PostgreSQL内核学习笔记十一(索引)
Index Scan涉及到两部分的内容Heap Only Tuple和index-only-scan。
什么是Heap Only Tuple(HOT)?
例如:Update a Row Without HOT
testdb=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
data | text | | |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)
假设更新一条数据
testdb=# UPDATE tbl SET data = 'B' WHERE id = 1000;
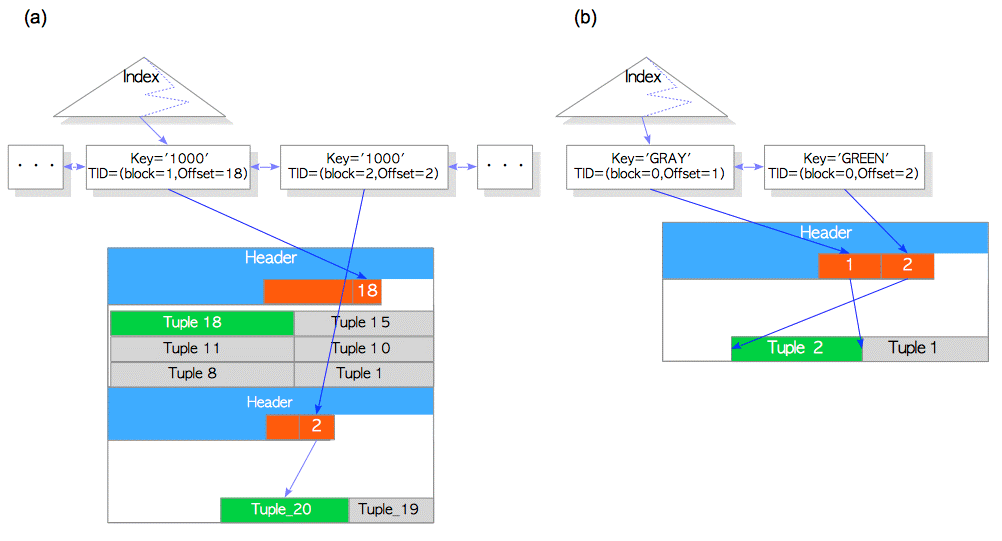
如果没有HOT机制,则不仅仅增加一个新的元组Tuple2,而且还增加了一个Index元组,如下图所示
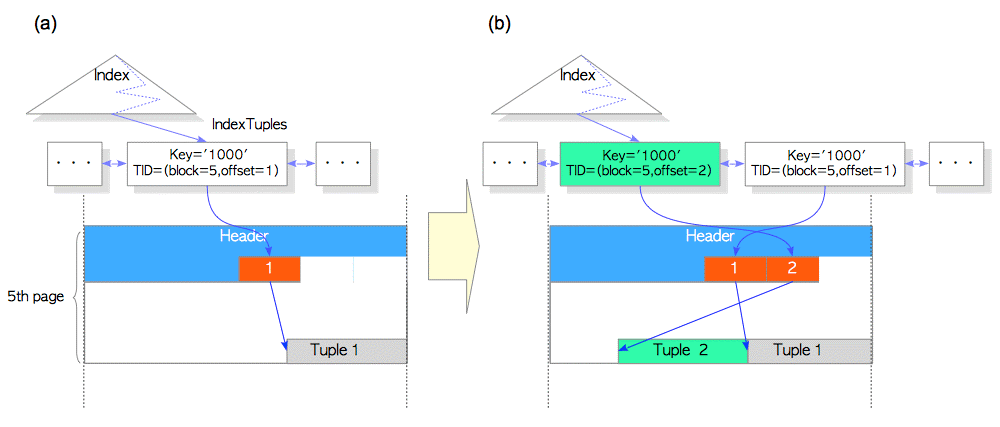
如果Update a Row With HOT,那么更新后会怎样?
