机器学习(ML)十四之凸优化
优化与深度学习
优化与估计
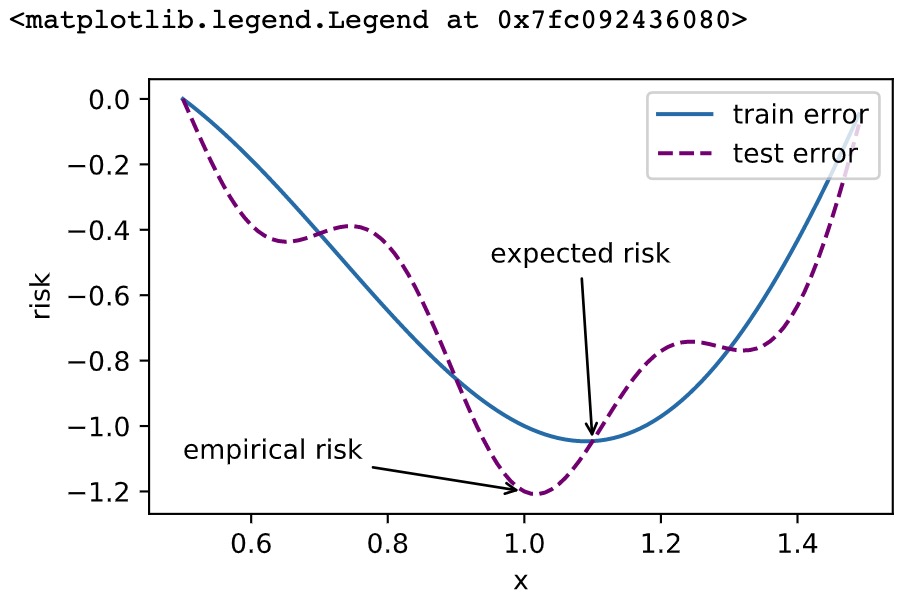
尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到的目标与深度学习的目标并不相同。
- 优化方法目标:训练集损失函数值
- 深度学习目标:测试集损失函数值(泛化性)
%matplotlib inline
import sys
import d2lzh1981 as d2l
from mpl_toolkits import mplot3d # 三维画图
import numpy as np
def f(x): return x * np.cos(np.pi * x)
def g(x): return f(x) + 0.2 * np.cos(5 * np.pi * x) d2l.set_figsize((5, 3))
x = np.arange(0.5, 1.5, 0.01)
fig_f, = d2l.plt.plot(x, f(x),label="train error")
fig_g, = d2l.plt.plot(x, g(x),'--', c='purple', label="test error")
fig_f.axes.annotate('empirical risk', (1.0, -1.2), (0.5, -1.1),arrowprops=dict(arrowstyle='->'))
fig_g.axes.annotate('expected risk', (1.1, -1.05), (0.95, -0.5),arrowprops=dict(arrowstyle='->'))
d2l.plt.xlabel('x')
d2l.plt.ylabel('risk')
d2l.plt.legend(loc="upper right")
