PostgreSQL内核学习笔记十一(索引)
Index Scan涉及到两部分的内容Heap Only Tuple和index-only-scan。
什么是Heap Only Tuple(HOT)?
例如:Update a Row Without HOT
testdb=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
data | text | | |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)
假设更新一条数据
testdb=# UPDATE tbl SET data = 'B' WHERE id = 1000;
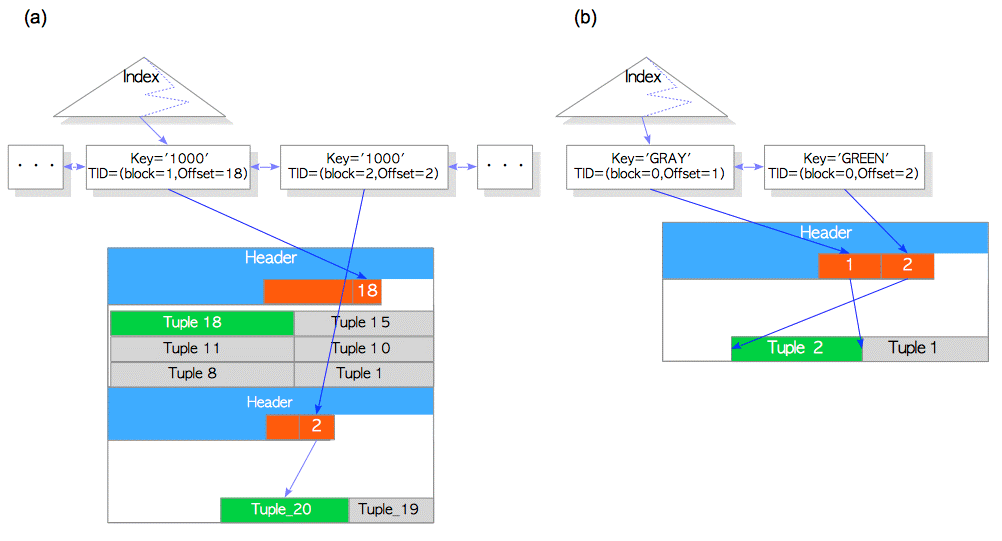
如果没有HOT机制,则不仅仅增加一个新的元组Tuple2,而且还增加了一个Index元组,如下图所示
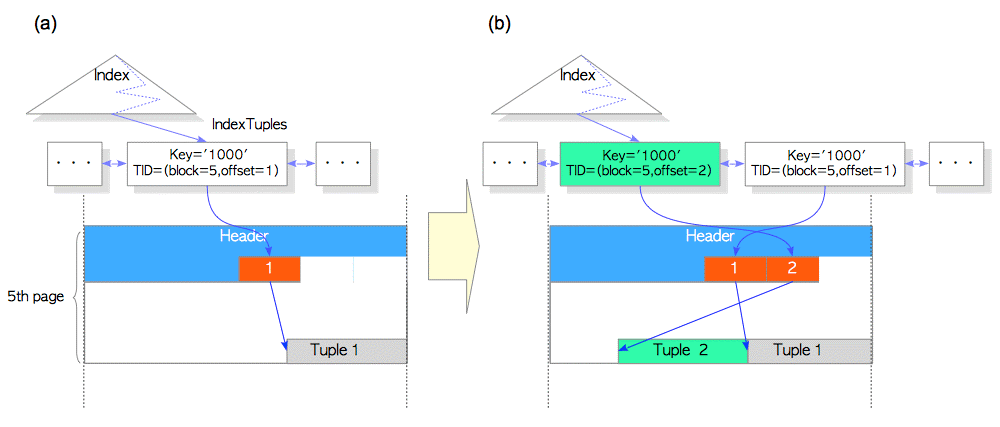
如果Update a Row With HOT,那么更新后会怎样?
