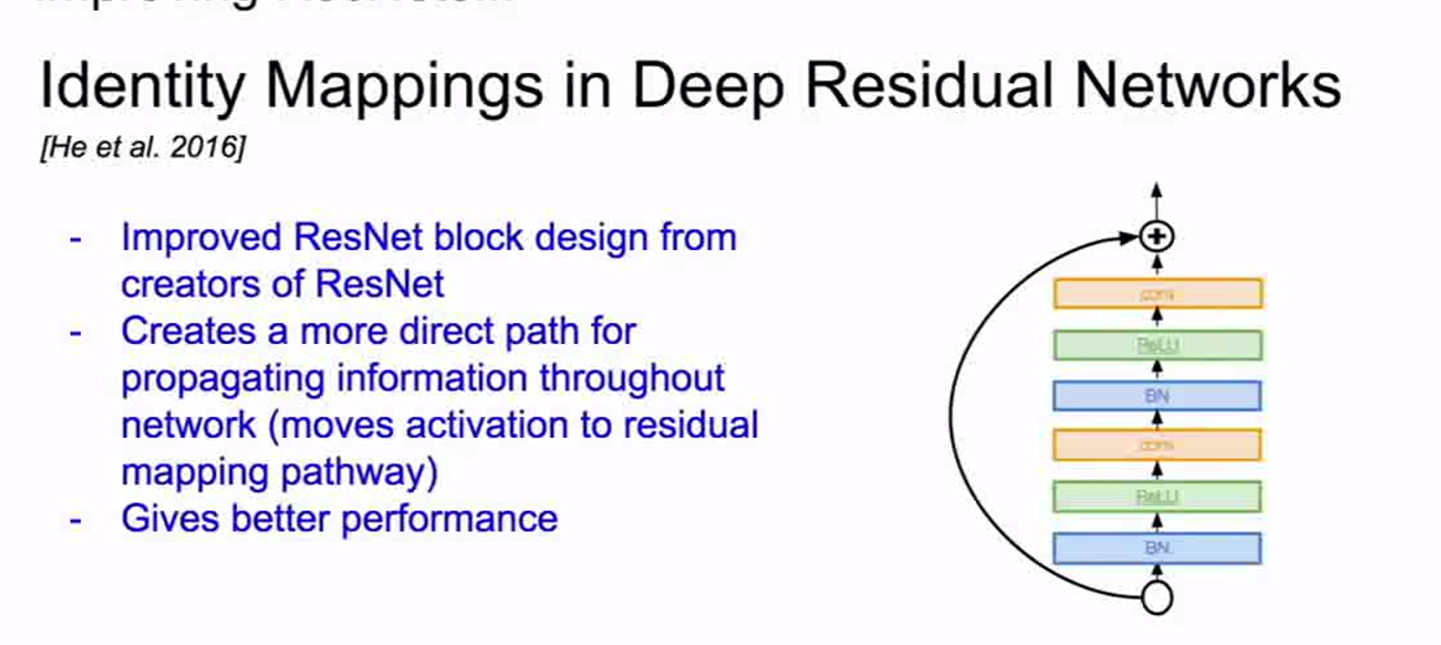
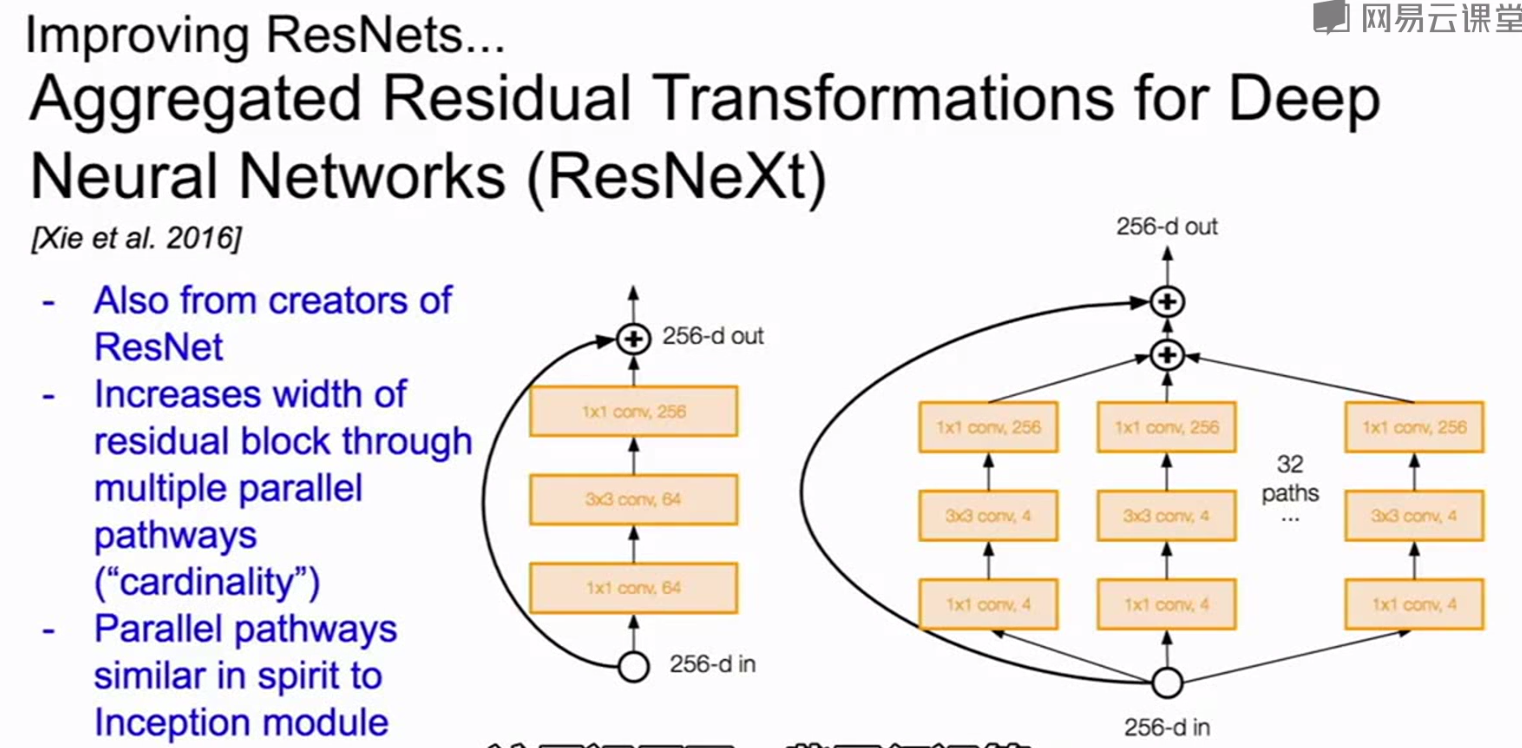

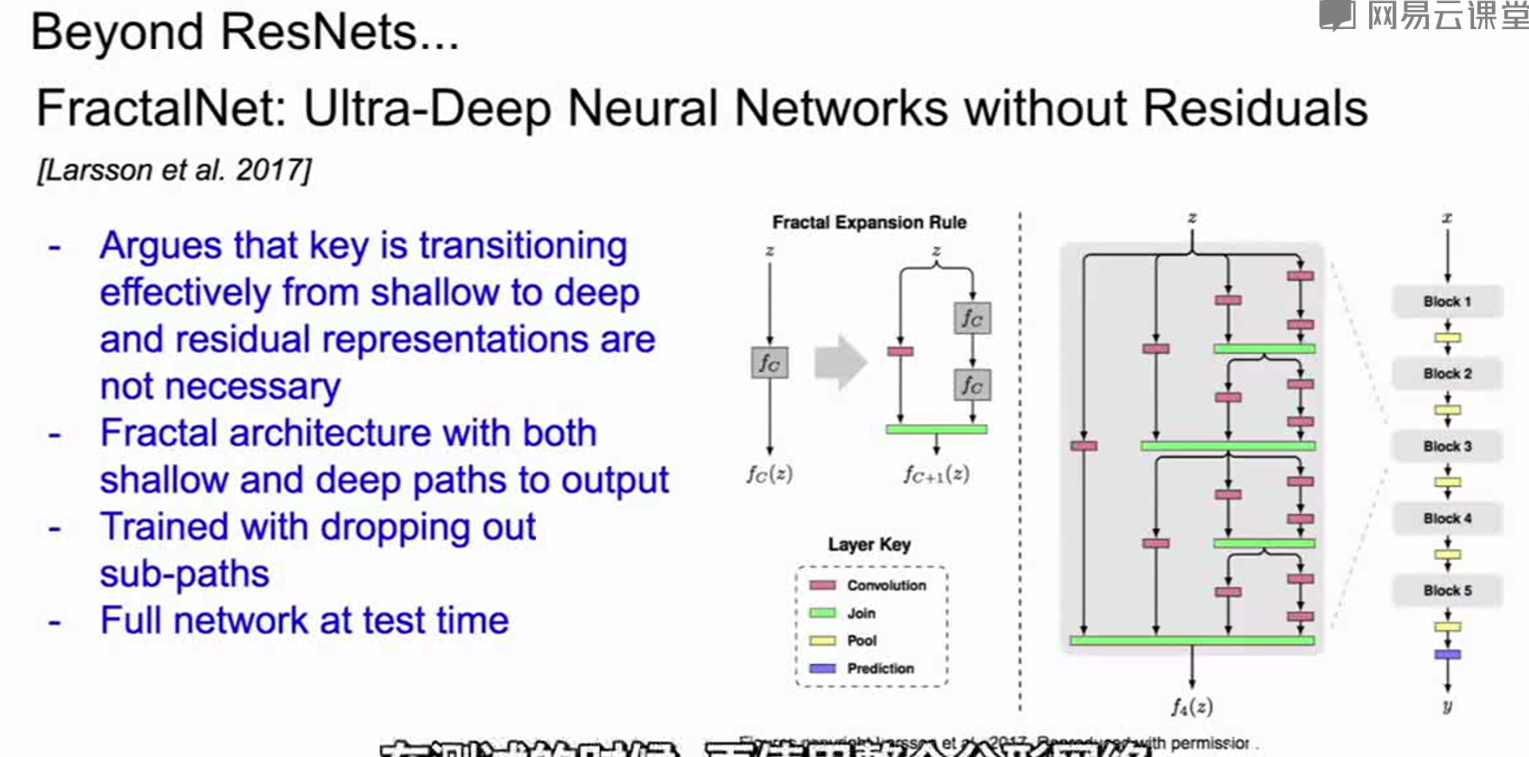
