MySQL百万数据深度分页优化思路分析
业务场景
一般在项目开发中会有很多的统计数据需要进行上报分析,一般在分析过后会在后台展示出来给运营和产品进行分页查看,最常见的一种就是根据日期进行筛选。这种统计数据随着时间的推移数据量会慢慢的变大,达到百万、千万条数据只是时间问题。
瓶颈再现
创建了一张user表,给create_time字段添加了索引。并在该表中添加了100w条数据。
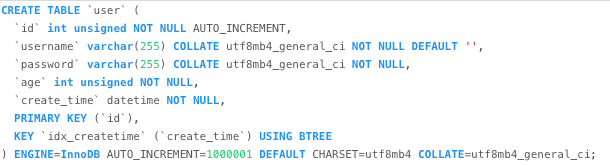
我们这里使用limit分页的方式查询下前5条数据和后5条数据在查询时间上有什么区别。
查询前10条基本上不消耗什么时间

我们从第50w+开始取数据的时候,查询耗时1秒。

SQL_NO_CACHE
这个关键词是为了不让SQL查询走缓存。
同样的SQL语句,不同的分页条件,两者的性能差距如此之大,那么随着数据量的增长,往后页的查询所耗时间按理会越来越大。
问题分析
回表
我们一般对于查询频率比较高的字段会建立索引。索引会提高我们的查询效率。我们上面的语句使用了SELECT * FROM user,但是我们并不是所有的字段都建立了索引。当从索引文件中查询到符合条件的数据后,还需要从数据文件中查询到没有建立索引的字段。那么这个过程称之为回表。
覆盖索引
如果查询的字段正好创建了索引了,比如 SELECT create_time FROM user,我们查询的字段是我们创建的索引,那么这个时候就不需要再去数据文件里面查询,也就不需要回表。这种情况我们称之为覆盖索引。
IO
回表操作通常是IO操作,因为需要根据索引查找到数据行后,再根据数据行的主键或唯一索引去聚簇索引中查找具体的数据行。聚簇索引一般是存储在磁盘上的数据文件,因此在执行回表操作时需要从磁盘读取数据,而磁盘IO是相对较慢的操作。
LIMTI 2000,10 ?
你有木有想过LIMIT 2000,10会不会扫描1-2000行,你之前有没有跟我一样,觉得数据是直接从2000行开始取的,前面的根本没扫描或者不回表。其实这样的写法,一个完整的流程是查询数据,如果不能覆盖索引,那么也是要回表查询数据的。
现在你知道为什么越到后面查询越慢了吧!
问题总结
我们现在知道了LIMIT 遇到后面查询的性能越差,性能差的原因是因为要回表,既然已经找到了问题那么我们只需要减少回表的次数就可以提升查询性能了。
解决方案
既然覆盖索引可以防止数据回表,那么我们可以先查出来主键id(主键索引),然后将查出来的数据作为临时表然后 JOIN 原表就可以了,这样只需要对查询出来的5条结果进行数据回表,大幅减少了IO操作。
优化前后性能对比
我们看下执行效果:
优化前:1.4s

优化后:0.2s

查询耗时性能大幅提升。这样如果分页数据很大的话,也不会像普通的limit查询那样慢。
MySQL百万数据深度分页优化思路分析的更多相关文章
- MySQL 大数据量分页优化
假设有一个千万量级的表,取1到10条数据: ,; ,; 这两条语句查询时间应该在毫秒级完成: ,; 你可能没想到,这条语句执行之间在5s左右: 为什么相差这么大? 可能mysql并没有你想的那么智能, ...
- Mysql大数据量分页优化
假设有一个千万量级的表,取1到10条数据: select * from table limit 0,10; select * from table limit 1000,10; 这两条语句查询时间应该 ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
- [译]async/await中使用阻塞式代码导致死锁 百万数据排序:优化的选择排序(堆排序)
[译]async/await中使用阻塞式代码导致死锁 这篇博文主要是讲解在async/await中使用阻塞式代码导致死锁的问题,以及如何避免出现这种死锁.内容主要是从作者Stephen Cleary的 ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- 【mysql优化】大数据量分页优化
limit 翻页原理 limit offset,N, 当offset非常大时, 效率极低, 原因是mysql并不是跳过offset行,然后单取N行, 而是取offset+N行,返回放弃前offset行 ...
- MySQL百万级数据分页查询及优化
方法1: 直接使用数据库提供的SQL语句 语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N 适应场景: 适用于数据量较少的情况(元组百/千级) 原因/缺 ...
- 【MYSQL】mysql大数据量分页性能优化
转载地址: http://www.cnblogs.com/lpfuture/p/5772055.html https://www.cnblogs.com/shiwenhu/p/5757250.html ...
- MySQL大数据量分页性能优化
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- MySQL大数据量分页查询
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
随机推荐
- 转载C#加密方法
方法一: //须添加对System.Web的引用 using System.Web.Security; ... /// <summary> ...
- listener.log/listener_scan1.log监听日志太大清理
listener_scan1.log清理lsnrctlset current_listener listener_scan1show log_statusset log_status offcd /u ...
- layui使用OSS上传
1.首先要把aliyun-oss-sdk.js包下载下来,放到指定的目录下面 在要用的页面引入或者在index.html入口文件全局引入: <script src="util/ali ...
- java8-并行计算
java8提供一个fork/join framework,fork/join框架是ExecutorService接口的一个实现,它可以帮助你充分利用你电脑中的多核处理器,它的设计理念是将一个任务分割成 ...
- 【新版】使用 go-cqhttp 扫码登录,一键接入 ChatGPT 机器人到 QQ 群
目录 项目效果 安装 go-cqhttp 虚拟文件 启动 ChatGPT 项目效果 由于 ChatGPT 目前只能在漂亮国使用,所以想要在国内使用 ChatGPT 必然险阻重重 不仅时时刻刻要跟企鹅公 ...
- IDEA学生认证的步骤详解
步骤详解 在上次使用学生认证的方法对jetbrains认证成功之后,咱们在IDEA这里认证一下吧! 一.点击help这里的register 如图所示: 进入这样一个界面: 然后点击左下角的的Log I ...
- 68.C++中的const
编写程序过程中,我们有时不希望改变某个变量的值.此时就可以使用关键字 const 对变量的类型加以限定. 初始化和const 因为const对象一旦创建后其值就不能再改变,所以const对象必 ...
- 改进 hibernate-validator,新一代校验框架 validator 使用介绍 v0.4
项目介绍 java 开发中,参数校验是非常常见的需求.但是 hibernate-validator 在使用过程中,依然会存在一些问题. validator 在 hibernate-validator ...
- hdfs的异构存储
目录 1 背景 2 hdfs异构存储类型和存储策略 2.1 hdfs支持的存储类型 2.2 hdfs如何知道数据存储目录是那种存储类型 2.3 存储策略 2.3.1 在hdfs中支持如下存储策略 2. ...
- 什么时候需要使用try-catch
代码执行预料不到的情况,或出错的可能性很大时,使用try-catch语句 构造一个文件输入流(上传文件时,线上环境的内存情况不确定)出错的可能性很大 文件上传写入, 数据库事务的提交,还有摄像头和打印 ...