Redis中 HyperLogLog数据类型使用总结
转载请注明出处:
目录
1. HyperLogLog 的原理
Redis HyperLogLog基于一种称为HyperLogLog算法的概率性算法来估计基数。 HyperLogLog使用一个长度为m的位数组和一些hash函数来估计集合中的唯一元素数。
在 HyperLogLog 算法中,对每个元素进行哈希处理,把哈希值转换为二进制后,根据二进制串前缀中 1 的个数来给每个元素打分。例如,一个元素的哈希值为01110100011,那么前缀中1的个数是3,因此在 HyperLogLog 算法中,这个元素的分数为3。
当所有元素的分数统计完之后,取每一个分数的倒数(1 / 2^n),然后将这些倒数相加后取倒数,就得到一个基数估计值,这个值就是HyperLogLog算法的估计结果。
HyperLogLog算法通过对位数组的长度m的大小进行取舍,折衷数据结构占用的内存与估计值的精准度(即估计误差),得到了在数据占用空间与错误较小程度之间完美的平衡。
简而言之,HyperLogLog算法的核心思想是基于哈希函数和位运算,通过将哈希值转换成比特流并统计前导0的个数,从而快速估算大型数据集中唯一值的数量。通过 hyperloglog 算法我们可以在非常大的数据集中进行极速的网页浏览器去重。
2.使用步骤:
Redis HyperLogLog是一种可用于估算集合中元素数量的数据结构,它能够通过使用非常少的内存来维护海量的数据。它的精确度要比使用一般的估计算法高,并且在处理大量数据时的速度也非常快。
一个简单的例子,我们可以用HyperLogLog来计算访问网站的独立IP数,具体可以按以下步骤操作:
首先创建一个HyperLogLog数据结构:
PFADD hll:unique_ips 127.0.0.1为每次访问ip添加到unique_ips数据结构中:
PFADD hll:unique_ips 192.168.1.1获取计算集合中元素数量的近似值:
PFCOUNT hll:unique_ips可以通过对多个HyperLogLog结构(例如按天或按小时)的合并,来获得更精确的计数。
需要注意的是,HyperLogLog虽然可以节省大量的内存,但它是一种估计算法,误差范围并不是完全精确的,实际使用时应注意其适用范围。
3.实现请求ip去重的浏览量使用示例
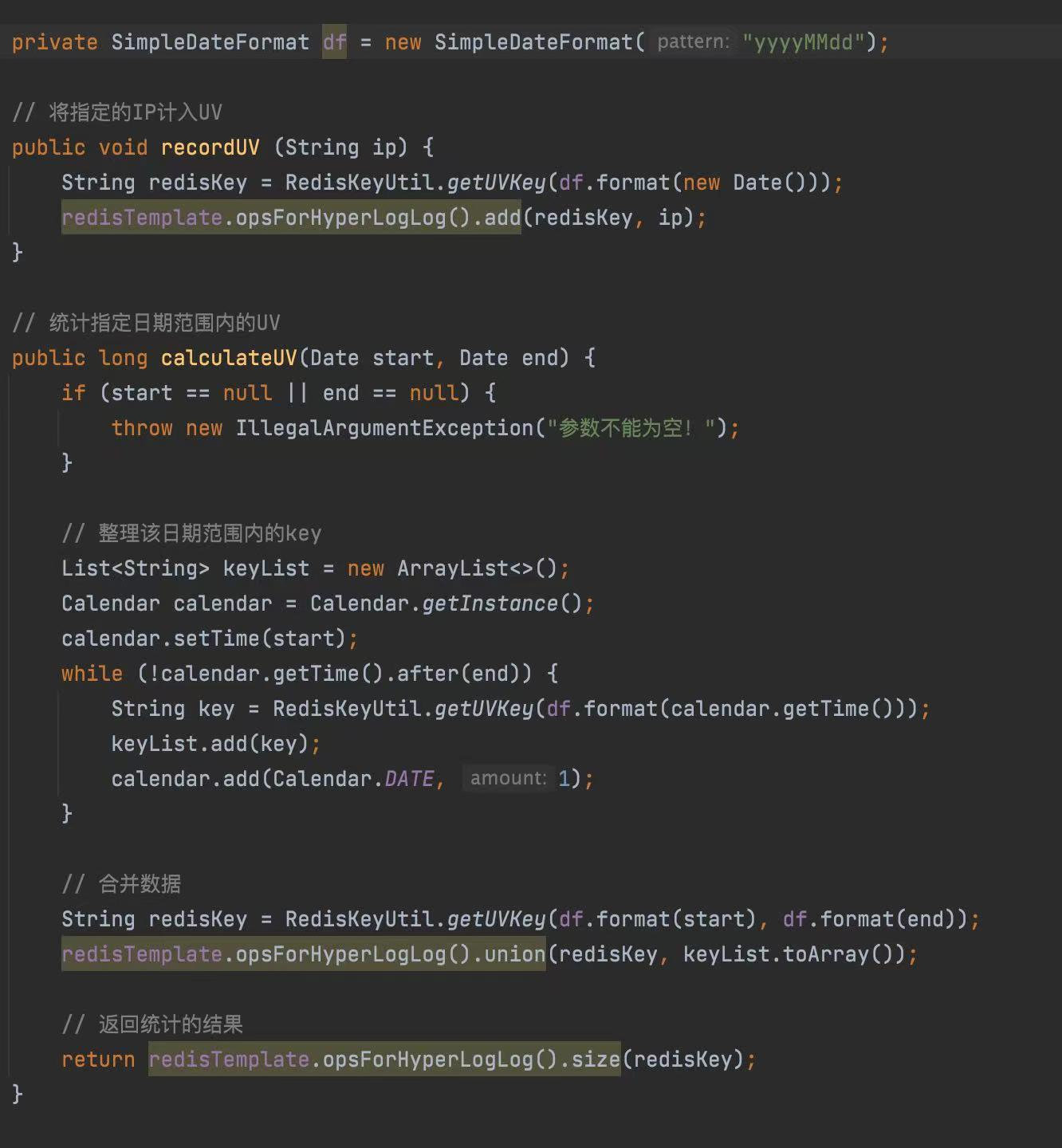
4.Jedis客户端使用
1. 添加依赖,引入jedis依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.6.0</version>
</dependency>
2.创建一个Jedis对象:
Jedis jedis = new Jedis("localhost");
3.向HyperLogLog数据结构添加元素:
jedis.pfadd("hll:unique_ips", "127.0.0.1");
4. 获取计算集合中元素数量的近似值:
Long count = jedis.pfcount("hll:unique_ips");
System.out.println(count);
5.可以通过对多个HyperLogLog结构的合并来获得更精确的计数。在Jedis中可以使用PFMERGE命令来合并HyperLogLog数据结构:
jedis.pfmerge("hll:unique_ips", "hll:unique_ips1", "hll:unique_ips2", "hll:unique_ips3");
5.Redission使用依赖
1.创建RedissonClient对象
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
