监控自己的电脑浏览器访问记录并生成csv格式
#!usr/bin/env python
#-*- coding:utf-8 _*-
"""
@author:lenovo
@file: 获取浏览器历史记录.py
@time: 2019/11/04
"""
import os
import sqlite3
import shutil
import datetime
import pandas as pd
'''
last_visit_time => 起始值:1601年1月1日0时0分0秒 11644473600
print(13216100327877073/10**6-11644473600)
'''
dbpath = r"C:\Users\lenovo\AppData\Local\Google\Chrome\User Data\Default\history"
'''这里我复制一个出来重新命名'''
historydb = shutil.copy(dbpath,r"C:\\Users\\lenovo\AppData\\Local\\Google\\Chrome\\User Data\\Default\\history1")
#查询数据库类容
conn = sqlite3.connect(historydb)
cursor = conn.cursor()
sql = "select url,visit_count,last_visit_time from urls "
cursor.execute(sql)
results = cursor.fetchall()
#print(type(results),results)
ur,vi,tim = [],[],[]
for i in results:
ur.append(i[0])
visit_count = i[1]
vi.append(visit_count)
un_time = round(i[2]/10**6-11644473600)
times = datetime.datetime.fromtimestamp(un_time)
tim.append(times)
# 创建数据表
house = pd.DataFrame({'网址': ur, '浏览次数': vi, '浏览时间': tim})
# 查看数据表的内容
house.head()
house.to_csv('本地谷歌浏览记录.csv', encoding='gbk')
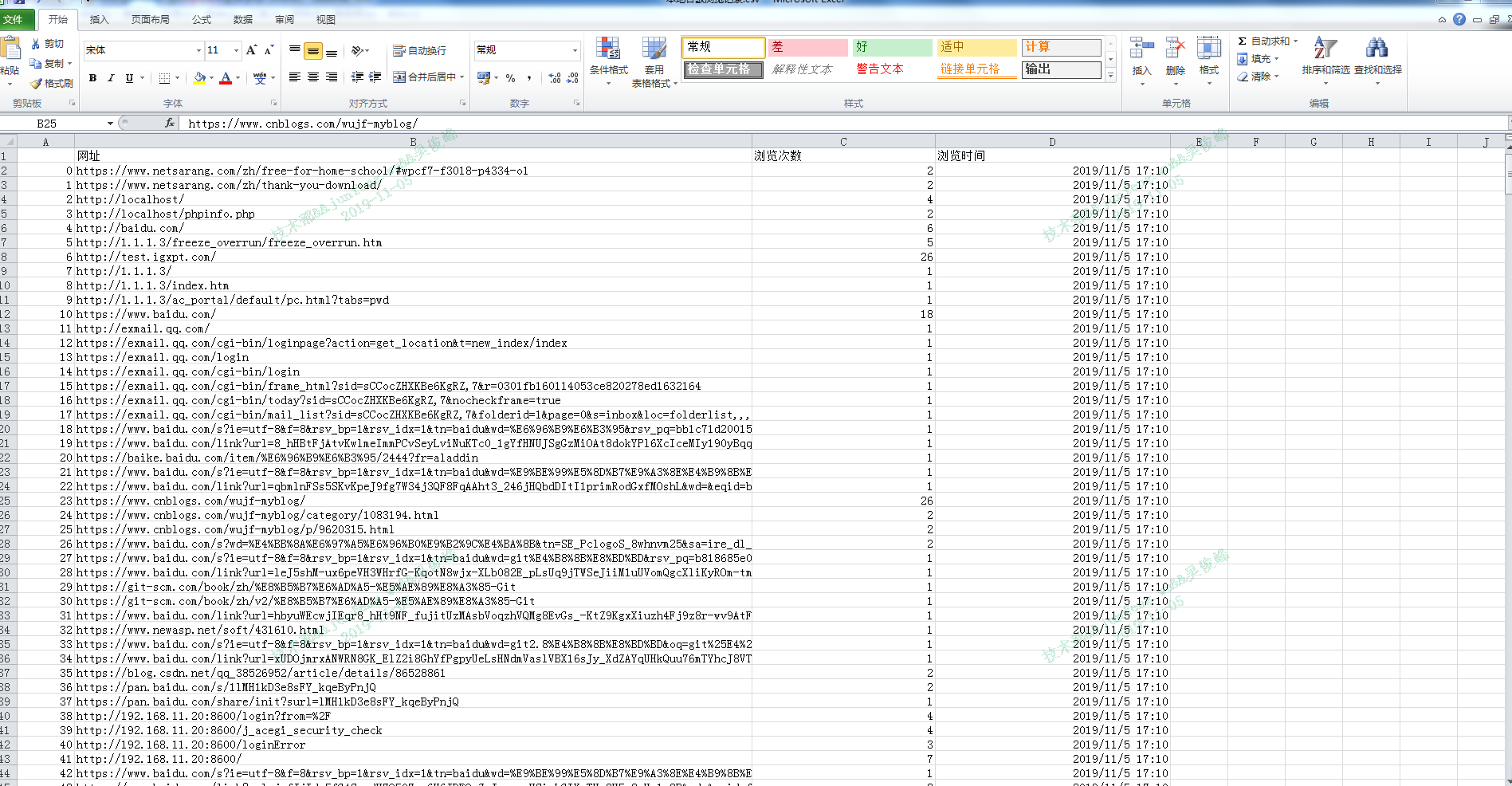
最后得到结果:
监控自己的电脑浏览器访问记录并生成csv格式的更多相关文章
- 我用python远程探查女友每天的网页访问记录,她不愧是成年人!