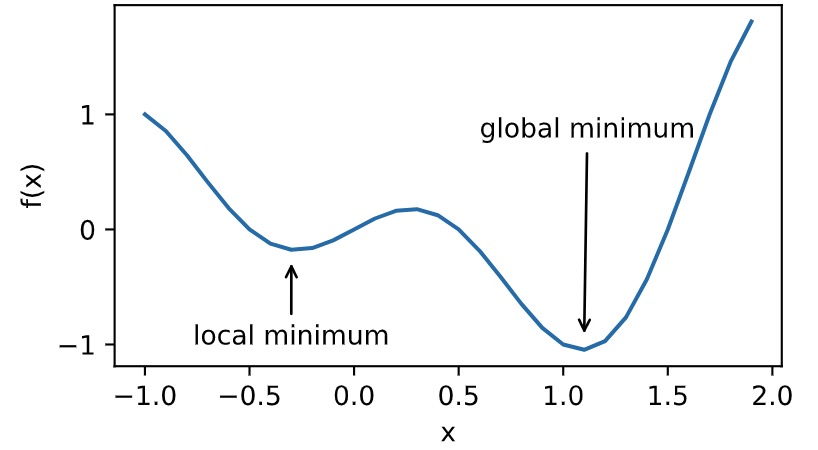
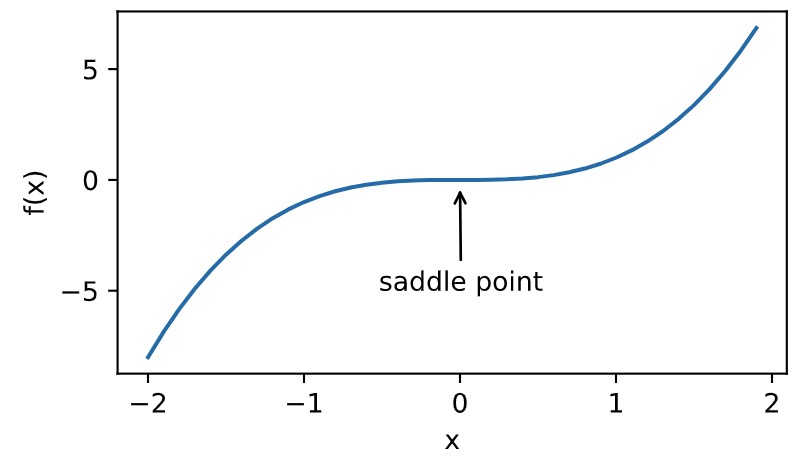
优化在深度学习中的挑战
- 局部最小值
- 鞍点
- 梯度消失
局部最小值

def f(x):
return x * np.cos(np.pi * x) d2l.set_figsize((4.5, 2.5))
x = np.arange(-1.0, 2.0, 0.1)
fig, = d2l.plt.plot(x, f(x))
fig.axes.annotate('local minimum', xy=(-0.3, -0.25), xytext=(-0.77, -1.0),
arrowprops=dict(arrowstyle='->'))
fig.axes.annotate('global minimum', xy=(1.1, -0.95), xytext=(0.6, 0.8),
arrowprops=dict(arrowstyle='->'))
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)');
鞍点
x = np.arange(-2.0, 2.0, 0.1)
fig, = d2l.plt.plot(x, x**3)
fig.axes.annotate('saddle point', xy=(0, -0.2), xytext=(-0.52, -5.0),
arrowprops=dict(arrowstyle='->'))
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)');
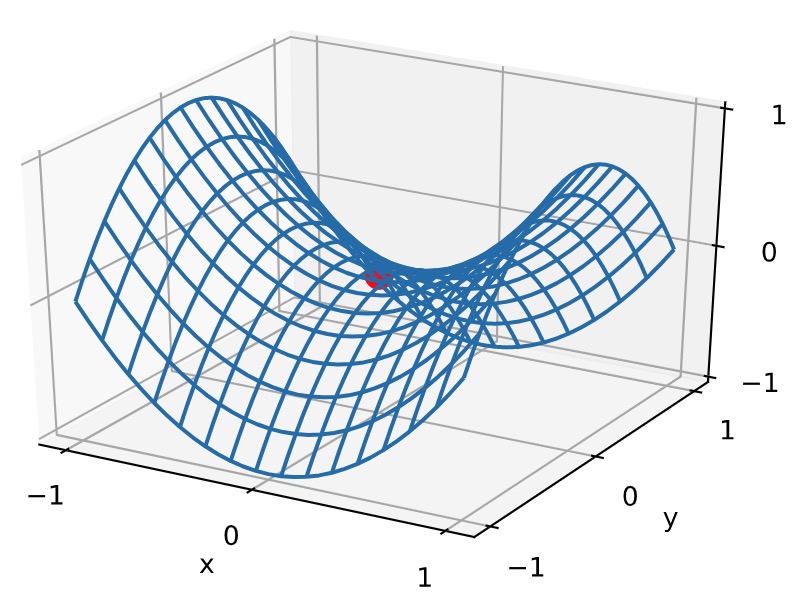
x, y = np.mgrid[-1: 1: 31j, -1: 1: 31j]
z = x**2 - y**2 d2l.set_figsize((6, 4))