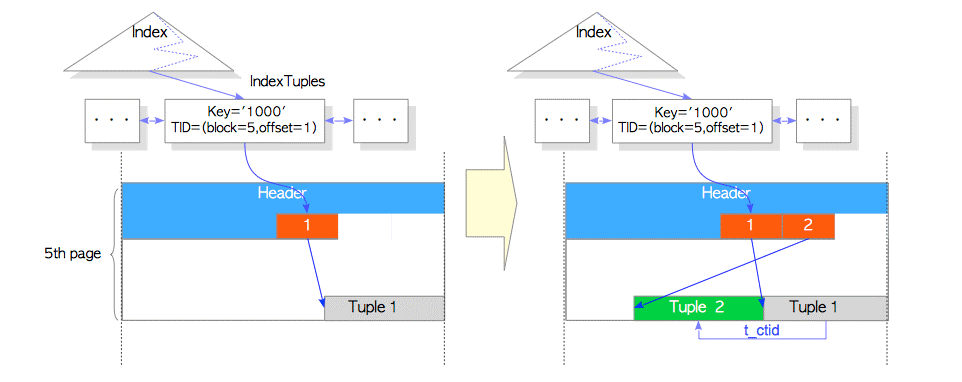
根据上图仅仅增加一个新的元组Tuple2。
同时Tuple1被设置了HEAP_HOT_UPDATED, Tuple2被设置了HEAP_ONLY_TUPLE.
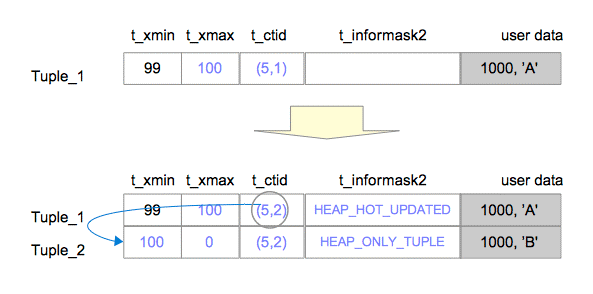
更新后数据是怎么通过Index检索到的?
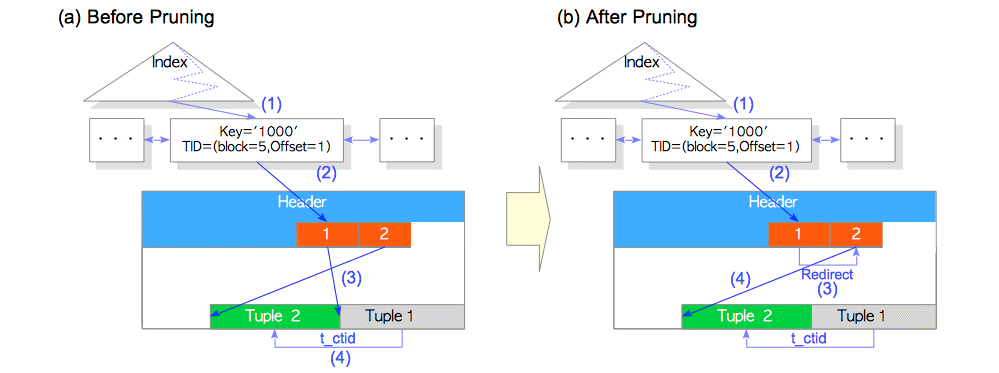
根据图(a)Before Pruning ,通过Index找到Tuple1,再根据Tuple1中的t_ctid找到Tupe2。此时会读取到两个元组Tuple1和Tuple2,根据MVCC机制决定读取Tupel1还是Tuple2.
上述的查找过程会带来问题:如果dead Tuple被删除了如:Tuple1,此时通过index就无法找到Tuple2.
为了解决这个问题,在合适的时候,PostgreSQL会像图(b)After Pruning中所示的现将Header中“1”指向“2”,再将“2”指向Tuple2. 这就被称为“Pruning”。
具体的执行时间可参考
https://github.com/postgres/postgres/blob/master/src/backend/access/heap/README.HOT
SELECT, UPDATE, INSERT and DELETE文被执行的时候,会进行pruning 处理。
![avatar]https://img2018.cnblogs.com/blog/1922961/202001/1922961-20200117160110815-2048897544.png)
在适当的时候,PostgreSQL会删除dead Tuple。PostgreSQL中被称为“Defragmentation”
注意:Defragmentation 的花费比VACUUM的花费要小,因为Defragmentation处理并不删除Index Tuple
{kind=link}
下面的两个场景不适用于HOT
(1) 更新的元组和旧的原组不在一个page上,比如下图的图a此时需要增加一个新的Index Tuple指向新的Tuple
(2) 如果Index值被更新了,这时需在Index page中新增一个Index Tuple
HOT相关的统计信息可参考统计表pg_stat_all_tables
什么是Index-Only Scan?