RedissonClient redisson = Redisson.create(config);
2.创建RHyperLogLog对象
RHyperLogLog<String> uniqueIps = redisson.getHyperLogLog("hll:unique_ips");
3.添加元素
uniqueIps.add("127.0.0.1");
4..获取近似数量
long approximateCount = uniqueIps.count();
System.out.println(approximateCount);
5.合并多个HyperLogLog对象
RHyperLogLog<String> uniqueIps1 = redisson.getHyperLogLog("hll:unique_ips1");
RHyperLogLog<String> uniqueIps2 = redisson.getHyperLogLog("hll:unique_ips2");
uniqueIps.mergeWith(uniqueIps1, uniqueIps2);
6.HyperLogLog 提供了哪些特性和方法
特性:
精确度低,但占用内存极少。
支持插入新元素,同时不会重复计数。
提供指令来优化内存使用和计数准确性。例如PFADD、PFCOUNT、PFMERGE等指令。
能够估计一个数据集中的不同元素数量,即集合的基数(cardinality)。
支持对多个HyperLogLog对象进行合并操作,以获得这些集合的总基数的近似值。
HyperLogLog常用的方法:
PFADD key element [element ...]:添加一个或多个元素到HyperLogLog结构中。
PFCOUNT key [key ...]:获取一个或多个HyperLogLog结构的基数估计值。
PFMERGE destkey sourcekey [sourcekey ...]:合并一个或多个HyperLogLog结构到一个目标结构中。
PFSELFTEST [numtests]: 测试HyperLogLog估值性能和准确性(仅限Redis4.0+版本)
需要注意的是,HyperLogLog虽然可以节省大量内存,但仍然是一种估计算法,误差范围并不是完全精确的,并且具有一定的计算成本。在使用时需要根据实际应用情况选择是否使用HyperLogLog或其他数据结构来估计元素数量。
7.使用场景总结:
Redis使用HyperLogLog的主要作用是在大数据流(view,IP,城市)的情况下进行去重计数。
具体来说,以下是Redis HyperLogLog用于去重计数的一些场景:
统计页面访问量 - 在Web应用程序中, HyperLogLog可以使用为每个页面计算多少次独特的访问者。通过跨越多个不同的时间段使用HyperLogLog,可以计算出这个页面的所有时间的平均访问数。
统计用户数 - 在分析大数据集合的用户数量方面,HyperLogLog也非常有用。作为一种基于概率的数据结构,尤其是在处理独特的用户ID这样的数据集合时。在此情况下,HyperLogLog首先执行散列,此后仅在内部存储有限的散列值,同时还能够推断大小。
统计广告点击量 - 对于网站或应用程序的广告分析,HyperLogLog可以用于捕获有效点击数量,即非重复或唯一点击数量。
总之,对于需要进行去重计数的大数据流的情况下,Redis的HyperLogLog是一种简单而强大的工具。
Redis中 HyperLogLog数据类型使用总结的更多相关文章
- redis中各种数据类型对应的jedis操作命令
redis中各种数据类型对应的jedis操作命令 一.常用数据类型简介: redis常用五种数据类型:string,hash,list,set,zset(sorted set). 1.String类型 ...