ax = d2l.plt.figure().add_subplot(111, projection='3d')
ax.plot_wireframe(x, y, z, **{'rstride': 2, 'cstride': 2})
ax.plot([0], [0], [0], 'ro', markersize=10)
ticks = [-1, 0, 1]
d2l.plt.xticks(ticks)
d2l.plt.yticks(ticks)
ax.set_zticks(ticks)
d2l.plt.xlabel('x')
d2l.plt.ylabel('y');
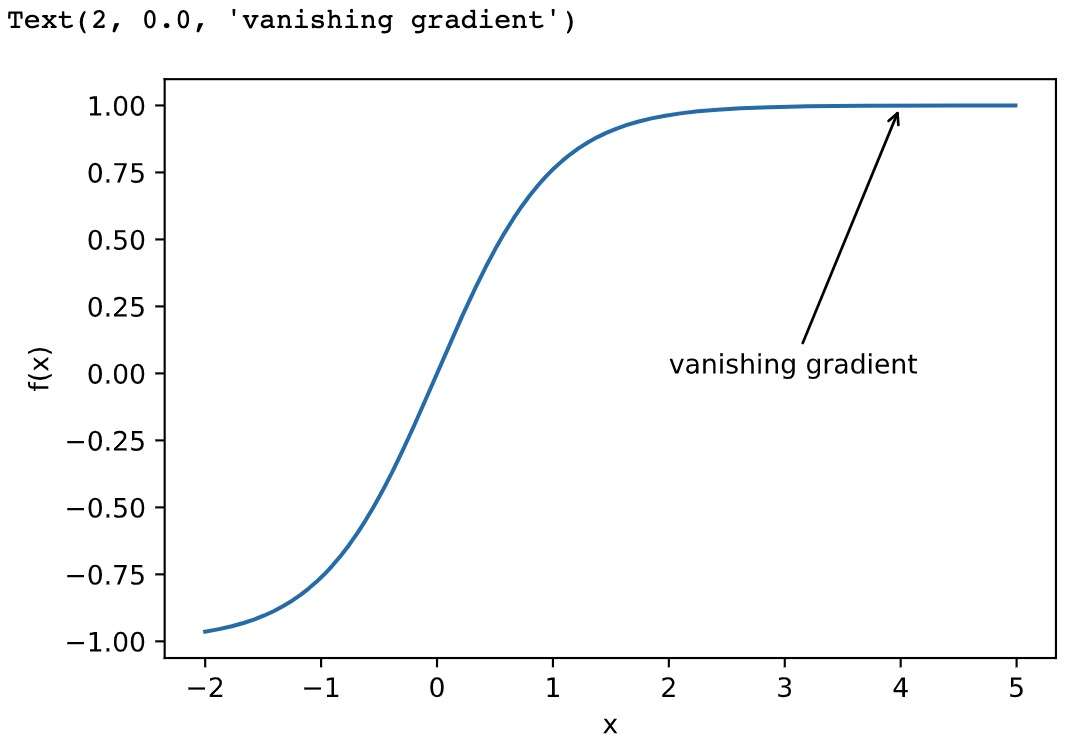
梯度消失
x = np.arange(-2.0, 5.0, 0.01)
fig, = d2l.plt.plot(x, np.tanh(x))
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)')
fig.axes.annotate('vanishing gradient', (4, 1), (2, 0.0) ,arrowprops=dict(arrowstyle='->'))
凸性 (Convexity)
基础
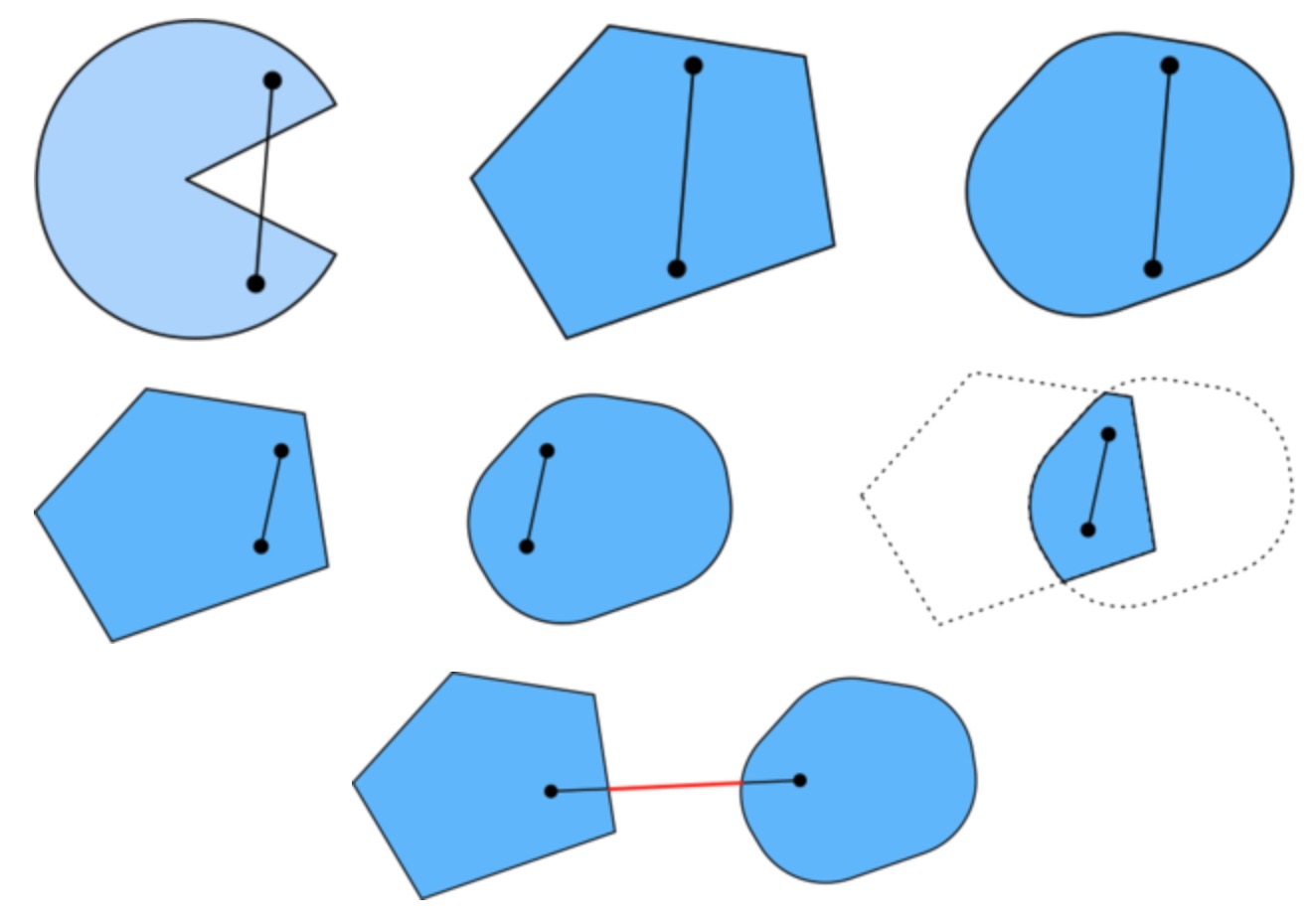
集合
函数
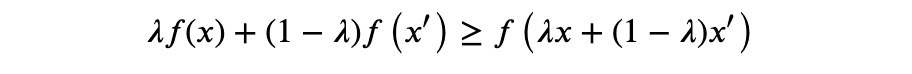
def f(x):
return 0.5 * x**2 # Convex def g(x):
return np.cos(np.pi * x) # Nonconvex def h(x):
return np.exp(0.5 * x) # Convex x, segment = np.arange(-2, 2, 0.01), np.array([-1.5, 1])
