synchronized原理剖析
synchronized原理剖析
并发编程存在什么问题?
1️⃣ 可见性
可见性:是指当一个线程对共享变量进行了修改,那么另外的线程可以立即看到修改后的最新值。
案例演示:一个线程A根据 boolean 类型的标记 flag,while死循环;另一个线程B改变这个flag变量的值;那么线程A并不会停止循环。
/**
案例演示:
一个线程对共享变量的修改,另一个线程不能立即得到最新值
*/
public class Test01Visibility{
// 多个线程都会访问的数据,我们称为线程的共享数据
private static boolean flag = false;
public static void main(String[] args) throws InterruptedException{
// t1线程不断的来读取run共享变量的取值
Thread t1 = new Thread(() -> {
while(flag){
}
});
t1.start();
Thread.sleep(1000);
//t2线程对该共享变量的取值进行修改
Thread t2 = new Thread(() -> {
flag = false;
System.out.println("时间到,线层2设置为false");
});
t2.start();
// 可以观测得到t2线程对 flag 共享变量的修改,t1线程并不能够读取到更改了之后的值,导致程序不能停止;
// 这就出现了可见性问题
}
}
解决可见性:
Ⅰ. 在共享变量前面加上volatile关键字修饰;
Q:为什么
volatile关键字能保证可见性?
- volatile 的底层实现原理是内存屏障(Memory Barrier),保证了对 volatile 变量的写指令后会加入写屏障,对 volatile 变量的读指令前会加入读屏障。
- 写屏障(sfence)保证在写屏障之前的,对共享变量的改动,都同步到主存当中;
- 读屏障(lfence)保证在读屏障之后,对共享变量的读取,加载的是主存中最新数据;
为什么
volatile关键字能解决有序性看下文有序性部分。
Ⅱ. 在死循环内写一个 synchronized 同步代码块,因为synchronized 同步时会对应 JMM 中的 lock 原子操作,lock 操作会刷新工作内存中的变量的值,得到共享内存(主内存)中最新的值,从而保证可见性。【看下文Java内存模型】
Q:为什么
synchronized同步代码块能保证可见性?
synchronized同步的时候会对应8个原子操作当中的lock与unlock这两个原子操作,lock操作执行时该线程就会去主内存中获取到共享变量最新值,刷新工作内存中的旧值,从而保证可见性。
Thread t1 = new Thread(() -> {
while(run){
synchronized(obj) { // 死循环内加一个同步代码块
}
}
});
t1.start();
// 或者
Thread t1 = new Thread(() -> {
while(run){
// 输出语句也能保证可见性?
// 因为PrintStream.java中的println(boolean x)方法中也使用到了synchronized,synchronized 能保证可见性
System.out.println();
}
});
t1.start();
小结:
可见性(Visibility):是指当一个线程对共享变量进行了修改,那么另外的线程可以立即看到修改后的最新值。
synchronized 可以保证可见性,但缺点是 synchronized 锁属于重量级操作,性能相对更低。
2️⃣ 原子性
原子性(Atomicity): 在一次或多次操作中,要么所有的操作都执行,并且不会受其他因素干扰而中断,要么所有的操作都不执行;
案例演示:5个线程各执行1000次i++操作:
/**
案例演示:5个线程各执行1000次 i++;
*/
public class Test02Atomicity{
private static int number = 0;
public static void main(String[] args) throws InterruptedException{
// 5个线程都执行1000次 i++
Runnable increment = () -> {
for( int i = 0 ; i < 1000; i++){
number++;
}
};
// 5个线程
ArrayList<Thread> ts = new ArrayList<>();
for(int i = 0; i < 5 ; i++){
Thread t = new Thread(increment);
t.start();
ts.add(t);
}
for(Thread t : ts){
t.join();
}
/* 最终的效果即,加出来的效果不是5000,可能会少于5000
那么原因就在于 i++ 并不是一个原子操作
下面会通过java反汇编的方式来进行演示和分析,这个 i++ 其实有4条指令
*/
System.out.println("number = "+ number);
}
}
Idea 中找到target目录,找到当前java文件的字节码.class文件,该目录下打开cmd,输入javap -p -v xxx.class,得到字节码指令,其中,number++对应的字节码指令为:
9: getstatic #18 // Field number:I 获取静态变量的值
12: iconst_1 // 准备一个常量1
13: iadd // 让静态变量和1做相加操作
14: putstatic #18 // Field number:I 把相加后的结果赋值给静态变量
number++是由四条字节码指令组成的,那么在一个线程下是没有问题的,但如果是放在多线程的情况下就有问题,比如线程 A 在执行 13: iadd 前,CPU又切换到另外一个线程B,线程 B 执行了 9: getstatic,就会导致两次 number++,但实际上只加了1。
这个问题的原因就在于让两个线程来进行操作
number++, 而number++的字节码指令又是多条指令(4条指令),其中一个线程执行到一半时,CPU又切换到另外一个线程,另外一个线程来执行,读取到的值依然跟另一个线程一样, 即第二个线程干扰了第一个线程的执行从而导致执行结果的错误,没有保证原子性。
解决原子性:
synchronized 可以保证 number++ 的原子性。synchronized 能够保证在同一时刻最多只有一个线程执行该段代码,已保证并发安全的效果。
synchronized(obj){
number++;
}
加了 synchronized 同步代码块后,每次运行的结果都是 5000.
Idea 中找到 target 目录,找到当前java文件的字节码.class文件,该目录下打开cmd,输入javap -p -v xxx.class,得到字节码指令,其中,num++对应的字节码指令还是中间的四条,不过上下新增了几条指令(后文会讲到):
14: monitorenter
15: getstatic #18 // Field number:I
18: iconst_1
19: iadd
20: putstatic #18 // Field number:I
23: aload_1
24: monitorexit
小结:
原子性(Atomicity): 在一次的操作或多次操作中,要么所有的操作全部都得到了执行并且不会受到任何因素的干扰而中断,要么所有的操作都不执行。
原子性可以通过 synchronized 同步代码块或 ReentrantLock 来解决。
3️⃣ 有序性
有序性(Ordering):是指程序代码在执行过程中的先后顺序,由于java在编译器以及运行期的优化,导致了代码的执行顺序未必就是开发者编写代码的顺序。
Q:为什么要重排序?
一般会认为编写代码的顺序就是代码最终的执行顺序,那么实际上并不一定是这样的,为了提高程序的执行效率,java在编译时和运行时会对代码进行优化(JIT即时编译器),会导致程序最终的执行顺序不一定就是编写代码时的顺序。
重排序 是指 编译器 和 处理器 为了优化程序性能 而对 指令序列 进行 重新排序 的一种手段;
解决有序性:
Ⅰ. 可以使用 synchronized 同步代码块来保证有序性;
Q:synchronized保证有序性的原理是?
加了
synchronized,依然会发生指令重排序(可以看看DCL单例模式),只不过,由于存在同步代码块,可以保证只有一个线程执行同步代码块当中的代码,也就能保证有序性。
Ⅱ. 除了可以使用synchronized来进行解决,还可以给共享变量加volatile关键字来解决有序性问题。
volatile如何保证有序性的?
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后;
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前;
总结
synchronized 可以保证原子性、有序性和可见性,而 volatile 只能保证有序性和可见性;
synchronized 是个重量级锁,应尽量少使用;
Java内存模型
定义
java内存模型(即 java Memory Model,简称JMM),主要分成两部分来看,一部分叫做主内存,另一部分叫做工作内存。
- java当中的共享变量;都放在主内存当中,如类的成员变量(实例变量),还有静态的成员变量(类变量),都是存储在主内存中的。每一个线程都可以访问主内存;
- 每一个线程都有其自己的工作内存,当线程要执行代码的时候,就必须在工作内存中完成。比如线程操作共享变量,它是不能直接在主内存中操作共享变量的,只能够将共享变量先复制一份,放到线程自己的工作内存当中,线程在其工作内存对该复制过来的共享变量处理完后,再将结果同步回主内存中去。
主内存
- 主内存是 所有线程都共享的,都能访问的。所有的共享变量都存储于主内存;
- 共享变量主要包括类当中的成员变量,以及一些静态变量等。局部变量是不会出现在主内存当中的,因为局部变量只能线程自己使用;
工作内存
- 每一个线程都有自己的工作内存,工作内存只存储 该线程对共享变量的副本。线程对变量的所有读写操作都必须在工作内存中完成,而不能直接读写主内存中的变量,不同线程之间也不能直接访问 对方工作内存中的 变量;
- 线程对共享变量的操作都是对其副本进行操作,操作完成之后再同步回主内存当中去;
作用
主要目的就是在多线程对共享变量进行读写时,来保证共享变量的可见性、有序性、原子性;在编程当中是通过两个关键字 synchronized 和 volatile 来保证共享变量的三个特性的。
主内存与工作内存如何交互
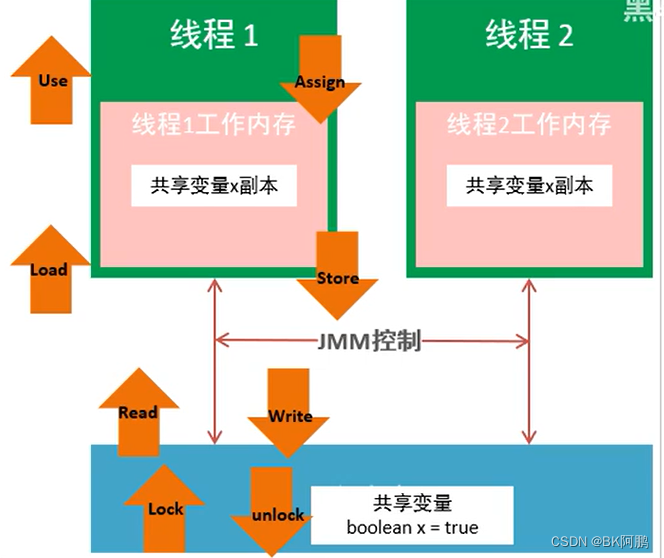
一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存的呢?