利用Python制作远程查看别人电脑的操作记录,与其它教程类似,都是通过邮件返回. 利用程序得到目标电脑浏览器当中的访问记录,生产一个文本并发送到你自己的邮箱,当然这个整个过程除了你把python程序 ...
- 用chrome模拟微信浏览器访问需要OAuth2.0网页授权的页面
现在很流行微信网页小游戏,用html5制作的小游戏移过来,可以放到微信浏览器中打开,关键是可以做成微信分享朋友圈的形式,大大提高游戏的传播,增强好友的游戏互动. 微信浏览器中打开网页游戏效果还不错,对 ...
- Nodejs一键实现微信内打开网页url自动跳转外部浏览器访问的功能
前言 现如今微信对第三方推广链接的审核是越来越严格了,域名在微信中分享转发经常会被拦截,一旦被拦截用户就只能复制链接手动打开浏览器粘贴才能访问,要不然就是换个域名再推,周而复始.无论是哪一种情况都会面 ...
- 微信最新跳转浏览器功能源码,实现微信内跳转手机浏览器访问网页url
微信最新自动跳转外部浏览器下载app/打开指定页面源码 源码说明: 适用安卓和苹果系统,支持任何网页链接.并且无论链接是否已经被微信拦截,均可实现微信内自动跳转浏览器打开. 生成的跳转链接具有极佳的防 ...
- Selenium 3 + BrowserMobProxy 2.1.4 模拟浏览器访问 (含趟坑)
背景 Selenium 是一个Web自动化测试的组件,可基于WebDriver去控制弹出浏览器去做一系列Web点击或行为测试(当然也可以去做一些邪恶的事..),减少重复人工网页测试的开销.Browse ...
- [转]用chrome模拟微信浏览器访问需要OAuth2.0网页授权的页面
FROM : http://blog.csdn.net/gavin_luo/article/details/40620217 现在很流行微信网页小游戏,用html5制作的小游戏移过来,可以放到微信浏览 ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- java学习笔记—使用HttpSession实现QQ的访问记录(31)
1. 编写QQ空间数据类(QQS.java) public class QQS { private static LinkedHashMap<Integer, String> qqs = ...
- 苹果手机通过Safari浏览器访问web方式安装In-House应用
需求背景 公司内部员工使用的iOS客户端应用希望对内开放,不需要发布于AppStore直接能够让内部用户获取,对于Android应用来说这个问题很好解决,直接下发安装包然后就能安装了:但是对于苹果生态 ...
随机推荐
- python笔记16
1.今日内容 模块基础知识 time/datetime json/picle shutil logging 其他 2.内容回顾和补充 2.1模块(类库) 内置 第三方 自定义 面试题: 列举常用内置模 ...
- C语言关于getchar()的小笔记
#include <windows.h> #include <mmsystem.h> #include <string.h> void main() { int a ...
- 题解 SDOI2010 【栗栗的书架】
\[ Preface \] 看到这题洛谷标签有 主席树 ,还以为是什么二维主席树的玄学做法(雾 \[ Description \] 给出一个 \(R×C\) 的矩阵. 一共 \(m\) 次询问,每次询 ...
- Ambari HDP 下 SPARK2 与 Phoenix 整合
1.环境说明 操作系统 CentOS Linux release 7.4.1708 (Core) Ambari 2.6.x HDP 2.6.3.0 Spark 2.x Phoenix 4.10.0-H ...
- Part1-解线性方程组
自己一边听课一边记得,参考网上广为流传的那本<MIT线性代数笔记>,转成Latex上传太麻烦,直接截图上传了,需要电子版的可以私信我.
- Python3(十一) 原生爬虫
一.爬虫实例 1.原理:文本分析并提取信息——正则表达式. 2.实例目的:爬取熊猫TV某个分类下面主播的人气排行 分析网站结构 操作:F12查看HTML信息,Ctrl+Shift+C鼠标选取后找到对应 ...
- ajax 解决中文乱码问题
最近遇到了ajax 中文乱码的问题.下面总结一下 1. HTTP协议的编码规定 在HTTP协议中,浏览器不能向服务器直接传递某些特殊字符,必须是这些字符进行URL编码后再进行传送.url编码遵循的规则 ...
- 17-SSM中通过pagehelper分页的实现
SSM中通过pagehelper分页的实现 1. 在SSM框架的基础上实现,导包 <!-- 分页 --> <dependency> <groupId>com.git ...
- ls-remote -h -t git://github.com/adobe-webplatform/eve.git
npm WARN deprecated bfj-node4@5.3.1: Switch to the `bfj` package for fixes and new features! npm WAR ...
- php面试笔记(4)-php基础知识-流程控制
本文是根据慕课网Jason老师的课程进行的PHP面试知识点总结和升华,如有侵权请联系我进行删除,email:guoyugygy@163.com 在面试中,考官往往喜欢基础扎实的面试者,而流程控制相关的 ...