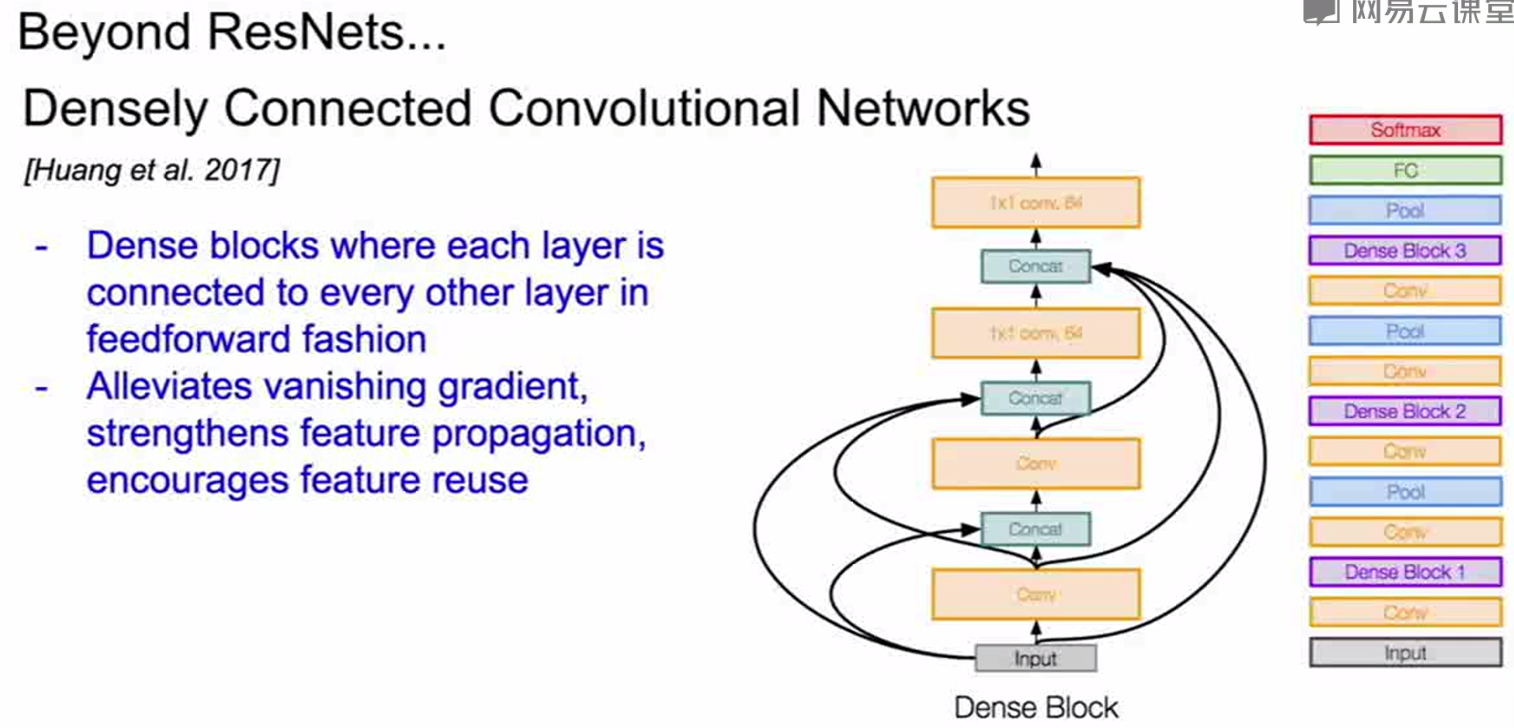
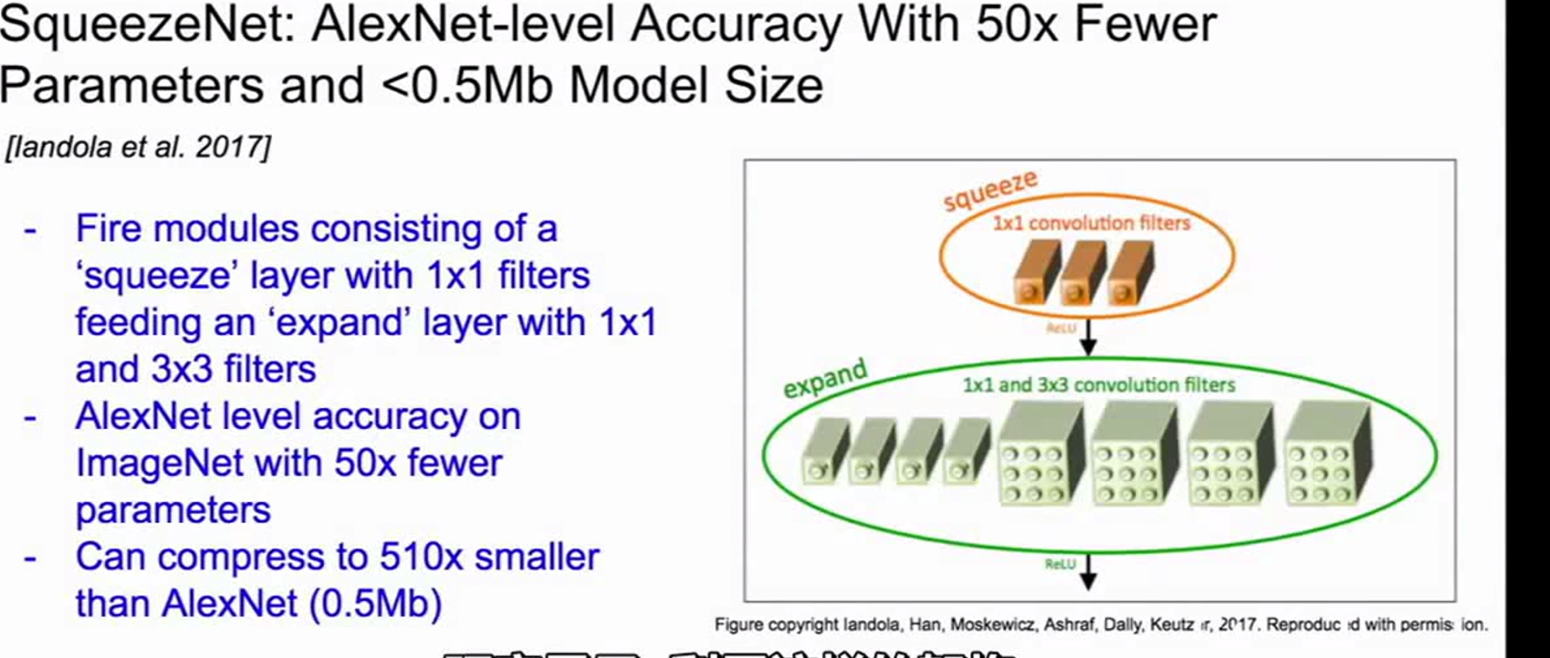
其他的网络:

1
AlexNet,VGG,GoogleNet,ResNet的更多相关文章
- CNN Architectures(AlexNet,VGG,GoogleNet,ResNet,DenseNet)
AlexNet (2012) The network had a very similar architecture as LeNet by Yann LeCun et al but was deep ...