Java内存模型 中定义了上图中的 8 种操作(橙色箭头)来完成,虚拟机实现时必须保证每一种操作都是原子的、不可再分的。
举个:
假设现在线程1想要来访问主内存当中的共享变量 x ,即当前主内存中的共享变量x的取值为 boolean x = true;
线程1首先会做一个原子操作叫做Read,读取主内存当中的共享变量x的取值,即 boolean x = true;
接下来就是 Load 操作,把在主内存中读取到的共享变量加载到了工作内存当中(副本);
接着执行 Use 操作,如果线程1需要对共享变量x进行操作,即会取到从主内存中加载过来的共享变量x的取值去进行一些操作;
操作之后会有一个新的结果返回,假设令这个共享变量的取值变为false,完成 Assign 操作,即给共享变量x赋新值;
操作完成之后;就需要同步回主内存,首先会完成一个 Store 的原子操作,来保存这个处理结果;
接着执行Write操作,即在工作内存中,Assign 赋值给共享变量的值同步到主内存当中,主内存中共享变量取值x由true更改为false。
--------------------------------
另外还有两个与锁相关的操作,Lock与unlock,比如说加了synchronized,才会产生有lock与unlock操作;
如果对共享变量的操作没有加锁,那么也就不会有lock与unlock操作。
注意:
- 如果对共享变量执行
lock操作,该线程就会去主内存中获取到共享变量的最新值,刷新工作内存中的旧值,保证可见性;(加锁说明要对这个共享变量进行写操作了,先刷新旧值,再操作新值)- 对共享变量执行
unlock操作,必须先把此变量同步回主内存中,再执行unlock;(因为对共享变量释放锁,接下来其他线程就能访问到这个共享变量,就必须使这个共享变量呈现的是最新值)这两点就是
synchronized为什么能保证“可见性”的原因。
小结
主内存 与 工作内存 之间的 数据交互过程(即主内存与工作内存的交互是通过这8个原子操作来保证数据的正确性的):
lock → read → load → use → assign → store → write → unlock
synchronized 的特性
synchronized 作为悲观锁,具有两个特性,一个是 可重入性,一个是不可中断性。
1️⃣ 可重入
定义
指的是 同一个线程的 可以多次获得 同一把锁(一个线程可以多次执行synchronized,重复获取同一把锁)。
/*
可重入特性
指的是 同一个线程获得锁之后,可以再次获取该锁。
*/
public class Demo01{
public static void main(String[] args){
Runnable sellTicket = new Runnable(){
@Override
public void run(){
synchronized(Demo01.class){
System.out.println("我是run");
test01();
}
}
public void test01(){
synchronized(Demo01.class){
System.out.println("我是test01");
}
}
};
new Thread(sellTicket).start();
new Thread(sellTicket).start();
}
}
原理
synchronized 的锁对象中有一个计数器(recursions变量)会记录线程获得几次锁,每重入一次,计数器就 + 1,在执行完一个同步代码块时,计数器数量就会减1,直到计数器的数量为0才释放这个锁。
优点
- 可以避免死锁(如果不能重入,那就不能再次进入这个同步代码块,导致死锁);
- 更好地封装代码(可以把同步代码块写入到一个方法中,然后在另一个同步代码块中直接调用该方法实现可重入);
2️⃣ 不可中断
定义
线程A获得锁后,线程B要想获得锁,必须处于阻塞或等待状态。如果线程A不释放锁,那线程B会一直阻塞或等待,阻塞等待过程中,线程B不可被中断。
synchronized 是不可中断的,处于阻塞状态的线程会一直等待锁。
案例演示
public class Demo02_Uninterruptible{
private static Object obj = new Object(); // 定义锁对象
public static void main(String[] args){
// 1. 定义一个Runnable
Runnable run = ()->{
// 2. 在Runnable定义同步代码块;同步代码块需要一个锁对象;
synchronized(obj){
// 打印是哪一个线程进入的同步代码块
String name = Thread.currentThread().getName();
System.out.println(name + "进入同步代码块");
Thread.sleep(888888);
}
};
// 3. 先开启一个线程来执行同步代码块
Thread t1 = new Thread(run);
t1.start();
// 保证第一个线程先去执行同步代码块
Thread.sleep(1000);
/**
4. 后开启一个线程来执行同步代码块(阻塞状态)到时候第二个线程去执行同步代码块的时候,
锁已经被t1线程锁获取得到了;所以线程t2是无法获取得到Object obj对象锁的;
那么也就将在同步代码块外处于阻塞状态。*/
Thread t2 = new Thread(run);
t2.start();
/** 5. 停止第二个线程;观察此线程t2能否被中断;*/
System.out.println("停止线程前");
t2.interrupt(); // 通过interrupt()方法给t2线程进行强行中断
System.out.println("停止线程后");
// 最后得到两个线程的执行状态
System.out.println(t1.getState()); // TIMED_WAITING
System.out.println(t2.getState()); // BLOCKED
}
}
// 运行结果:
Thread-0进入同步代码块
停止线程前
停止线程后
TIMED_WAITING
BLOCKED // t2的状态依然为BLOCKED,说明synchronized是不可被中断的
结果分析:
通过
interrupt()方法让 t2 线程强行中断,最后打印t2的状态,依然为BLOCKED,即线程不可中断。
对比 ReentrantLock
ReentrantLock 的lock方法是不可中断的,tryLock方法是可中断的。
Ⅰ. 演示 ReentrantLock 不可中断:
public class Demo03_Interruptible{
// 创建一个Lock对象
private static Lock lock = new ReentrantLock();
public static void main(String[] args)throws InterruptedException{
test01();
}
// 演示 Lock 不可中断
public static void test01(){
Runnable run = ()->{
String name =Thread.currentThread().getName();
try{
lock.lock(); // lock() 无返回值
System.out.println(name + "获得锁,进入锁执行");
Thread.sleep(88888);
}catch(InterruptedException e){
e.printStackTrace();
}finally{
lock.unlock(); // unlock也是没有返回值的
System.out.println(name + "释放锁");
}
};
Thread t1 = new Thread(run);
t1.start();
Thread.sleep(1000);
Thread t2 = new Thread(run);
t2.start();
System.out.println("停止t2线程前");
t2.interrupt();
System.out.println("停止t2线程后");
Thread.sleep(1000);
System.out.println(t1.getState());
System.out.println(t2.getState());
}
}
--------------------------------------------------
运行效果:
Thread-0获得锁,进入锁执行
停止t2线程前
停止t2线程后
TIMED_WAITING // t1线程在临界区睡88888ms,有时限的等待
WAITING // t2线程处于等待状态,WAITING
Ⅱ. 演示 ReentrantLock 可中断:
public class Demo03_Interruptible{
private static Lock lock = new ReentrantLock();
public static void main(String[] args)throws InterruptedException{
test02();
}
// 演示 Lock 可中断
public static void test02() throws InterruptedException{
Runnable run = ()->{
String name = Thread.currentThread().getName();
boolean b = false;
try{
b = lock.tryLock(3, TimeUnit.SECONDS);
//说明尝试获取得到了锁;则进入if块当中
if(b){
System.out.println(name + "获得锁,进入锁执行");
Thread.sleep(888888);
}else{
// 没有获取得到锁执行else,证明了Lock.tryLock()是可中断的;
System.out.println(name + "在指定时间内没有获取得到锁则做其他操作");
}
}catch(InterruptedException e){
e.printStackTrace();
}finally{
if(b){ //得到了锁才释放锁
lock.unlock();
System.out.println(name + "释放锁");
}
}
};
Thread t1 = new Thread(run);
t1.start();
Thread t2 = new Thread(run);
t2.start();
}
}
--------------------------------------------------------
代码执行效果:
Thread-0获得锁,进入锁执行
Thread-1在指定时间没有得到锁做其他操作
小结
synchronized 和 ReentrantLock 都是可重入锁;
synchronized 获取不到锁会阻塞等待,该过程不可中断,而ReentrantLock 的 lock 方法不可中断,tryLock方法是可中断的。
synchronized 底层
首先通过javap反汇编的方式来学习synchronized原理:
举个例子:
public class Demo01{
//依赖的锁对象
private static Object obj = new Object();
@Override
public void run(){
for(int i = 0; i < 1000; i++){
// synchronized同步代码块;且在代码块当中做了简单的打印操作;
// 重点是看synchronized在反汇编之后形成的字节码指令
synchronized( obj ){
System.out.println("1");
}
}
}
// 编写了一个synchronized修饰的方法
// synchronized修饰代码块与synchronized修饰方法反汇编之后的结果是不太一样的;
public synchronized void test(){
System.out.println("a");
}
};
// 代码写好之后让idea编译得到字节码文件;
// 编译好的字节码文件目录:工程名/target/classes/xxx/demo04_synchronized_monitor/Demo01.class
找到 target目录下的.class文件,cmd下输入javap -p -v xxx.class进行反编译,得到字节码指令:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3; args_size=1
0: getstatic #2 // Field obj:Ljava/lang/Object;
3: dup
4: astore_1
5: monitorenter
6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
9: 1dc #4 // String 1
11: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: aload_1
15: monitorexit
16: goto 24
19: astore_2
20: aload_1
21: monitorexit // 这个意思是说当同步代码块内出现异常时,会自动帮我们释放锁
22: aload_2
23: athrow
24: return
Exception table:
from to target type
6 16 19 any
19 22 19 any
monitorenter
每一个synchronized 锁对象 都会和 一个监视器monitor关联,监视器被占用时会被锁住,其他线程无法来获取该monitor(这个monitor才是真正的锁),当JVM执行某个线程的某个方法内部的monitorenter时,它会尝试去获取当前对象对应的monitor的所有权(即尝试去获取这把锁;有可能获取到,也有可能获取不到),过程如下:
- 若
monitor的进入数为0,线程可以进入 monitor,并将 monitor的进入数 置为1。 当前线程成为 monitor的 owner(所有者); - 若线程已拥有 monitor的所有权,允许它 重入 monitor,则进入monitor的进入数加1;
- 若其他线程已经占有monitor的所有权,那么当前尝试获取monitor的所有权的线程会被阻塞,直到monitor的进入数变为0,才能重新尝试获取monitor的所有权;
monitor内部有两个重要的成员变量:
- owner:拥有这把锁的线程;
- recursions:记录线程拥有锁的次数
monitorexit
能执行monitorexit指令的线程一定是拥有当前对象的monitor的所有权的线程。
执行monitorexit时会将monitor的进入数(已重入次数)减1,当monitor的进入数减为0时,当前线程退出monitor,不再拥有monitor的所有权,此时其他被这个monitor阻塞的线程可以尝试去获取这个monitor的所有权。
monitorexit插入在方法结束处和异常处(查看上面的字节码指令会发现有两个monitorexit),jvm 保证每个monitorenter必须有一个对应的monitorexit。
Q:synchronized 代码块内出现异常会释放锁吗?【面试题】
A:会自动释放锁,查看字节码指令可以知道,monitorexit插入在方法结束处和异常处。从Exception table异常表中也可以看出。
Exception table:
from to target type
6 16 19 any
19 22 19 any
// from ... to : 指的是从哪一行到哪一行;即指的是6~16行或者19~22行之间的字节码指令,
// 出现了异常则会去执行19行及以后的代码,19后有个monitorexit指令,说明若在同步代码块当中出现了异常,monitor会自动帮助释放锁
同步方法
上面介绍的是synchronized同步代码块内的情况,当 synchronized 修饰方法时,查看反编译后的字节码指令,可以看到同步方法在反汇编后,会增加 ACC_SYNCHRONIZED,会隐式地调用 monitorenter和 monitorexit,即在执行 同步方法 之前会调用 monitorenter,在执行完同步方法后会调用 monitorexit;
源码:
public synchronized void test(){
System.out.println("a");
}
public synchronized void test();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
3: 1dc #6 // String a
5: invokevirtual #5 // Method java/io/PrintStream.println(Ljava/lang/String;)V
LineNUmberTable:
line 13: 0
line 14: 0
LocalVariableTalbe:
Start Length Slot Name Signature
0 9 0 this Lcom/xxx/demo04_synchronized_monitor/Demo01;
......