d2l.use_svg_display()
_, axes = d2l.plt.subplots(1, 3, figsize=(9, 3)) for ax, func in zip(axes, [f, g, h]):
ax.plot(x, func(x))
ax.plot(segment, func(segment),'--', color="purple")
# d2l.plt.plot([x, segment], [func(x), func(segment)], axes=ax)

Jensen 不等式
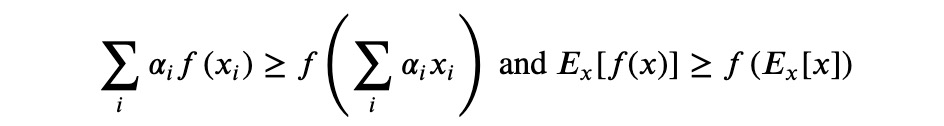
性质
- 无局部极小值
- 与凸集的关系
- 二阶条件
无局部最小值

与凸集的关系

x, y = np.meshgrid(np.linspace(-1, 1, 101), np.linspace(-1, 1, 101),
indexing='ij') z = x**2 + 0.5 * np.cos(2 * np.pi * y) # Plot the 3D surface
d2l.set_figsize((6, 4))
ax = d2l.plt.figure().add_subplot(111, projection='3d')
ax.plot_wireframe(x, y, z, **{'rstride': 10, 'cstride': 10})
ax.contour(x, y, z, offset=-1)
ax.set_zlim(-1, 1.5) # Adjust labels
for func in [d2l.plt.xticks, d2l.plt.yticks, ax.set_zticks]:
func([-1, 0, 1])
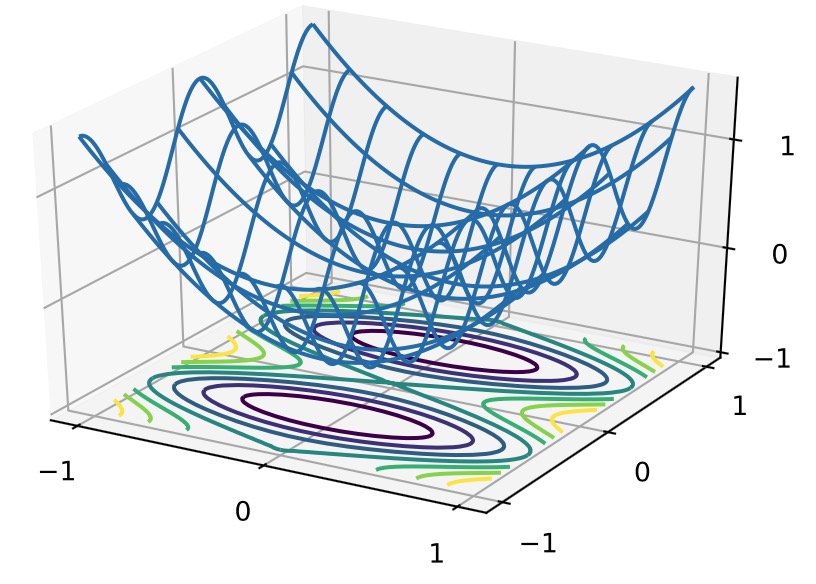
凸函数与二阶导数

def f(x):