为了降低I/O(Input/Output)的花费,当SELECT的目标列就是index 列时,直接使用Index key不去使用Table page。
例如下表
testdb=# \d tbl
Table "public.tbl"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
name | text |
data | text |
Indexes:
"tbl_idx" btree (id, name)
表中已经插入的两个元组:
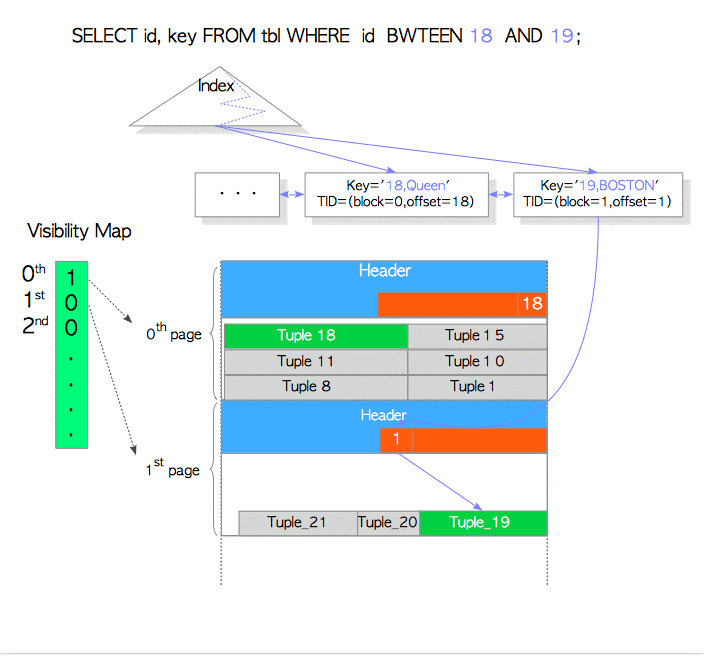
‘Tuple_18’, id的值是 ‘18’,name 的值是 ‘Queen’,这个元组存储在第0个 page.
‘Tuple_19’, id的值是‘19’, name 的值是 ‘BOSTON’, 这个元组存储在第1个 page
执行下面的SELECT文
testdb=# SELECT id, name FROM tbl WHERE id BETWEEN 18 and 19;
id | name
----+--------
18 | Queen
19 | Boston
(2 rows)
具体的过程如下:
这个查询要获取id, name这两列的值,并且"tbl_idx"是由这两列组成的。所以使用index scan。
咋看下是不需要获取table page的,因为index tuple已经包含需要的值了。
但是由于PostgreSQL还需要check元组的可见性visibility,index tuple中并不含有可见性visibility的信息(heap Tuple中才有的t_xmin and t_xmax 信息)。所以PostgreSQL不得不去使用table data。
为了解决这个问题,PostgreSQL使用了visibility map记录表的可见性,如下图。
如果所有tuple存储的page是可见的,PostgreSQL就直使用index key不去使用table page。否则的话,就去读table page检查其可见性。
在本例中Tuple_18直接使用index key,Tuple_19则需要使用table page检查其可见性。
参考资料:http://www.interdb.jp/pg/pgsql07.html
PostgreSQL内核学习笔记十一(索引)的更多相关文章
- PostgreSQL内核学习笔记四(SQL引擎)
PostgreSQL实现了SQL Standard2011的大部分内容,SQL处理是数据库中非常复杂的一部分内容. 本文简要介绍了SQL处理的相关内容. 简要介绍 SQL文的处理分为以下几个部分: P ...
- EPROCESS 进程/线程优先级 句柄表 GDT LDT 页表 《寒江独钓》内核学习笔记(2)
在学习笔记(1)中,我们学习了IRP的数据结构的相关知识,接下来我们继续来学习内核中很重要的另一批数据结构: EPROCESS/KPROCESS/PEB.把它们放到一起是因为这三个数据结构及其外延和w ...