----------------------------------------------------------------------
对应的源代码:
public synchronized void test(){
System.out.println("a");
}
小结
通过 Javap 反汇编,可以看到
- synchronized使用变成了
monitorenter和monitorexit两个字节码指令,真正的锁是monitor,而不是synchronized后面括号中的对象; - 每个锁对象都会关联一个monitor(监视器,monitor才是真正的锁对象),monitor内部有两个重要的成员变量
owner(owner:会保存获得锁的线程)和recursions(会保存线程获得锁的次数); - 执行monitorenter,线程就会来竞争 monitor 这把锁,抢到monitor这把锁之后,就会将 monito r中的成员变量 owner 的取值改为当前抢到锁的线程,以及拥有锁的次数 recursions 变为1;
- 如果再次进入同步代码块,即嵌套同步代码块,也是同样的一把锁,那么 monitor 的成员变量
recursions的取值就会加一。当执行到monitorexit时,那么monitor的成员变量recursions计数器就会减一;当monitor的计数器recursions减到0时,那么当前拥有该锁 monitor 的线程就会去释放锁;
一道面试题
synchronized与Lock的区别?
- synchronized是关键字,而Lock是一个接口(ReentrantLock为其实现类);
- synchronized会自动释放锁,而Lock必须手动释放锁。(讲一讲monitorenter和monitorexit,同步代码块内有异常也会释放锁)
- synchronized是不可中断的,而Lock可以是不可中断的也可以是可中断的( lock() 和 tryLock() 无参和有参方法);
- 通过Lock可以知道线程有没有拿到锁(调用tryLock()),而synchronized不能;
- synchronized 能锁住方法(成员方法和静态方法)和代码块,而Lock只能锁住代码块(Lock只能在方法内部使用);
- Lock 可以使用读锁提高多线程读的效率(
ReentrantReadWriteLock读读共享,读写互斥); - synchronized 是非公平锁,ReentrantLock 可以控制是否是公平锁(synchronized唤醒的时候并不是公平的先来后到的方式来进行唤醒,而是随机唤醒一个等待的线程);
总结:从关键字类型、是否自动释放锁、是否可中断、锁的作用范围、是否为公平锁等方面来回答。
monitor监视器锁
无论是 synchronized 代码块 还是 synchronized 方法,最终都需要一个 java 对象,而 java 对象又会关联到一个 monitor 监视器锁的东西,真正的同步是靠monitor监视器锁来实现的。
JVM 底层由 C++ 实现,在 HotSpot 虚拟机中,monitor是由 ObjectMonitor 实现的(C++代码),位于 HotSpot 虚拟机源码 ObjectMonitor.hpp文件中(src/share/vm/runtime/objectMonitor.hpp)
ObjectMonitor
下面是 ObjectMonitor 的构造器:
# 构造器,给很多的成员变量赋值(让其与java源代码组合起来进行分析比较方便)
ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0;
_recursions = 0; // 线程的重入次数
// 即obj对象会引用monitor对象;而monitor对象中的成员变量属性_object取值也会引用着java对象;
_object = NULL; // 存储该monitor的对象,即synchronized括号中的对象
_owner = NULL; // 标识拥有该monitor的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0;
_Responsible = NULL;
_succ = NULL;
_cxq = NULL; // 多线程竞争锁时的单项列表(没获取到锁的线程放入单项列表)
FreeNext = NULL;
_EntryList = NUll; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0;
_SpinClock = 0;
OwnerIsThread = 0;
}
_owner: 初始化为NUll,当有线程占有该monitor时,owner标记为该线程的唯一表示。当线程释放monitor时,owner又恢复到NULL。owner是一个临界资源,JVM是通过CAS操作来保证其线程安全的。_cxq: 竞争队列,所有请求锁的线程首先会被放在这个队列中(单向链接)。_cxq 是一个临界资源,JVM通过CAS原子指令来修改_cxq队列。 修改前 _cxq的旧值 填入了 node的next字段, _cxq指向新值(新线程)。因此 _cxq是一个后进先出的stack(栈)。_EntryList: _cxq队列中 有资格成为 候选资源的 线程 会被移动到该队列中;_WaitSet: 因为调用wait方法而被阻塞的 线程会被放在该队列中;
ObjectMonitor 的构造器包含三种队列: _cxq、_WaitSet和 _EntryList
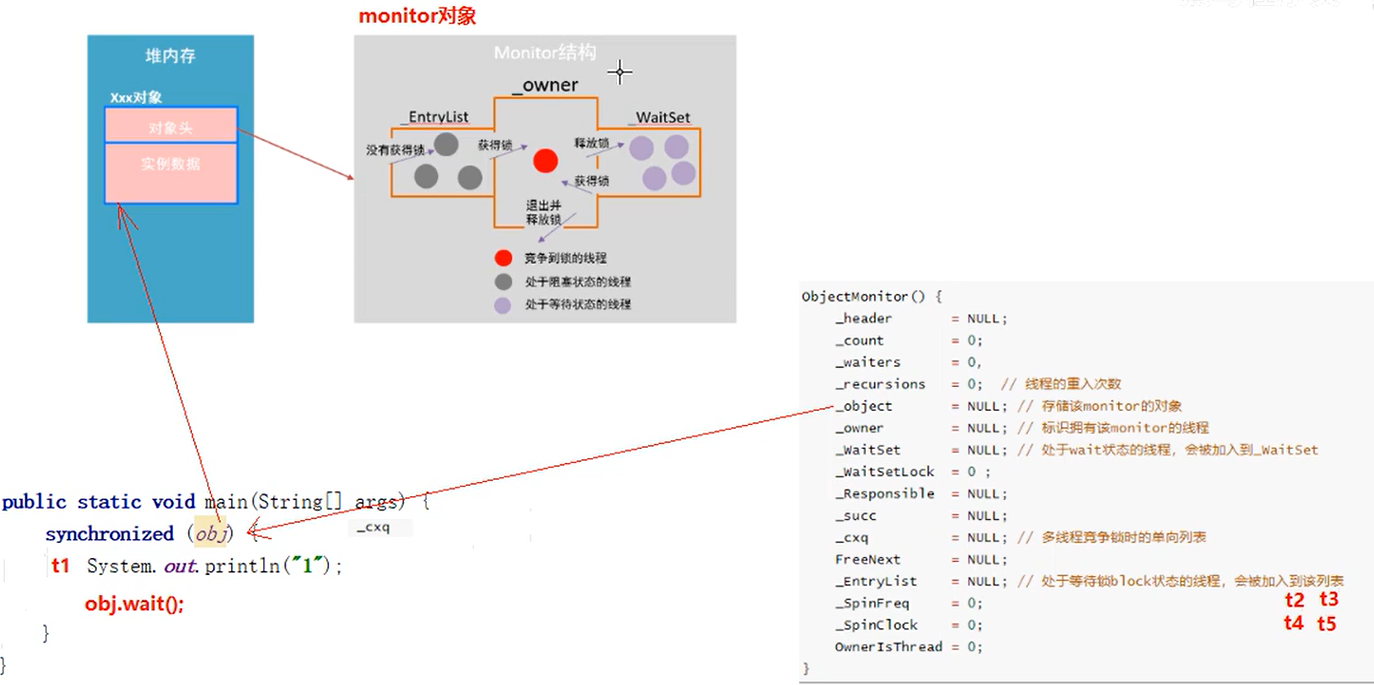
上图解析:
等待一轮之后依旧没有抢到锁的线程被放置到
_EntryList当中;执行
obj.wait()方法的线程会被放置到_WaitSet单项列表中去,并释放锁;当线程拥有者(owner)在执行完成任务出同步代码块释放锁时,有可能是当前释放锁的线程(重入锁),有可能会是
_EntryList当中正在阻塞的线程竞争获取拿到锁变成monitor当中的_owner,也有可能会是_WaitSet当中处于Wait的线程被别的操作所唤醒了,他有可能拿到锁变成monitor当中的_owner。总结:能够竞争得到锁的线程有当前刚释放锁的线程(重入锁)、处于阻塞状态的线程、处于等待状态的线程。
小结
每一个java对象都可以与一个监视器 monitor关联,当一个线程想要执行一段被synchronized圈起来的同步方法或者代码块时,该线程得先获取到 synchronized 修饰的对象 obj 对应的 monitor。
java代码里不会显式地去创造这么一个 monitor对象,也无需创建,monitor并不是随着对象创建而创建的,是通过 synchronized 修饰符告诉 JVM 需要为 某个对象创建关联的 monitor对象。
ObjectMonitor 的构造器包含三种队列: _cxq、_WaitSet和 _EntryList。
monitor 竞争
锁竞争对应的底层c++代码的具体流程为:
- 通过CAS尝试把
monitor的_owner字段设置为当前线程; - 如果设置之前的
_owner指向的就是当前线程,说明当前线程再次进入monitor,即重入锁,执行recursions++,记录重入的次数;(如果在这之前的上一次竞争当前线程获取到了该锁,那么本次竞争中当前线程又竞争到了该锁;两把锁一样;那么说明是锁重入) - 如果当前线程是第一次进入该monitor,设置
recursions为1,_owner为当前线程,该线程成功获得锁并返回; - 如果获取锁失败,则等待锁的释放(进入阻塞状态,即进入到monitor对象的成员变量
_cxq单向队列,然后再进入_EntryList中);
monitor等待
未获取锁的线程会被放到_cxq单向列表中去阻塞,阻塞等待对应的底层c++代码的具体流程:
1、当前线程被封装成ObjectWaiter对象node,状态设置成ObjectWaiter::TS_CXQ;
2、 在for循环中(用CAS尝试把当前该线程放到_cxq的一个节点上去,因为同时有多个线程往单向列表_cxq当中放,所以使用了for循环,CAS多次尝试),通过CAS把node节点push到_cxq列表中,因为同一时刻可能有多个线程把自己的node节点push到_cxq列表中;
3、 (没有抢到锁的线程在放到_cxq节点上之前)node结点push到_cxq列表之后,通过自旋尝试获取锁,如果还是没有获取得到锁,则通过park将当前线程挂起(park内核函数,让当前线程挂起,其实也就相当于阻塞状态,需要别的线程进行唤醒才能够继续往下执行),等待被唤醒。
4、 当该线程被唤醒时,会从挂起的点继续执行,通过ObjectWaiter::TryLock尝试获取锁;
monitor释放
当某个持有锁的线程执行完同步代码块时,会进行锁的释放,给其他线程执行同步代码块的机会,并通知被阻塞的线程。
Q:什么时候释放monitor?
