Elasticsearch配置集群环境
环境选择:
1.方案一:准备三台机器 每一台机器一个节点
2.方案二:准备一台机器 启动三个节点,用端口号区分即可
3.ES启动依赖于JVM环境 每一个节点默认使用2G内存,可以找到配置文件jvm配置文件修改内存
4.搭建ES集群时,保证每一个节点都是没有数据的
环境搭建:
步骤一:准备一个ES节点,加入基本配置:跨域 加入IK分析器
步骤二:配置节点的es.yml配置文件
#节点1的配置信息:
#集群名称,保证唯一 每一个节点都是相同的集群名称
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-1
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9200
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9300
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
步骤三:复制刚才的节点环境,更改文件夹名称以及es.yml配置文件
##集群环境
#节点1的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-2
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
步骤四:复制刚才的节点环境,更改文件夹名称以及es.yml配置文件
##集群环境
#节点1的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#节点名称,必须不一样
node.name: node-3
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
步骤五:依次启动集群
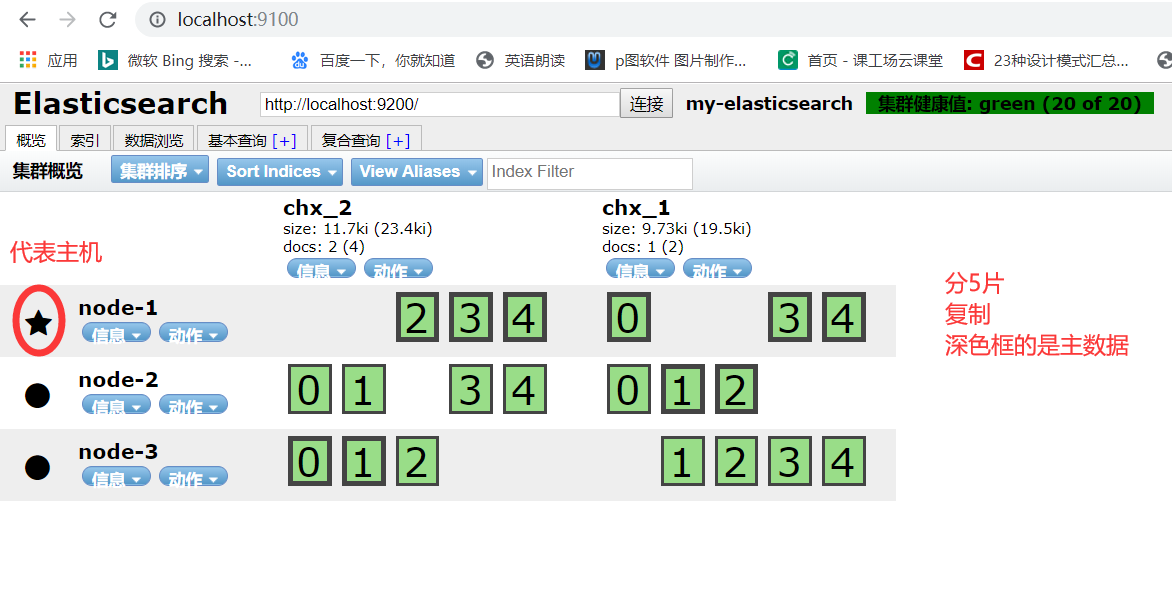
Elasticsearch配置集群环境的更多相关文章
- RocketMQ的安装配置:配置jdk环境,配置RocketMQ环境,配置集群环境,配置rocketmq-console
RocketMQ的安装配置 演示虚拟机环境:Centos64-1 (D:\linuxMore\centos6_64) root / itcast : 固定IP 192.168.52.128 一,配置J ...
- Zookeeper 配置集群环境详解
在Linux环境下安装zookeeper 在Linux环境下安装zookeeper 1. 将zookeeper-3.4.13.tar.gz复制到linux操作系统 2. 通过p ...
- elasticsearch配置集群+elk报错总结
配置ELK的时候,我平常遇到了以下几种报错情况,整理如下(持续更新中): elasticsearch启动失败 # systemctl start elasticsearch Job for elast ...