- Redis 中 HyperLogLog 的使用场景
什么是基数估算 HyperLogLog 是一种基数估算算法.所谓基数估算,就是估算在一批数据中,不重复元素的个数有多少. 从数学上来说,基数估计这个问题的详细描述是:对于一个数据流 {x1,x2,.. ...
- 关于Redis中的数据类型
一. Redis常用数据类型 Redis最为常用的数据类型主要有以下: String Hash List Set Sorted set 一张图说明问题的本质 图一: 图二: 代码: /* Object ...
- Redis 中的数据类型及基本操作
Redis 内置的数据类型有 5种:字符串String.哈希Hash.列表List.集合Set.有序集合ZSet 字符串类型 String 是 Redis 中最基本的类型,一个 key 对应着一个 v ...
- redis中各种数据类型的常用操作方法汇总
在spring中使用jedisTemplate操作,详见https://www.cnblogs.com/EasonJim/p/7803067.html 一.Redis的五大数据类型 1.String( ...
- 面试官:Redis中集合数据类型的内部实现方式是什么?
虽然已经是阳春三月,但骑着共享单车骑了这么远,还有有点冷的.我搓了搓的被冻的麻木的手,对着前台的小姐姐说:"您好,我是来面试的."小姐姐问:"您好,您叫什么名字?&quo ...
- redis中的数据类型
redis不是一个纯文本kv存储,实际上,它是一个数据结构服务,支持不同类型的value. 包含以下类型: 1.Binary-safe strings. 二进制安全的字符串 2.Lists: coll ...
- redis中hash数据类型
remoteSelf:1>hset website google "www.google.com" "1" remoteSelf:1>hget we ...
- Redis 中ZSET数据类型命令使用及对应场景总结
转载请注明出处: 目录 1.zadd添加元素 2.zrem 从有序集合key中删除元素 3.zscore 返回有序集合key中元素member的分值 4.zincrby 为有序集合key中元素增加分值 ...
- 解析Redis操作五大数据类型常用命令
摘要:分享经常用到一些命令和使用场景总结,以及对Redis中五大数据类型如何使用cmd命令行的形式进行操作的方法. 本文分享自华为云社区<Redis操作五大数据类型常用命令解析>,作者:灰 ...
随机推荐
- GitLab + Rainbond 打造Devops流程
GitLab + Rainbond 打造Devops流程 流程 预设项目有两个分支,dev和master dev分支对应dev环境 master分支对应test环境和prod环境 开发在dev中编写代 ...
- Spring的隔离级别,Spring事务传播属性,Spring事务与数据库事务之间的联系
一.Spring五大事务隔离级别 Spring事务隔离级别比数据库事务隔离级别多一个default在进行配置的时候,如果数据库和spring代码中的隔离级别不同,那么以spring的配置为主.1) D ...
- anaconda navigator启动时一直卡在 loading applications 页面解决方法
anaconda3\Lib\site-packages\anaconda_navigator\api\conda_api.py 行1364 把 data = yaml.load(f) 改为 data ...
- React整洁的代码的一些原则
1. Model is everything models are the heart of your app. If you have models separated from th rest ...
- 策略模式demo
/** StrategyContext. */ public class StrategyContext { private Strategy strategy; // 传入的是Strategy的实现 ...
- JavaScript 之 数组在内存中的存储方式(连续或不连续)
最近在纠结一个问题,就是数组这个引用类型在JavaScript 中是不是和其他语言一样开辟了一个连续的内存来存储,但是在JS 中每个元素又可以是不同的类型,这就导致了没办法用一个相同大小的存储,所以数 ...
- Jmeter前置处理器和后置处理器的使用
一.JMETER基本概念 1. 测试计划:顶级菜单,代表一个测试计划: 2. 线程组:代表一个要测试的场景(各种相关的交易集合),对于性能测试来说可以指定多少个用户完成这个场景的内容,对于自动化测试 ...
- servlet - 从本地下载图片
import javax.servlet.ServletException;import javax.servlet.ServletOutputStream;import javax.servlet. ...
- 狐漠漠养成日记 Cp.00002 第一周
主要目标 (1)考研 考研数学二16-22年的真题卷(已完成真题卷:0/7) 记忆考研英语中高频词汇(已记忆词汇:高频:0/10:中频:0/10) 考研英语二16-22年的真题卷(已完成真题卷:0/7 ...
- angular项目语言切换功能
1.NzI18nService服务 参考:https://ng.ant.design/docs/i18n/zh 2.ngx-translate插件 1)安装依赖 npm install @ngx-tr ...