A:获得锁的线程t1执行完同步代码块之后,就需要出同步代码块,在出同步代码块的时候就会进行monitor的释放操作。
Q:monitor释放的过程是怎么样的?
A:释放锁时会唤醒之前正在等待阻塞中的线程,详细过程如下:
- 释放monitor时,如果
_recursions计数器不等于0,则执行减一操作,这个对应可重入锁;如果_recursions等于0,则表示线程完全出了同步代码块, 且把锁释放返回了;- 除了释放锁之外,还要去唤醒之前正在等待阻塞中的线程,唤醒哪一个呢?
- 此时,有两个链表当中都存放有需要被唤醒的线程,一个是
_cxq,另外一个是EntryList,随机唤醒两个链表中的某一个线程,唤醒操作通过调用unpack()完成。
为什么 monitor 是重量级锁?
synchronized 代码块在执行的时候,会涉及到大量的内核函数执行,就会存在操作系统的用户态和内核态进行切换(状态切换消耗的时间 有可能比 用户代码执行的时间还要长),这种切换就会消耗大量的系统资源,这就是 synchronized 未优化之前,效率低的原因(属于重量级锁)。
ObjectMonitor的函数调用中会涉及到
Atomic::cmpxchg_ptr,Atomic::inc_prt等内核函数,执行同步代码块,没有竞争到锁的线程会调用park()被挂起,竞争到锁的线程执行完成退出同步代码块时(即当其他线程退出同步代码块时)会调用unpark()唤醒上次那些没有竞争到锁从而被park()挂起的线程;这个时候就会存在操作系统用户态和内核态的转换,这种切换会消耗大量的系统资源。注:这几个方法都属于内核函数,而内核函数的执行就会涉及到操作系统中用户态和内核态的一个切换
Linux的体系结构
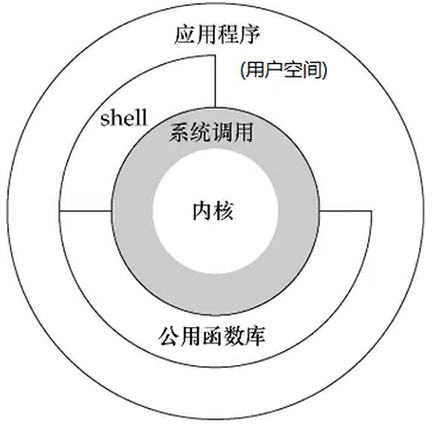
linux系统的体系架构由内核、系统调用、shell、公用函数库和应用程序这几个部分组成。
操作系统的内核:内核本质上也是一种应用程序,作用是来控制计算机的硬件资源的,比如说控制硬盘、内存、网络等相关的一些硬件设备比如说网卡、声卡、键盘、鼠标等;
应用程序:自己写的程序被称为普通的应用程序;用户空间其实指的是自己所编写的应用程序所运行的那一块内存空间。
linux操作系统的体系架构分为:用户空间(应用程序的活动空间)和内核。
- 用户空间:上层应用程序活动的空间。应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等;
- 内核:本质上可以理解为一种软件,控制计算机的硬件资源,并提供上层应用程序运行的环境;
- 系统调用:为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用;
- 所有进程初始都运行于用户空间,此时即为用户运行状态(简称:用户态);
“系统调用”拓展:
Ⅰ. 当应用程序需要用到键盘、需要去读取文件、需要通过网络去发送一些资源的时候,其实说白了也就是需要用到计算机的一些硬件资源时,这时就需要通过系统调用到内核来帮助执行;
Ⅱ. 普通的应用程序在用户空间当中运行,那么就称之为用户态;当应用程序如果需要调用内核的一些功能,即通过系统调用来进行调用内核当中的一些功能;那么这个时候应用程序就会进入内核态;
Ⅲ. 用户态与内核态的切换是需要系统调用来进行的;
系统调用过程
- 首先应用程序属于用户态,即将调用内核函数的时候,那么应用程序会把现在程序的一个运行状态,主要是程序运行的一些运行数值进行保存,可能会保存在寄存器当中,也有可能使用参数创建一个堆栈来保存现在应用程序的一些运行信息和运行参数;
- 接着用户态的应用程序就会来进行执行系统调用;
- 经过系统调用之后,CPU就会切换到内核态;然后到内存当中指定的位置去执行相关指令;
- 接着,系统调用处理器(system call handler)会读取程序放入内存的数据参数,然后会执行相应的内核函数以及请求一些内核的服务;
- 系统调用完成后,操作系统会重置CPU为用户态并返回系统调用的结果。
用户态切换至内核态 需要传递许多变量,同时内核还需要保护好用户态在切换时的一些寄存器值、变量等,以备内核态切换回用户态。这种切换就带来了大量的系统资源消耗,这就是synchronized未优化之前,效率低的原因(属于重量级锁)。
CAS_AtomicInteger
CAS的全称是 Compare And Swap(比较再交换),确切一点称之为:比较并且相同再做交换,是现代CPU广泛支持的一种对内存中的共享数据进行操作的一种特殊指令。
CAS的作用是可以保证共享变量赋值时的原子操作,这个原子操作直接由处理器CPU保证。
CAS在操作时依赖三个值:内存中的值V、旧的预估值X、要修改的新值B。如果旧的预估值X等于内存中的值V(读取到修改这段时间内没有其他线程来修改),就将新的值B保存到内存中,替换这个内存中的值V。
java当中已经提供好了一个类叫做AtomicInteger,这个类的底层使用的就是CAS;
存在并发安全的代码:
public class Demo01{
// 定义一个共享变量 num
private static int num = 0;
public static void main(String[] args)throws InterruptedException{
// 任务:对 num 进行1000次加操作
Runnable mr = ()->{
for(int i = 0; i < 1000; i++){
num++; // num++并不是原子操作,就会导致原子性问题的产生
}
};
ArrayList<Thread> ts = new ArrayList<>();
// 同时开辟5个线程执行任务
for( int i=0; i < 5 ; i++){
Thread t = new Thread(mr);
t.start();
ts.add(t);
}
for(Thread t : ts){
t.join();
}
System.out.println("num = " + num);
}
}
改用原子自增类:
public class Demo01{
public static void main(String[] args)throws InterruptedException{
//
AtomicInteger atomicInteger = new AtomicInteger();
// 任务:自增 1000 次
Runnable mr = ()->{
for(int i = 0; i < 1000; i++){
atomicInteger.incrementAndGet(); //该自增操作是一个原子性的操作
}
};
ArrayList<Thread> ts = new ArrayList<>();
for( int i=0; i < 5 ; i++){
Thread t = new Thread(mr);
t.start();
ts.add(t);
}
for(Thread t:ts){
t.join();
}
System.out.println("number = " + atomicInteger.get());
}
}
CAS原理
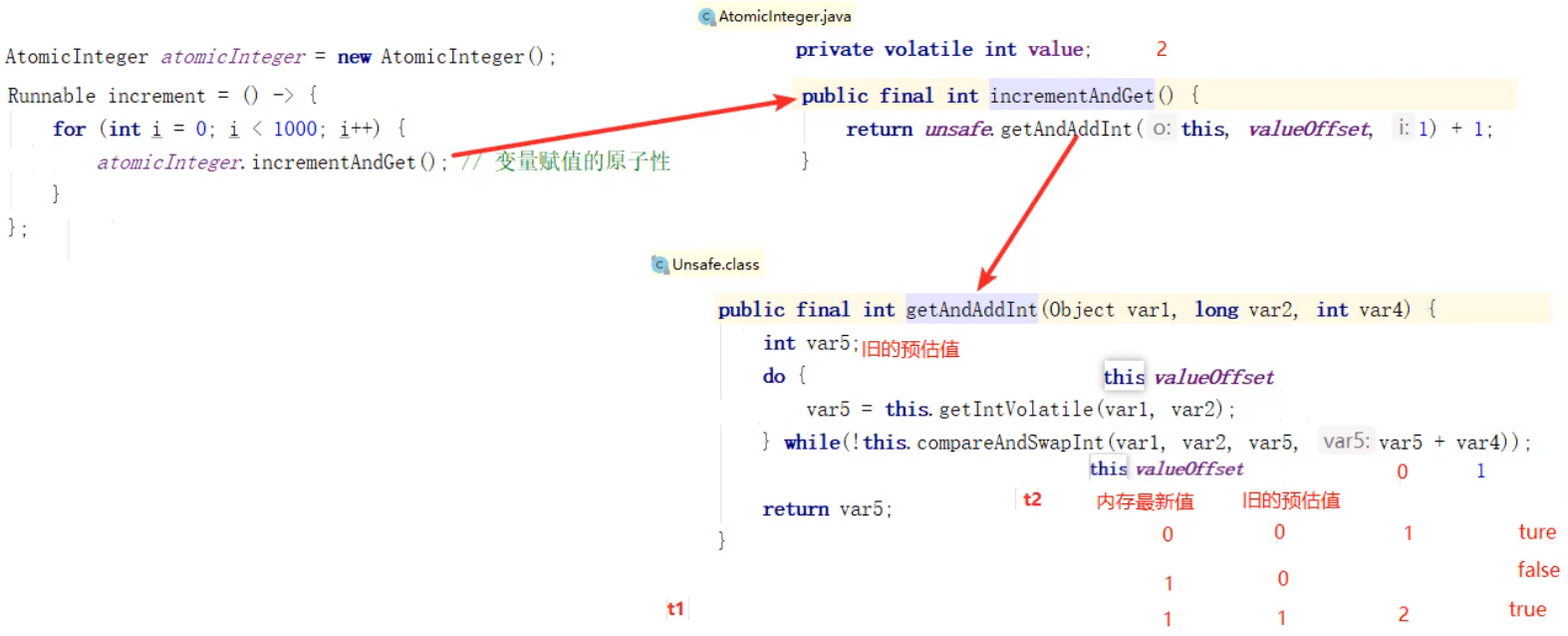