- 微服务:Eureka配置集群环境
一.注册中心编码 1.使用idea创建一个spring boot项目,pom如下: <?xml version="1.0" encoding="UTF-8" ...
- 使用Docker搭建Elasticsearch集群环境
本篇文章首发于头条号单机如何搭建Elasticsearch集群?使用容器技术快速构建集群环境,欢迎关注头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_te ...
- 【redis】 linux 下redis 集群环境搭建
Redis集群 (要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下) 127.0.0.1:63791 ...
- Win7下无法提交MapReduce Job到集群环境(转)
一. 对hadoop eclipse plugin认识不足 http://zy19982004.iteye.com/blog/2024467曾经说到我最hadoop eclipse plugin作用的 ...
- elasticsearch与mongodb分布式集群环境下数据同步
1.ElasticSearch是什么 ElasticSearch 是一个基于Lucene构建的开源.分布式,RESTful搜索引擎.它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索 ...
- ElasticSearch高可用集群环境搭建和分片原理
1.ES是如何实现分布式高并发全文检索 2.简单介绍ES分片Shards分片技术 3.为什么ES主分片对应的备分片不在同一台节点存放 4.索引的主分片定义好后为什么不能做修改 5.ES如何实现高可用容 ...
随机推荐
- MySQL会话控制限制登录次数
前言 一般我们开发环境的MySQL是没有配置登录保护的,但仅限于开发环境,正式环境是不允许无限制登录,存在很大的风险. MySQL 5.7 以后提供了Connection-Contro ...
- oracle11G 已开启监听,但远程连接依旧无监听解决过程
1.连接数据库显示无监听程序,首先查看服务器的oracle监听服务是否开启,服务名称:OracleOraDb11g_home1TNSListener(具体环境中可能不完全一样,但是认准TNSListe ...
- uml-类图书写指南
说明 类图是最常用的UML图,面向对象建模的主要组成部分.它用于描述系统的结构化设计,显示出类.接口以及它们之间的静态结构和关系. 类图主要产出于面向对象设计的分析和设计阶段,用来描述系统的静态结构. ...
- 实验6:路由器IOS升级
路由器IOS升级 Cisco路由器IOS映像恢复及升级方法 一.Cisco 1000,1600,2500,4000系列 1.IOS映像恢复的方法及步骤 1) 连接PC的COM1口与路由器的consol ...
- Bayesian Non-Exhaustive Classification A case study:online name disambiguation using temporal record streams
一 摘要: name entity disambiguation:将对应多个人的记录进行分组,使得每个组的记录对应一个人. 现有的方法多为批处理方式,需要将所有的记录输入给算法. 现实环境需要1:以o ...
- CCF_201403-1_相反数
按绝对值排序,因为没相同的数,直接遍历比较一遍即可. #include<iostream> #include<cstdio> #include<algorithm> ...
- 真正解决百度编辑器UEditor上传图片跨域问题
做前后端分离的项目用到UEditor,把上传图片程序拿出来放到了接口程序中,上传图片接口已经做了跨域处理,按理说编辑器中上传图片应该不会有问题.可是配置好图片上传路径后,运行,打开调试,测试一下,报错 ...
- Deeplab
Deeplab系列是谷歌团队的分割网络. DeepLab V1 CNN处理图像分割的两个问题 下采样导致信息丢失 maxpool造成feature map尺寸减小,细节信息丢失. 空间不变性 所谓空间 ...
- Go语言实现:【剑指offer】题目汇总
所列题目与牛客网<剑指offer>专题相对应. 数组: 和为S的两个数字 和为S的连续正数序列 连续子数组的最大和 数字在排序数组中出现的次数 数组中只出现一次的数字 旋转数组的最小数字 ...
- 【CMake】CMake ERROR:could not find git for clone of
在使用 CMake 构建VS2015项目时遇到一个错误提示:could not find git for clone of. 因为项目需要从GitHub导入运行库,但构建项目时提示未能找到这个库,而g ...