return 0.5 * x**2 x = np.arange(-2, 2, 0.01)
axb, ab = np.array([-1.5, -0.5, 1]), np.array([-1.5, 1]) d2l.set_figsize((3.5, 2.5))
fig_x, = d2l.plt.plot(x, f(x))
fig_axb, = d2l.plt.plot(axb, f(axb), '-.',color="purple")
fig_ab, = d2l.plt.plot(ab, f(ab),'g-.') fig_x.axes.annotate('a', (-1.5, f(-1.5)), (-1.5, 1.5),arrowprops=dict(arrowstyle='->'))
fig_x.axes.annotate('b', (1, f(1)), (1, 1.5),arrowprops=dict(arrowstyle='->'))
fig_x.axes.annotate('x', (-0.5, f(-0.5)), (-1.5, f(-0.5)),arrowprops=dict(arrowstyle='->'))
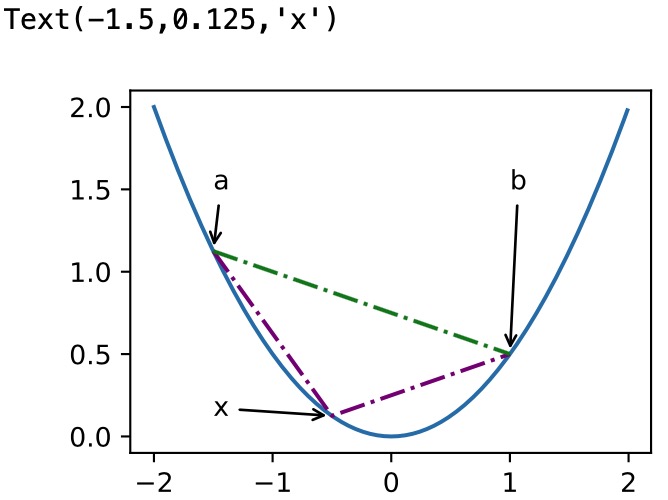
限制条件
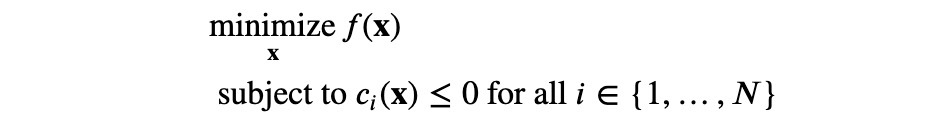
拉格朗日乘子法
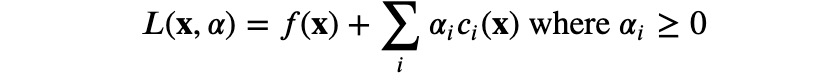
惩罚项

投影

机器学习(ML)十四之凸优化的更多相关文章
- Stanford机器学习---第十四讲.机器学习应用举例之Photo OCR
http://blog.csdn.net/l281865263/article/details/50278745 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归.Oc ...