AtomicInteger类当中其内部会包含一个叫做UnSafe的类,该类可以保证变量在赋值时的原子操作;
Unsafe类使java拥有了像C语言的指针一样操作内存空间的能力(操作对象的内存空间即能够操作对象里面的内容,但是这个UnSafe类不太安全,如果使用不当会很危险,所以java官方并不推荐使用,并且在jdk当中也无法找到此类,该类不能直接调用,只能够通过反射的方式才能够找到该类),同时也带来了指针的问题。
底层源码:
/* AtomicInteger.java */
private volatile int value; // value初始取值为0
public final int incrementAndGet(){
// this:自己 new 好的 atomicInteger对象
// valueOffset:内存偏移量
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
/* Unsafe.class */
// var1:上面的this,即atomicInteger对象; var2:valueOffset
public final int getAndAddInt(Object var1, long var2, int var4){
// var5 旧的预估值
int var5;
do {
// this 和 内存 valueOffset,目的是找出这个 value的当前最新值(旧的预估值)
var5 = this.getIntVolatile(var1 , var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
方法解析:
通过 var1 和 var2 找出内存中 value共享变量的最新值;
var5 是旧的预估值,其实就是执行到
getIntVolatile(var1 , var2)时,此时读到的内存最新值;如果内存最新值和旧的预估值相等,就把 var5 + var4 (var5自增1的值)赋给共享变量 value,这个方法
compareAndSwapInt也会返回 true,该线程结束循环;如果内存最新值和旧的预估值不等,不等的话就不会把 var5 + var4 (var5自增1的值)赋给共享变量 value,并且返回 false,继续while,再次进行比较;
先读取内存中的值(通过var1和var2得到),赋给var5,然后判断条件,执行compareAndSwapInt,看内存中最新的值(通过var1和var2得到)是否和方才读取到的var5相等,相等,就自增并赋给共享变量value;不等,就再次循环进行比较。
乐观锁 & 悲观锁
悲观锁 从悲观的角度出发:
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁(这样就只有一个线程进来,别的线程没有锁无法进入,即别的线程会阻塞,那么也就保证数据操作没有问题),这样别人想拿这个数据就会阻塞。
synchronized、JDK中的ReentrantLock都是一种悲观锁。
乐观锁 从乐观的角度出发:
总是假设最好的情况,每次去拿数据时都认为别人不会修改,就算改了也没关系,再重试即可。所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去修改这个数据,如果没有人修改则更新,如果有人修改则重试,重新去获取内存中的最新值。
无锁并发
CAS 可以保证对共享变量操作的原子性,而volatile可以实现可见性和有序性,结合CAS和volatile可以实现无锁并发,适用于竞争不激烈,多核CPU的场景下。
- CAS之所以效率高是因为在其内部没有使用synchronized关键字,CAS不会让线程进入阻塞状态,那么也就避免了synchronized当中用户态和内核态的切换所带来的的性能消耗问题,也避免了线程挂起等问题。
- 如果竞争非常激烈,那么CAS就会出现线程大量重试,因为多线程来进行竞争,那么也就导致有可能很多的线程设置取值失败,那么又要进行while循环重试,即大量的线程进行重试操作,成功存的线程反而不多,那么这样的话反而会使性能大大降低。所以如果竞争太激烈还使用的是CAS机制,会导致其性能比synchronized还要低。
小结
CAS指的是Compare And Swap,CAS可以将比较和交换转换为原子操作,这个原子操作直接由处理器保证(由CPU支持),会拿旧的预估值与内存当中的最新值进行比较;如果相同就进行交换并且把最新的值赋值到内存当中的这个变量;
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现【比较并交换】的效果。
使用CAS时,线程数不要超过CPU的核心数,每个CPU核心都能同时并行某个线程,超过的话想运行也运行不了,得发生上下文切换。线程的上下文切换的成本很高,要保存线程的信息,当从阻塞恢复成可运行,还要恢复线程的信息。
synchronized锁升级过程()
在JDK1.5之前synchronized只包含有一种锁,即monitor重量级锁,所以在JDK1.5之前其效率是比较低的,因此在JDK1.6这个版本当中对synchronized做了重要改进,在JDK1.6当中synchronized就不仅仅只有monitor这一种重量级的锁了,包括偏向锁、轻量级锁、适应性自旋、锁消除、锁优化等机制,另外到转变成重量级锁之前会有一个适应性自旋的过程进行抢救一下,这些机制的目的就是为了能够让synchronized的效率得到提升。
无锁 → 偏向锁 → 轻量级锁 → 重量级锁
首先对象是无锁状态,如果需要进行加锁,那么就会添加一个偏向锁,如果偏向锁无法满足的话就会换成轻量级锁,如果轻量级锁不行的话就有可能会进入适应性自旋的过程,如果通过适应性自旋依然没有抢到锁则换成重量级锁。
JVM中对象的布局
JVM中,Java对象在内存中的布局总共由三部分组成:对象头、实例数据(成员变量等)和对齐填充;
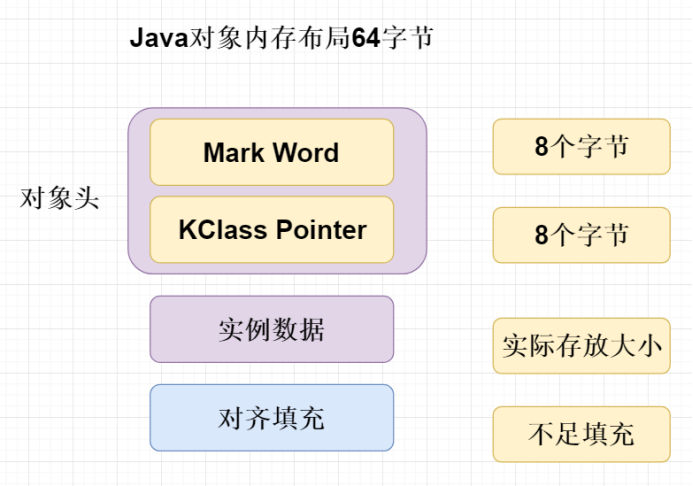
对象头
对象头由两部分组成,分别是 Mark Word 和 Klass pointer,synchronized 锁可能有很多状态,这些状态都是靠对象头来存储的。
在Hotspot虚拟机当中对象头又分为两种,一种是普通对象的对象头即instanceOopDesc,另外一种是描述数组的对象头即arrayOopDesc,当前我们仅关心普通对象的对象头即instanceOopDesc。instanceOopDesc的定义是在Hotspot源码的 instanceOop.hpp 文件中,另外, arrayOopDesc的定义对应 arrayOop.hpp。
instanceOop继承了父类oopDesc,oopDesc的定义在Hotspot源码中的 oop.hpp文件中;
class oopDesc{
friend class VMStructs;
private :
volatile markOop _mark;
union _metadata{
Klass* _klass; # 没有开启指针压缩时的类型指针
narrowKlass _compressed_klass; # 开启了指针压缩
} _metadata;
// Fast access to barrier set. Must be initialized.