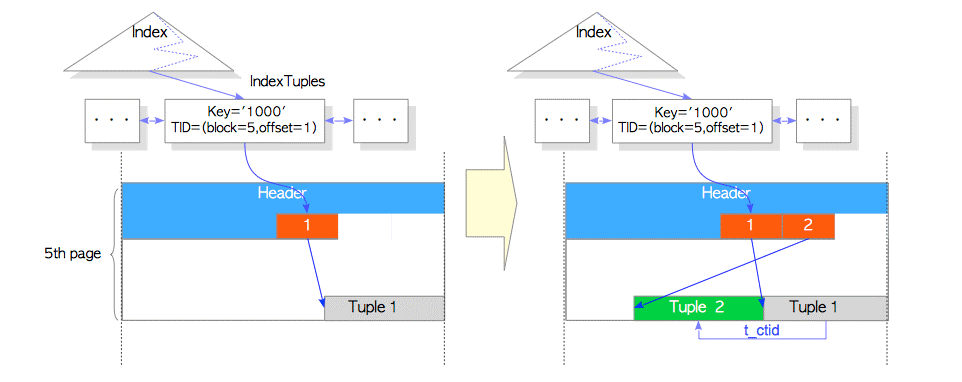
根据上图仅仅增加一个新的元组Tuple2。
同时Tuple1被设置了HEAP_HOT_UPDATED, Tuple2被设置了HEAP_ONLY_TUPLE.
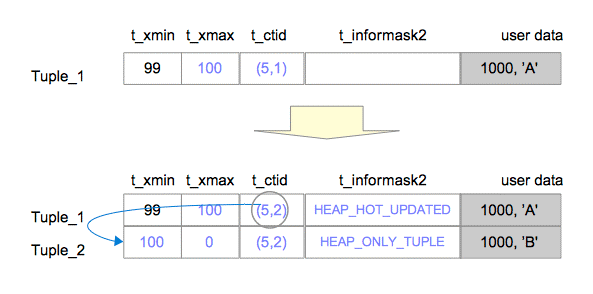
更新后数据是怎么通过Index检索到的?
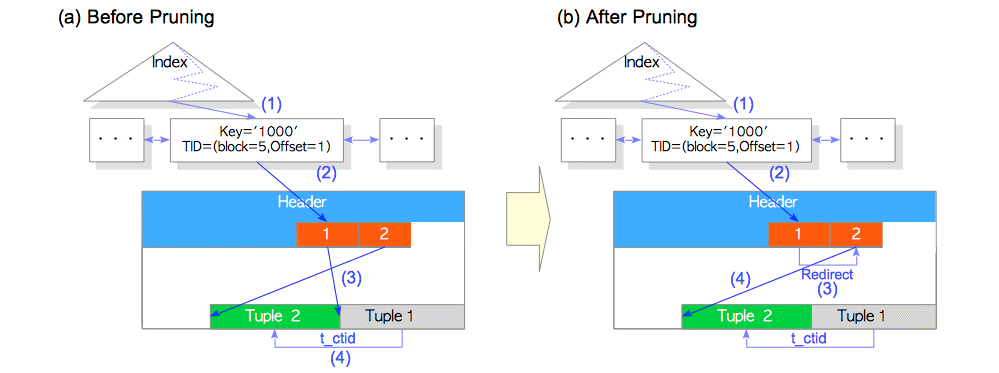
根据图(a)Before Pruning ,通过Index找到Tuple1,再根据Tuple1中的t_ctid找到Tupe2。此时会读取到两个元组Tuple1和Tuple2,根据MVCC机制决定读取Tupel1还是Tuple2.
上述的查找过程会带来问题:如果dead Tuple被删除了如:Tuple1,此时通过index就无法找到Tuple2.
为了解决这个问题,在合适的时候,PostgreSQL会像图(b)After Pruning中所示的现将Header中“1”指向“2”,再将“2”指向Tuple2. 这就被称为“Pruning”。
具体的执行时间可参考
https://github.com/postgres/postgres/blob/master/src/backend/access/heap/README.HOT
SELECT, UPDATE, INSERT and DELETE文被执行的时候,会进行pruning 处理。
![avatar]https://img2018.cnblogs.com/blog/1922961/202001/1922961-20200117160110815-2048897544.png)
在适当的时候,PostgreSQL会删除dead Tuple。PostgreSQL中被称为“Defragmentation”
注意:Defragmentation 的花费比VACUUM的花费要小,因为Defragmentation处理并不删除Index Tuple
{kind=link}
下面的两个场景不适用于HOT
(1) 更新的元组和旧的原组不在一个page上,比如下图的图a此时需要增加一个新的Index Tuple指向新的Tuple
(2) 如果Index值被更新了,这时需在Index page中新增一个Index Tuple
HOT相关的统计信息可参考统计表pg_stat_all_tables
什么是Index-Only Scan?