- SIGAI机器学习第十四集 支持向量机1
讲授线性分类器,分类间隔,线性可分的支持向量机原问题与对偶问题,线性不可分的支持向量机原问题与对偶问题,核映射与核函数,多分类问题,libsvm的使用,实际应用 大纲: 支持向量机简介线性分类器分类间 ...
- 【转】机器学习教程 十四-利用tensorflow做手写数字识别
模式识别领域应用机器学习的场景非常多,手写识别就是其中一种,最简单的数字识别是一个多类分类问题,我们借这个多类分类问题来介绍一下google最新开源的tensorflow框架,后面深度学习的内容都会基 ...
- Redis教程(十四):内存优化介绍
转载于:http://www.itxuexiwang.com/a/shujukujishu/redis/2016/0216/142.html 一.特殊编码: 自从Redis 2.2之后,很多数据类型都 ...
- SIGAI机器学习第二十四集 聚类算法1
讲授聚类算法的基本概念,算法的分类,层次聚类,K均值算法,EM算法,DBSCAN算法,OPTICS算法,mean shift算法,谱聚类算法,实际应用. 大纲: 聚类问题简介聚类算法的分类层次聚类算法 ...
- JMeter学习(三十四)测试报告优化
如果按JMeter默认设置,生成报告如下: 从上图可以看出,结果信息比较简单,对于运行成功的case,还可以将就用着.但对于跑失败的case,就只有一行assert错误信息.(信息量太少了,比较难找到 ...
- 机器学习(十四)— kMeans算法
参考文献:https://www.jianshu.com/p/5314834f9f8e # -*- coding: utf-8 -*- """ Created on Mo ...
- 猪猪的机器学习笔记(十四)EM算法
EM算法 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十次次课在线笔记.EM算法全称为Expectation Maximization Algorithm,既最大 ...
- 只需十四步:从零开始掌握 Python 机器学习(附资源)
分享一篇来自机器之心的文章.关于机器学习的起步,讲的还是很清楚的.原文链接在:只需十四步:从零开始掌握Python机器学习(附资源) Python 可以说是现在最流行的机器学习语言,而且你也能在网上找 ...
随机推荐
- MySQL数据库保存emoji表情
何为emoji表情?这里的全是. MySQL数据库为什么不能存储emoji?不是MySQL不能,而是MySQL的utf8编码不能!原来MySQL下的utf8编码每个字符占3个字节,而emoji占4个字 ...
- Spring Cloud(一):服务注册中心Eureka
Spring Cloud 基于 Netflix 的几个开源项目进行了封装,提供包括服务注册与发现(Eureka),智能路由(Zuul),熔断器(Hystrix),客户端负载均衡(Ribbon)等在内的 ...
- 清晰架构(Clean Architecture)的Go微服务: 依赖注入(Dependency Injection)
在清晰架构(Clean Architecture)中,应用程序的每一层(用例,数据服务和域模型)仅依赖于其他层的接口而不是具体类型. 在运行时,程序容器¹负责创建具体类型并将它们注入到每个函数中,它使 ...
- js中如何将伪数组转换成数组
伪数组:不能调用数组的方法, 1.对象是按索引方式存储数据的 2.它具备length属性 {0:'a',1:'b',length:2} //es5伪数组转换成数组 let args = [].slic ...
- USACO简介导论
1000: USACO简介 时间限制: 1 Sec 内存限制: 128 MB提交: 8 解决: 7[提交] [状态] [讨论版] [命题人:外部导入] 题目描述 来源/分类 USACO-00 ...
- spring注入相关注解
本次主要整理四个注解 @ComponentScan.@Scope.@Conditional.@Import 1. @ComponentScan(value = "com.xiaoguo&qu ...
- dp-完全背包
( 推荐 : http://blog.csdn.net/insistgogo/article/details/11081025 ) 问题描述 : 已知一个容量为 V 的背包 和 N 件物品 , 第 ...
- java 大数的学习
import java.math.*; import java.util.*; public class study { public static void main(String[] args) ...
- 死磕面试 - Dubbo基础知识37问(必须掌握)
作为一个JAVA工程师,出去项目拿20k薪资以上,dubbo绝对是面试必问的,即使你对dubbo在项目架构上的作用不了解,但dubbo的基础知识也必须掌握. 整理分享一些面试中常会被问到的dubbo基 ...
- Java并发关键字Volatile 详解
Java并发关键字Volatile 详解 问题引出: 1.Volatile是什么? 2.Volatile有哪些特性? 3.Volatile每个特性的底层实现原理是什么? 相关内容补充: 缓存一致性协议 ...