static BarrierSet* _bs;
// 省略其他代码
};
oopDesc中包含了两个成员,分别是
_mark和_metadata:
_mark表示对象标记、属于markOop类型,也就是Mark Word,它记录了对象和锁有关的信息;_metadata表示类元信息,类元信息存储的是对象指向它的类元数据(Klass)的首地址,其中Klass表示普通指针;
MarkWord
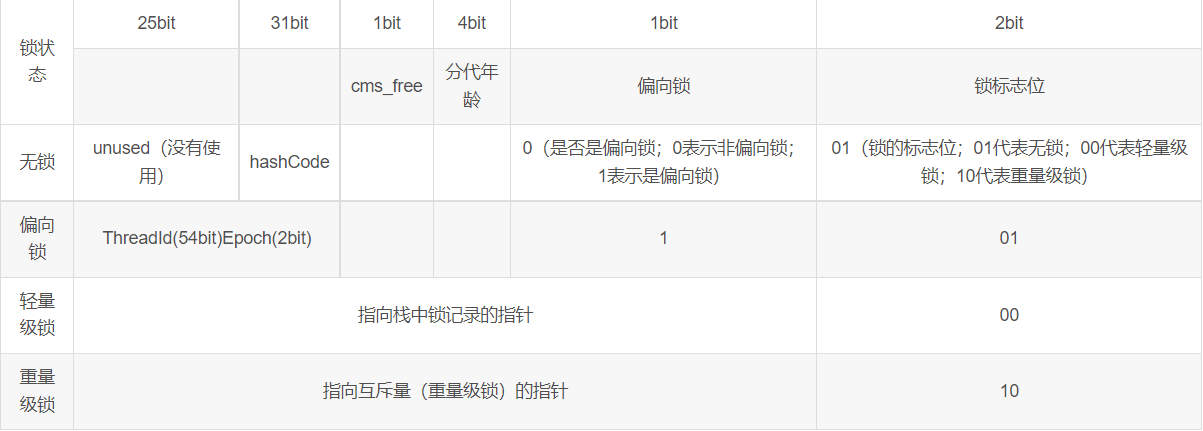
Mark Word用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,占用内存大小与虚拟机位长一致。
Mark Word对应的类型是markOop,源码位于 markOop.hpp中。
在64位虚拟机下,Mark Word是 64bit 大小的,其存储结构如下:
Klass pointer
java当中的对象肯定是由某个类所产生的,那么Klass pointer就是用来表示该对象是哪一个类所产生的。Klass pointer会保存这个类的元信息,如果是64位虚拟机,则其Klass pointer的大小为64位。
如果应用的对象过多,使用64位的指针将大量浪费内存,统计而言,64位的 JVM 将会比32位的 JVM 多耗费50%的内存。为了节约内存可以使用选项-XX:+UseCompressedOops开启指针压缩(JVM默认开启),开启该选项后,下列指针将压缩至32位:
- 每个Class的属性指针(即静态变量);
- 每个对象的属性指针(即成员变量);
- 普通对象数组的每个元素指针
对象头 = Mark Word + 类型指针(未开启指针压缩的情况下)
- 在32位系统中,Mark Word = 4 bytes, 类型指针 = 4bytes, 对象头 = 8bytes = 64 bits;
- 在64位系统中,Mark Word = 8 bytes, 类型指针 = 8bytes, 对象头 = 16bytes = 128 bits;
开启指针压缩:
- 在64位系统中,Mark Word = 8 bytes, 类型指针 = 4bytes, 对象头 = 12bytes ;
实例数据
对象真正存储的有效信息,也是在类中定义的各种类型的字段内容;
对齐填充
不是必然存在的,也没有什么特别的含义,仅仅起占位作用。因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
对齐填充可能有可能没有,如果java对象整体大小为8字节的整数倍,那么就不需要对齐填充;如果不是,则需要填充一些数据使之对齐,从而保证是8字节的整数倍。这么做是方便操作系统来进行寻址。
查看对象布局
openjdk提供了一个工具jol-core,可以查看Java的对象布局。
引入依赖:
<dependency>
<groupId>org.openjdk.jol</groupId>
<aratifactId>jol-core</aratifactId>
<version>0.9</version>
</dependency>
举个例子:
import org.openjdk.jol.info.ClassLayout;
public class LockObj{
private int x;
}
class Demo01{
public static void main(String[] args){
LockObj obj = new LockObj();
//parseInstance 解析实例对象;
//toPrintable进行打印其解析的实例对象信息
ClassLayout.parseInstance(obj).toPrintable();
}
}
输出内容:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)
12 4 int LockObj.x 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
对象头(object header)占用了12个字节,上文也提到过,这是因为JVM默认自动开启了指针压缩的选项参数,所以打印对象布局中的对象头信息所占字节为12个字节而不是16个字节。如果尝试关闭指针压缩(JVM默认就是开启指针压缩的),配置 -XX:-UseCompressedOops,再次打印对象布局:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) d8 34 5a 25 (11011000 00110100 01011010 00100101) (626668760)
12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
16 4 int LockObj.x 0
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
可以看到对象头(object header)占用了16个字节,然后整型变量 x 占用4个字节,这两项共20个字节。根据“对齐填充”,对象的大小必须是 8 字节的整数倍,所以此时得再填充4个字节的数据(最后一行),整个对象占24个字节。
偏向锁
定义
HotSpot作者经过研究实践发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得(即由同一个线程反复的重入得到锁释放锁,如果一上来就是重量级锁的话,那么得到锁和释放锁都需要消耗一定的性能)为了让线程获得锁的代价更低,引进了偏向锁,减少不必要的CAS操作。
偏向锁的“偏”,就是偏心的“偏”、偏袒的“偏”,它的意思是这个锁会偏向于第一个获得它的线程,会在对象头存储锁偏向的线程ID,以后该线程进入和退出同步块时只需要检查是否为偏向锁、锁标志位以及ThreadID即可。
不过一旦出现多个线程竞争时,必须撤销偏向锁,所以撤销偏向锁消耗的性能必须小于之前节省下来的CAS原子操作的性能消耗,不然就得不偿失了。
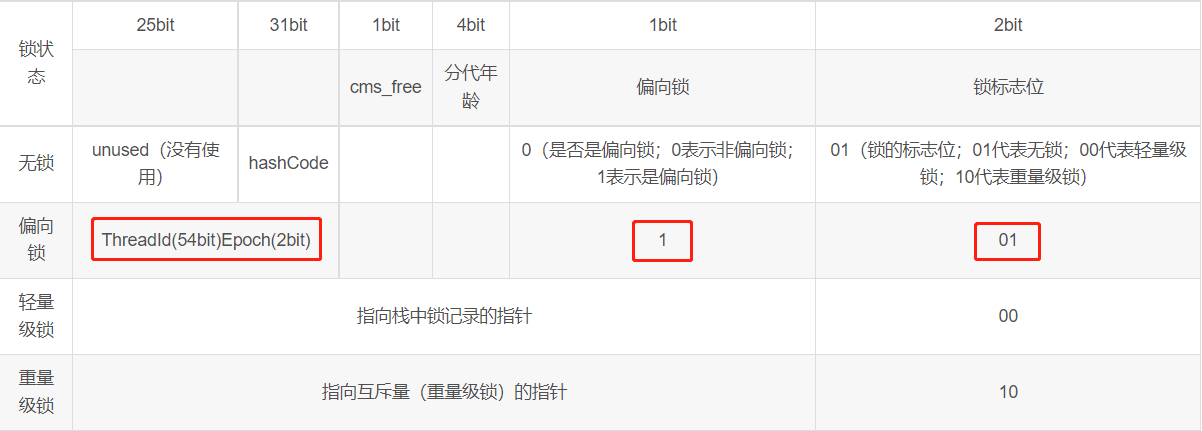
根据上图64 bit的 Mark Word可知,如果是偏向锁,则偏向标志位变成1,锁标志位变成01,另外由前面56位当中的前54位会来保存当前线程的ID,另外两位用来保证Epoch即时间;
注意:这个偏向锁仅限用于没有竞争的状态,也就是说反复是同一个线程获得锁释放锁。
举个例子:
import org.openjdk.jol.info.ClassLayout;
public class Demo01{
public static void main(String[] args){
// 创建一个线程
MyThread mt = new MyThread();
mt.start();
}
}
class MyThread extends Thread{
static Object obj = new Object();
@Override
public void run(){
// 任务:循环5次
for( int i = 0; i < 5; i++){
synchronized(obj){
// ...
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}
}
}
// 循环5次并且进出同步代码块就只有一个线程;那么这种情况就适合使用偏向锁
// 即反复是同一个线程进入同步代码块的情况,但是如果遇到有线程来进行竞争,立即要撤销掉偏向锁从而升级到轻量级锁;
加锁原理(面试必背)
偏向锁的核心原理是:
- 如果不存在线程竞争,当某个线程获得了锁,那么锁就进入偏向状态,此时Mark Word的结构变为偏向锁结构,锁对象的锁标志位(lock)被改为01,偏向标志位(biased_lock)被改为1,然后线程的ID记录在锁对象的Mark Word中(使用CAS操作完成)。以后该线程获取锁时判断一下线程ID和标志位,就可以直接进入同步块,连CAS操作都不需要,这样就省去了大量有关锁申请的操作,从而提升了程序的性能;
- 但是,一旦有第二条线程需要竞争锁,那么偏向模式立即结束,进入轻量级锁的状态;
- 假如在大部分情况下同步块是没有竞争的,那么可以通过偏向来提高性能。在无竞争时,之前获得锁的线程再次获得锁时会判断偏向锁的线程ID是否指向自己:
- 如果是,那么该线程将不用再次申请获得锁,直接就可以进入同步块;
- 如果未指向当前线程,当前线程就会采用CAS操作将Mark Word中的线程ID设置为当前线程ID:
- 如果CAS操作成功,那么获取偏向锁成功,执行同步代码块;
- 如果CAS操作失败,那么表示有竞争,抢锁线程被挂起,撤销占锁线程的偏向锁,然后将偏向锁膨胀为轻量级锁。
当线程第一次访问同步代码块并获取锁时,偏向锁处理流程如下:
- 检测Mark Word中对象头是否为 可偏向状态,即是否为偏向锁1,锁标识是否为01;
- 若为 可偏向状态,则看Mark Word中的线程ID是否为当前线程ID,如果是,执行同步代码块,否则执行步骤(3);
- 如果线程ID不为当前线程ID,则通过CAS操作将Mark Word的线程ID替换为当前线程,执行同步代码块,偏向锁膨胀为轻量级锁;
偏向锁的撤销
假如有多个线程来竞争偏向锁,此对象锁已经有所偏向,其他的线程发现偏向锁并不是偏向自己,就说明存在了竞争,尝试撤销偏向锁(很可能引入安全点),然后膨胀到轻量级锁。
所以,如果某些临界区存在两个及两个以上的线程竞争,那么偏向锁反而会降低性能。在这种情况下,可以在启动JVM时就把偏向锁的默认功能关闭。
import org.openjdk.jol.info.ClassLayout;
public class Demo01{
public static void main(String[] args){
MyThread mt = new MyThread();
mt.start();
/**
两个线程去进行run()当中的synchronized;
那么两个线程来执行的时候就需要将该偏向锁给撤销;
*/
MyThread mt2 = new MyThread();
mt2.start();
}
}
class MyThread extends Thread{
static Object obj = new Object();
@Override
public void run(){
for( int i = 0; i < 5; i++){
synchronized(obj){
// ...