- python3.4学习笔记(十一) 列表、数组实例
python3.4学习笔记(十一) 列表.数组实例 #python列表,数组类型要相同,python不需要指定数据类型,可以把各种类型打包进去#python列表可以包含整数,浮点数,字符串,对象#创建 ...
- Linux内核学习笔记-2.进程管理
原创文章,转载请注明:Linux内核学习笔记-2.进程管理) By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- Linux内核学习笔记-1.简介和入门
原创文章,转载请注明:Linux内核学习笔记-1.简介和入门 By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- Linux内核学习笔记二——进程
Linux内核学习笔记二——进程 一 进程与线程 进程就是处于执行期的程序,包含了独立地址空间,多个执行线程等资源. 线程是进程中活动的对象,每个线程都拥有独立的程序计数器.进程栈和一组进程寄存器 ...
- 20135316王剑桥Linux内核学习笔记
王剑桥Linux内核学习笔记 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 计算机是如何工作的 个人理 ...
- Go语言学习笔记十一: 切片(slice)
Go语言学习笔记十一: 切片(slice) 切片这个概念我是从python语言中学到的,当时感觉这个东西真的比较好用.不像java语言写起来就比较繁琐.不过我觉得未来java语法也会支持的. 定义切片 ...
- KTHREAD 线程调度 SDT TEB SEH shellcode中DLL模块机制动态获取 《寒江独钓》内核学习笔记(5)
目录 . 相关阅读材料 . <加密与解密3> . [经典文章翻译]A_Crash_Course_on_the_Depths_of_Win32_Structured_Exception_Ha ...
随机推荐
- Java之路——初识Eclipse
零.大纲 一.前言 二.获取Eclipse 三.运行Eclipse 四.创建及运行第一个Java Project 五.界面介绍 六.如何调试 七.获取插件 八.Eclipse 快捷键 九.总结 一.前 ...
- Mavn 项目 引入第三方jar包 导致ClassNotFoundException
案例 我有一个Maven构建的项目,项目模块之间有依赖关系,我需要用到一个本地的jar包,而该jar包不能通过配置pom.xml文件从远程仓库自动下载,于是我直接导入该jar包到其中一个项目,不通过p ...
- List容器排序方法的使用
今天在做任务的时候需要对已经存到list容器里的对象数组进行排序,需要根据 其中的一个属性进行排序,最初是根据一个利用冒泡排序的算法进行处理的后来上网查了一下对于list容器进行排序时有自带的方法.所 ...
- linux下面误删root里面的文件夹 恢复方法
手残吧 /root/ 里面的文件删除了. .mkdir /root cp -a /etc/skel/.[!.]* /root 主要是吧 /etc/skel/里面的文件拷贝回去就行了~~~哈.. 转自: ...
- OpenCV3入门(四)图像的基础操作
1.访问图像像素 1)灰度图像 2)彩色图像 OpenCV中的颜色顺序是BGR而不是RGB. 访问图像的像素在OpenCV中就是访问Mat矩阵,常用的有三种方法. at定位符访问 Mat数据结构,操作 ...
- CentOS8 上安装Docker
从 2017 年 3 月开始 docker 在原来的基础上分为两个分支版本: Docker CE 和 Docker EE.Docker CE 即社区免费版,Docker EE 即企业版,强调安全,但需 ...
- kendo ui 实现MVVM
MVVM model----view model----model 实现页面和model之间的动态绑定 grid 支持 events source visib ...
- 检测并移除WMI持久化后门
WMI型后门只能由具有管理员权限的用户运行.WMI后门通常使用powershell编写的,可以直接从新的WMI属性中读取和执行后门代码,给代码加密.通过这种方式攻击者会在系统中安装一个持久性的后门 ...
- num12---组合模式
案例描述: 学校下有多个学院,每个学院下有多个专业系. 把学校.院系.专业 全都看成某个组织类型,含有添加add方法,删除remove方法,显示print方法. 如果有新增的院系.专业,新增加对应的 ...
- Python socket 基础(Server) - Foundations of Python Socket
Python socket 基础 Server - Foundations of Python Socket 通过 python socket 模块建立一个提供 TCP 链接服务的 server 可分 ...