为了降低I/O(Input/Output)的花费,当SELECT的目标列就是index 列时,直接使用Index key不去使用Table page。
例如下表
testdb=# \d tbl
Table "public.tbl"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
name | text |
data | text |
Indexes:
"tbl_idx" btree (id, name)
表中已经插入的两个元组:
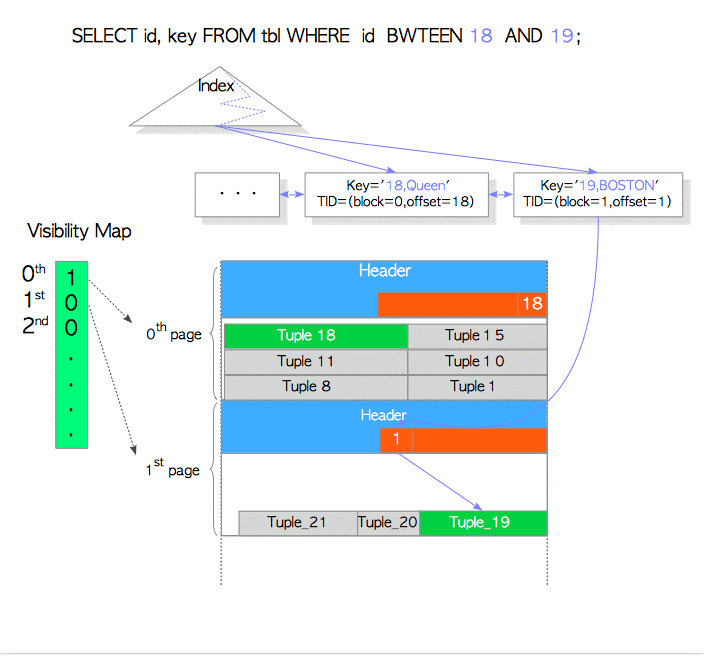
‘Tuple_18’, id的值是 ‘18’,name 的值是 ‘Queen’,这个元组存储在第0个 page.
‘Tuple_19’, id的值是‘19’, name 的值是 ‘BOSTON’, 这个元组存储在第1个 page
执行下面的SELECT文
testdb=# SELECT id, name FROM tbl WHERE id BETWEEN 18 and 19;
id | name
----+--------
18 | Queen
19 | Boston
(2 rows)
具体的过程如下:
这个查询要获取id, name这两列的值,并且"tbl_idx"是由这两列组成的。所以使用index scan。
咋看下是不需要获取table page的,因为index tuple已经包含需要的值了。
但是由于PostgreSQL还需要check元组的可见性visibility,index tuple中并不含有可见性visibility的信息(heap Tuple中才有的t_xmin and t_xmax 信息)。所以PostgreSQL不得不去使用table data。
为了解决这个问题,PostgreSQL使用了visibility map记录表的可见性,如下图。
如果所有tuple存储的page是可见的,PostgreSQL就直使用index key不去使用table page。否则的话,就去读table page检查其可见性。
在本例中Tuple_18直接使用index key,Tuple_19则需要使用table page检查其可见性。
参考资料:http://www.interdb.jp/pg/pgsql07.html
PostgreSQL内核学习笔记十一(索引)的更多相关文章
- PostgreSQL内核学习笔记四(SQL引擎)
PostgreSQL实现了SQL Standard2011的大部分内容,SQL处理是数据库中非常复杂的一部分内容. 本文简要介绍了SQL处理的相关内容. 简要介绍 SQL文的处理分为以下几个部分: P ...