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}
}
}
- 偏向锁的撤销动作必须等待全局安全点;
- 暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态;
- 撤销偏向锁,之后可以恢复到无锁(标志位为01)或轻量级锁(标志位为00)的状态;
这个全局安全点是指,在这个点的时候所有的线程都会停下来,叫做全局安全点。只有到了全局安全点的时候才能来撤销偏向锁;
偏向锁 在 jdk1.6 之后是默认启用的,但是有延迟,要在应用程序启动几秒钟才激活,可以使用-XX:BiasedLockingStartupDelay=0参数关闭延迟。
如果确定应用程序所有锁通常情况下确实处于竞争状态,可以通过-XX:-UseBiasedLocking = false参数关闭偏向锁。
偏向锁的优缺点
优点:
偏向锁适合在只有一个线程来获取锁的时候使用,即没有竞争情况下,一个线程反复进入同步代码块退出同步代码块的效率是很高的,只要进行判断对象头中的线程id(THREAD ID)跟现在要获取锁的线程的THREAD ID是否相同即可。如果ID相同则进入同步代码块,退出同步代码块时也不需要做什么事情,所以性能高。
缺点:
如果存在有很多的线程来竞争锁,那么这个时候偏向锁就起不到什么作用了,反而会影响效率。因为每次撤销一次偏向锁,都必须要等待全局安全点,所有线程都会停下来才能够进行撤销偏向锁。
补充
比如说使用线程池来执行代码的时候,线程池当中肯定有多个线程反复去执行同样的任务,多个线程会反复去竞争同一把锁,那么这时使用偏向锁就是多余的了。
注意在 JDK1.5 的时候偏向锁是默认关闭的,而在 JDK1.6 的时候偏向锁是默认开启的,如果不需要偏向锁可以通过启动参数-XX:-UseBiasedLocking=false来进行关闭偏向锁,让其直接进入重量级锁。
轻量级锁
定义
当偏向锁出现竞争的时候,会撤下偏向锁从而升级到轻量级锁,轻量级锁是JDK1.6当中为了优化synchronized而引入的一种新型锁机制,“轻量级”是相对于使用monitor的传统锁(重量级)而言的。轻量级锁并不能够用来代替重量级锁,轻量级锁只是在一定的情况下来减少消耗。
引入轻量级的目的
在多线程交替执行同步块的情况下,引入轻量级锁可以减少重量级锁引起的性能消耗,但是如果多个线程在同一时刻进入临界区,会导致轻量级锁膨胀升级重量级锁,所以轻量级锁的出现并非是要代替重量级锁,也就是说在多线程交替执行(多个线程加锁时间是错开的)同步块的时候,轻量级的性能才是比较好的。
轻量级锁适用场景
适用于少量线程竞争锁对象,且线程持有锁的时间不长,追求响应速度的场景;
什么时候会尝试获取轻量级锁
- 当关闭偏向锁功能(JDK1.6默认开启,可通过启动参数来关闭偏向锁) ;
- 或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁时,则会尝试获取轻量级锁。
原理
class MyThread extends Thread{
static Object obj = new Object();
@Override
public void run(){
synchronized(obj){
// ...
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}
}
当关闭偏向锁功能 或者 多个线程竞争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁,其获取锁步骤如下:
- 判断当前对象obj 是否处于无锁状态(hashcode、0、01),如果是,则JVM首先将在当前线程的栈帧中建立一个锁记录(Lock Record)空间,用于存储锁对象目前的Mark Word的拷贝(官方把这份拷贝加了一个Displaced前缀,即Displaced Mark Word),将锁对象的Mark Word复制到栈帧中的Lock Record中,将Lock Record的
owner指向当前锁对象(synchronized括号中的锁对象); - JVM利用CAS操作尝试将对象的Mark Word(前62位)更新为指向Lock Record的指针;如果CAS成功,表示竞争到锁,则将锁标志位(后两位)变成00,执行同步操作;
- 如果CAS失败,则判断当前对象的Mark Word()是否指向当前线程的栈帧,如果是则表示当前线程已经持有当前对象的锁,直接执行同步代码块;否则,只能说明该锁对象已经被其他线程抢占了,这时轻量级锁需要膨胀为重量级锁,锁标志位变为10,后面等待的线程就会进入阻塞状态。
LockRecord是线程私有的,每个线程有自己的一份锁记录,在创建完锁记录空间后,会将当前锁对象的MarkWord拷贝到锁记录中(Displaced Mark Word)
|---------------------------------------------------------------------------------|--------------------|
| Mark Word(64 bits) | State |
|---------------------------------------------------------------------------------|--------------------|
| unused:25 | identity_hashcoder:31 | unused:1 | age:4 | biased_lock:1 | lock:2 | Normal |
|---------------------------------------------------------------------------------|--------------------|
| thread:54 | epoch:2 | unused:1 | age:4 | biased_lock:1 | lock:2 | Biased |
|---------------------------------------------------------------------------------|--------------------|
| ptr_to_lock__record:62 | lock:2 | Lightweight Locked |
|---------------------------------------------------------------------------------|--------------------|
| ptr_to_heavyweight_monitor:62 | lock:2 | Heavyweight Locked |
|---------------------------------------------------------------------------------|--------------------|
| | lock:2 | Marked for GC |
|---------------------------------------------------------------------------------|--------------------|
释放轻量级锁
轻量级锁的释放也是通过CAS操作来进行的,主要步骤如下:
- 取出在获取轻量级锁时保存在
Displaced Mark Word中的数据; - 用CAS操作 将取出的数据 替换当前对象的Mark Word,如果成功,则说明释放锁成功;
- 如果CAS操作替换失败,说明有其他线程尝试获取该锁,则需要将轻量级锁需要膨胀升级为重量级锁;
轻量级锁的释放就是把栈帧中的Lock Record中的displaced hdr中的hashCode、分代年龄以及锁标志位等都重新放回到对象头原有的位置上,即无锁状态时的对应bit处。
撤销轻量级锁也是一个CAS操作,即如果将hashCode、分代年龄以及锁标志位都还原归位了,那也就说明轻量级锁已经被撤销了。
小结
对于轻量级锁而言,轻量级锁的性能之所以高,是因为在绝大部分情况下,这个同步代码块不存在有竞争的状况,线程之间交替执行。
如果是多线程同时来竞争这个锁的话,那么这个轻量级锁的开销也就会更大,导致轻量级锁膨胀升级为重量级锁。
轻量级锁的原理:
轻量级锁会在栈帧(执行的方法)中创建一个叫做
Lock record锁记录空间,锁记录空间内的displaced hdr会去保存对象头中的hashCode、分代年龄以及锁标志等,另外锁记录空间当中的owner指向的是这个锁对象;并且在对象头中会保存Lock Record锁记录的空间地址,然后将对象头当中的锁标志改成00以表示轻量级锁。
轻量级锁的好处是什么?
- 在多线程交替执行同步块的情况下,可以避免直接升级为重量级锁引起的性能消耗。
自旋锁
引入背景
- 之前说过monitor获取锁 的时候,会阻塞和唤醒线程,线程的阻塞和唤醒 需要CPU从用户态转化为内核态,频繁的阻塞和唤醒对CPU来说 是一件负担很重的工作,这些操作给系统的并发性能 带来了很大的压力。
- JVM开发团队也注意到在许多应用上,共享数据的锁定状态(临界区资源)只会持续很短的一段时间,为了这段时间阻塞和唤醒线程并不值得。
- 如果机器上有多个CPU,能让两个或两个以上的线程同时并发执行,就可以让后面请求锁的那个线程循环 “稍等一下”,但不放弃处理器的执行时间,看看持有锁的线程 是否很快就会释放锁。
简述
自旋锁在 JDK 1.4.2 中就已经引入,只不过默认是关闭的,可以使用-XX:+UseSpinning参数来开启,在 JDK 6 中就已经改为默认开启了。
自旋等待不能代替阻塞,且先不说处理器数量的要求,自旋等待本身虽然避免了线程切换的开销,但它是要占用处理器时间的。
因此,如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白白消耗处理器资源,而不会做任何有用的工作,反而会带来性能上的浪费。
所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程,让线程阻塞。自旋次数的默认值是10次,用户可以使用参数-XX:PreBlockSpin来更改。
使用自旋的条件
- 同步代码块执行时间较短,从而能够很快的抢到锁;
- CPU硬件要能够支持两个或两个以上的线程并行执行,不是并发,是并行。一个线程在同步代码块内执行,而另一个线程则在同步代码块外进行自旋尝试获取锁;
自旋的优缺点
使用自旋锁可以防止线程阻塞和唤醒中要进行的状态切换(CPU从用户态切换至内核态的),减轻CPU的开销。
自旋也是会消耗CPU的性能的,需要在同步代码块外层不断的进行循环重试获取锁,
- 如果自旋的次数太多了那么对于CPU的开销也是很大的;
- 如果自旋的次数太少了又有可能抢不到锁导致白白自旋了(因此,自旋锁默认的自旋次数是10次)。
所以在1.6中引入了下面的自适应自旋锁。
自适应自旋锁
在JDK 6中引入了自适应的自旋锁。自适应意味着自旋次数或自旋时间不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
举个例子:
1)假设一个线程A在同步代码块上,自旋了10次并且获得了锁,那么就会认为这个同步代码块通过自旋是比较容易获得锁的。所以在后续的执行过程中也会进行自旋,并且还允许自旋的时间稍微长一点,因为之前自旋得到过,所以感觉现在也能得到,所以自旋的时间还允许更长一点;
2)假设有一个同步代码块,但是自旋从来就没有在这个同步代码块上成功获取过锁过,所以jvm就会认为这个同步代码块很难通过自旋获取到锁,干脆就不再进行自旋了,这样就可以避免自旋导致性能的浪费;
锁消除
锁消除 是指 虚拟机 即时编译器(JIT)在 运行时,对一些代码上要求同步,但是被检测到 不可能存在共享数据竞争的锁 进行消除。
锁消除 的主要判定依据 来源于 逃逸分析的数据支持,在一段代码中,堆上的所有数据(对象) 都不会逃逸出去 从而被其他线程 访问到,那就可以把它们当做栈上数据对待,认为它们是线程私有的,同步加锁 自然就无需进行。
举个例子:
public class Demo01{