- LeNet, AlexNet, VGGNet, GoogleNet, ResNet的网络结构
1. LeNet 2. AlexNet 3. 参考文献: 1. 经典卷积神经网络结构——LeNet-5.AlexNet.VGG-16 2. 初探Alexnet网络结构 3.
- #Deep Learning回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
CNN的发展史 上一篇回顾讲的是2006年Hinton他们的Science Paper,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服.当时有流传的段 ...
- (转)ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks
ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks by KO ...
- Deep Learning 经典网路回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
#Deep Learning回顾#之LeNet.AlexNet.GoogLeNet.VGG.ResNet 深入浅出——网络模型中Inception的作用与结构全解析 图像识别中的深度残差学习(Deep ...
- 经典深度学习CNN总结 - LeNet、AlexNet、GoogLeNet、VGG、ResNet
参考了: https://www.cnblogs.com/52machinelearning/p/5821591.html https://blog.csdn.net/qq_24695385/arti ...
- Deep Learning回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet - 我爱机器学习
http://www.cnblogs.com/52machinelearning/p/5821591.html
- 深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 关于卷积神经网络CNN,网络和文献中 ...
- L17 AlexNet VGG NiN GoogLeNet
深度卷积神经网络(AlexNet) LeNet: 在大的真实数据集上的表现并不尽如⼈意. 1.神经网络计算复杂. 2.还没有⼤量深⼊研究参数初始化和⾮凸优化算法等诸多领域. 机器学习的特征提取:手工定 ...
随机推荐
- python 文本文件的读取
- MaxCompute 图计算开发指南
快速入门step by step MaxCompute Studio 创建完成 MaxCompute Java Module后,即可以开始开发Graph了. 代码示例 在examples目录下有gra ...
- nginx设置301永久重定向
https://blog.csdn.net/wzqzhq/article/details/53376501 比如说我的域名有多个,一个主域名www.zq110.com,多个次域名:www.aaa.co ...
- python 列表索引
- @atcoder - AGC038F@ Two Permutations
目录 @description@ @solution@ @accepted code@ @details@ @description@ 给定 N 与两个 0~N-1 的置换 P, Q. 现在你需要找到 ...
- win10 子系统ubuntu中文乱码
### . 查看系统是否支持中文 locale -a ### . 如不支持需安装中文包 apt-get install language-pack-zh-hans -y ### . 添加中文支持 lo ...
- Knative 核心概念介绍:Build、Serving 和 Eventing 三大核心组件
Knative 主要由 Build.Serving 和 Eventing 三大核心组件构成.Knative 正是依靠这三个核心组件,驱动着 Knative 这艘 Serverless 巨轮前行.下面让 ...
- 我为什么飞行 10000 公里去西班牙参加 KubeCon?
2019 年 5 月 20 日至 23 日, 由 Cloud Native Computing Foundation (CNCF) 主办的云原生技术大会 KubeCon + CloudNativeCo ...
- Best Open Source Software
Best Open Source Software Open Source, Software, Top The promise of open source software is best qua ...
- H3C ISDN BRI和PRI