- EPROCESS 进程/线程优先级 句柄表 GDT LDT 页表 《寒江独钓》内核学习笔记(2)
在学习笔记(1)中,我们学习了IRP的数据结构的相关知识,接下来我们继续来学习内核中很重要的另一批数据结构: EPROCESS/KPROCESS/PEB.把它们放到一起是因为这三个数据结构及其外延和w ...
- python3.4学习笔记(十一) 列表、数组实例
python3.4学习笔记(十一) 列表.数组实例 #python列表,数组类型要相同,python不需要指定数据类型,可以把各种类型打包进去#python列表可以包含整数,浮点数,字符串,对象#创建 ...
- Linux内核学习笔记-2.进程管理
原创文章,转载请注明:Linux内核学习笔记-2.进程管理) By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- Linux内核学习笔记-1.简介和入门
原创文章,转载请注明:Linux内核学习笔记-1.简介和入门 By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- Linux内核学习笔记二——进程
Linux内核学习笔记二——进程 一 进程与线程 进程就是处于执行期的程序,包含了独立地址空间,多个执行线程等资源. 线程是进程中活动的对象,每个线程都拥有独立的程序计数器.进程栈和一组进程寄存器 ...
- 20135316王剑桥Linux内核学习笔记
王剑桥Linux内核学习笔记 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 计算机是如何工作的 个人理 ...
- Go语言学习笔记十一: 切片(slice)
Go语言学习笔记十一: 切片(slice) 切片这个概念我是从python语言中学到的,当时感觉这个东西真的比较好用.不像java语言写起来就比较繁琐.不过我觉得未来java语法也会支持的. 定义切片 ...
- KTHREAD 线程调度 SDT TEB SEH shellcode中DLL模块机制动态获取 《寒江独钓》内核学习笔记(5)
目录 . 相关阅读材料 . <加密与解密3> . [经典文章翻译]A_Crash_Course_on_the_Depths_of_Win32_Structured_Exception_Ha ...
随机推荐
- Windows环境安装与配置RocketMQ
1.下载RocketMQ http://rocketmq.apache.org/release_notes/release-notes-4.3.0/ 2.解压下载的安装包rocketmq-all-4. ...
- springmvc html与jsp解析器
1. 配置多个视图解析器 InternalResourceViewResolver内置了jsp解析器,用于解析jsp页面 此处我们使用了InternalResourceViewResolver,其有一 ...
- spring中创建bean对象的三种方式以及作用范围
时间:2020/02/02 一.在spring的xml配置文件中创建bean对象的三种方式: 1.使用默认构造函数创建.在spring的配置文件中使用bean标签,配以id和class属性之后,且没有 ...
- SetConsoleTextAttribute设置颜色后的恢复
1. #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <string.h> #include <s ...
- tomcat的编码设置
Connector port="8080" protocol="HTTP/1.1" URIEncoding="UTF-8" ...
- 林大妈的JavaScript进阶知识(一):对象与内存
JavaScript中的基本数据类型 在JS中,有6种基本数据类型: string number boolean null undefined Symbol(ES6) 除去这六种基本数据类型以外,其他 ...
- Codeforces_334_C
http://codeforces.com/problemset/problem/334/C 求不能凑整n,和最小,数量最多的数量. #include<iostream> #include ...
- Java并发编程(三):ReentrantLock
ReentrantLock是可以用来代替synchronized的.ReentrantLock比synchronized更加灵活,功能上面更加丰富,性能方面自synchronized优化后两者性能没有 ...
- 使用递归函数用来输出n个元素的所有子集(数据结构、算法与应用)
例如,三个元素的集合A = {a,b,c}的所有子集是:空集a,b,c,ab,ac,bc,abc,共八个 分析: 对于集合A中的每个元素,在其子集中都可能存在或者不存在,所以A的子集有23种. 可以设 ...
- Netty学习(2):IO模型之NIO初探
NIO 概述 前面说到 BIO 有着创建线程多,阻塞 CPU 等问题,因此为解决 BIO 的问题,NIO 作为同步非阻塞 IO模型,随 JDK1.4 而出生了. 在前面我们反复说过4个概念:同步.异步 ...