public static void main(String[] args){
concatString("aa" , "bb" , "cc");
}
public static String concatString(String s1, String s2, String s3){
return new StringBuffer().append(s1).append(s2).append(s3).toString();
}
}
// ---------------------------------- append() 方法的源码
@Override
public synchronized StringBuffer append(String str){
toStringCache = null;
super.append(str);
return this;
}
StringBuffer的append()方法使用了synchronized进行了同步处理,修饰实例方法,作用于当前实例,进入同步代码前需要先获取实例的锁。
concatString方法中调用了三次append方法,new StringBuffer()对象并没有逃逸出concatString()这个方法,因为不管来几个线程,每个线程都会以new StringBuffer()对象作为锁来锁住StringBuffer类的append()方法,每个线程获取的是不同的锁对象。
既然不存在竞争,那么这个StringBuffer类当中的 append() 方法的同步代码块synchronized就没有必要了,所以会自动消除掉这个synchronized。
锁粗化
JVM会探测到一连串细小的操作都是对同一个对象加锁,将同步代码块的范围放大,放到这串操作的外面,那么这样只需要加一次锁即可。
public void Demo01{
public static void main(String[] args){
StringBuffer sb = new StringBuffer();
for( int i = 0; i < 100; i++){
sb.append("aa");
}
System.out.println(sb.toString());
}
}
// ------------------------------ append() 方法的源码 ----------------------------
@Override
public synchronized StringBuffer append(String str){
toStringCache = null;
super.append(str);
return this;
}
以上main中会调用append方法100次,每次调用append都会进入到一个同步方法中,那么这个性能消耗也是比较大的,jvm会对锁粗化处理,将StringBuffer.append()方法当中的synchronized进行消除掉,然后再将synchronized加入到100次for循环的外面。
main函数中锁粗化后的程序如下所示,只需要进入一次同步代码块,然后再for循环100次即可。
public static void main(String[] args){
StringBuffer sb = new StringBuffer();
synchronized{
for(int i = 0; i< 100 ; ++){
sb.append("aa");
}
}
System.out.println(sb.toString());
}
工作中如何优化synchronized
减少synchronized的范围
同步代码块中尽量短,减少同步代码块中代码的执行时间,减少锁的竞争。
尽量让synchronized同步代码块当中的代码少一点,这样执行的时间也就会少一点,那么在单位时间内所执行的线程也就多一点,等待的线程也就少一点;
另外由于执行比较短,由轻量级锁就有可能搞得定,或者通过自旋锁也可以搞定,避免升级到重量级锁。
降低synchronized锁的粒度
将一个锁拆分为多个锁提高并发度。尽量不要使用类名.class作为锁对象。
public class Demo01{
public void test01(){
// 尽量不要使用类名.class这样的锁
synchronized(Demo01.class){
}
}
public void test02(){
synchronized(Demo01.class){
}
}
}
如HashTable,增删改查时,它是对整个 put 、 get 或 remove 方法都加了加 synchronized,对这些实例方法加 synchronized,锁对象是this,即程序员自己创建的hashtable对象。所以,HashTable的增删改查获取的是同一把锁,就会有”读读互斥、读写互斥“的问题,效率低下。
public class Demo01{
public static void main(String[] args){
Hashtable hs = new Hashtable();
// 以下四个操作获取的是同一把锁
hs.put("aa","bb");
hs.put("xx","yy");
hs.get("a");
hs.remove("b");
}
}
// ------------------- Hashtable 源码
public synchronized V put(K key, V value){}
public synchronized V get(Object key){}
public synchronized V remove(Object key){}
因此 jdk 又推出了一个新的类叫做
ConcurrentHashMap
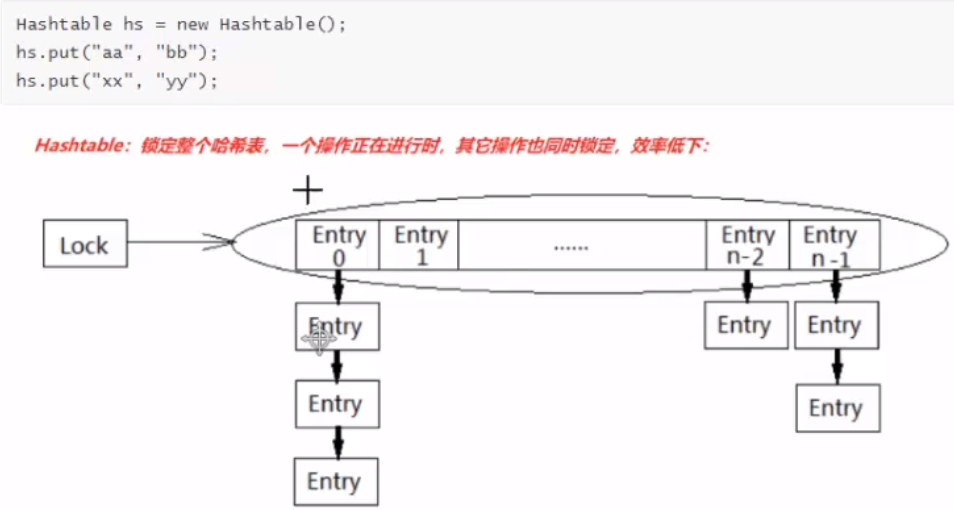
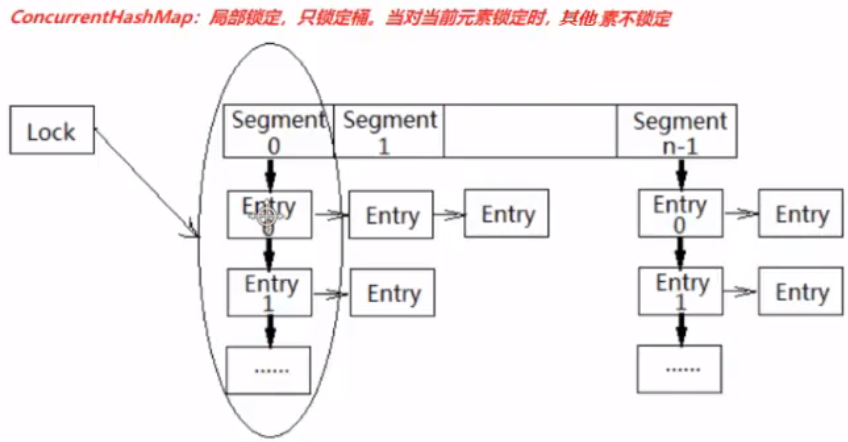
ConCurrentHashMap,添加元素时,每次锁的都是Segment(1.7版本),降低了锁的粒度,并且对查询方法 get() 不上锁。
Hashtable VS ConcurrentHashMap,请参考另一篇文章: https://www.yuque.com/itpeng/nqyl44/ef2zop#ab63g
如果还有synchronized的其他内容本文没涉及到,后续再补充!!!
如发现有错误,欢迎评论区指正!
参考
博客:https://blog.csdn.net/qq_43409111/article/details/115196711
视频:https://www.bilibili.com/video/BV1aJ411V763
synchronized原理剖析的更多相关文章
- ARouter原理剖析及手动实现
ARouter原理剖析及手动实现 前言 路由跳转在项目中用了一段时间了,最近对Android中的ARouter路由原理也是研究了一番,于是就给大家分享一下自己的心得体会,并教大家如何实现一款简易的路由 ...
- 0000 - Spring 中常用注解原理剖析
1.概述 Spring 框架核心组件之一是 IOC,IOC 则管理 Bean 的创建和 Bean 之间的依赖注入,对于 Bean 的创建可以通过在 XML 里面使用 <bean/> 标签来 ...
- Spring 中常用注解原理剖析
前言 Spring 框架核心组件之一是 IOC,IOC 则管理 Bean 的创建和 Bean 之间的依赖注入,对于 Bean 的创建可以通过在 XML 里面使用 <bean/> 标签来配置 ...
- 原理剖析-Netty之服务端启动工作原理分析(下)
一.大致介绍 1.由于篇幅过长难以发布,所以本章节接着上一节来的,上一章节为[原理剖析(第 010 篇)Netty之服务端启动工作原理分析(上)]: 2.那么本章节就继续分析Netty的服务端启动,分 ...
- Java锁-Synchronized深层剖析
Java锁-Synchronized深层剖析 前言 Java锁的问题,可以说是每个JavaCoder绕不开的一道坎.如果只是粗浅地了解Synchronized等锁的简单应用,那么就没什么谈的了,也不建 ...
- 18、TaskScheduler原理剖析与源码分析
一.源码分析 ###入口 ###org.apache.spark.scheduler/DAGScheduler.scala // 最后,针对stage的task,创建TaskSet对象,调用taskS ...
- JVM Attach实现原理剖析
本文转载自JVM Attach实现原理剖析 前言 本文旨在从理论上分析JVM 在 Linux 环境下 Attach 操作的前因后果,以及 JVM 为此而设计并实现的解决方案,通过本文,我希望能够讲述清 ...
- ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件)
ASP.NET Core 运行原理剖析2:Startup 和 Middleware(中间件) Startup Class 1.Startup Constructor(构造函数) 2.Configure ...
- ASP.NET Core 运行原理剖析1:初始化WebApp模版并运行
ASP.NET Core 运行原理剖析1:初始化WebApp模版并运行 核心框架 ASP.NET Core APP 创建与运行 总结 之前两篇文章简析.NET Core 以及与 .NET Framew ...
随机推荐
- vue3 迫不得已我硬着头皮查看了keepalive的源代码,解决了线上的问题
1.通过本文可以了解到vue3 keepalive功能 2.通过本文可以了解到vue3 keepalive使用场景 3.通过本文可以学习到vue3 keepalive真实的使用过程 4.通过本文可以学 ...
- Java变量, 常量和作用域
目录 变量 作用域 局部变量 实例变量 类变量 常量 命名规范 视频课程 变量 变量就是可以变化的量 Java是一种强类型的语言, 每个变量都必须声明其类型 Java变量是程序中最基本的存储单元, 其 ...
- java基础题(5)
6.常用API 6.1string类 1.动态字符串 描述 将一个由英文字母组成的字符串转换成从末尾开始每三个字母用逗号分隔的形式. 输入描述: 一个字符串 输出描述: 修改后的字符串 示例1 输入: ...
- 高度灵活可定制的PC布局:头部按钮、左边栏、右边栏、状态栏
什么是自适应布局 CabloyJS提供了一套布局管理器,实现自适应布局 关于自适应布局的概念,强烈建议先阅读以下两篇文章: 自适应布局:pc = mobile + pad 自适应布局:视图尺寸 什么是 ...
- 【Redis】客观下线
在sentinelHandleRedisInstance函数中,如果是主节点,需要做如下处理: void sentinelHandleRedisInstance(sentinelRedisInstan ...
- 8.shell编程之免交互
shell编程之免交互 目录 shell编程之免交互 Here Document免交互 免交互定义 Here Document变量设定 多行的注释 expect expect 定义 expect基本命 ...
- 实现领域驱动设计 - 使用ABP框架 - 创建实体
用例演示 - 创建实体 本节将演示一些示例用例并讨论可选场景. 创建实体 从实体/聚合根类创建对象是实体生命周期的第一步.聚合/聚合根规则和最佳实践部分建议为Entity类创建一个主构造函数,以保证创 ...
- rhel挂载本地光盘为yum源
挂载光盘 mount /dev/sr0 /mnt/cdrom mkdir /mnt/cdrom 临时挂载 mount /dev/sr0 /mnt/cdrom 永久挂载光盘 mount -a 执行挂载 ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- Nginx开机自启
编写service脚本: vim /usr/lib/systemd/system/nginx.service 将以下内容复制到nginx.service文件中 ps:我的nginx目录是/usr/lo ...