Bika LIMS 开源LIMS集—— SENAITE的安装
安装环境
- 操作系统 Ubuntu 18.04 LTS
- Python 2.x.
- Plone 4
安装步骤
Ubuntu等Linux、Mac系统一般安装有Python的环境,但由于需要安装Python扩展库,集成安装的在权限方面可能遇到问题,因此建议使用虚拟Python环境。
相关工具:
- Virtualenv: https://pypi.org/project/virtualenv
- Miniconda(推荐): https://conda.io/miniconda.html
操作系统创建用户senaite
$ sudo adduser --home /home/senaite --shell /bin/bash senaite
切换用户
$ sudo su - senaite
$ whoami
senaite
下载并安装Python2.7
$ wget https://repo.anaconda.com/miniconda/Miniconda2-latest-Linux-x86_64.sh
$ bash /home/senaite/Miniconda2-latest-Linux-x86_64.sh
$ source /home/senaite/.bashrc
创建Python环境
$ conda create --name senaite python=2.7
激活
$ conda activate senaite
检查当前会话是否使用了正确版本的Python
$ which python
/home/senaite/miniconda2/envs/senaite/bin/python
出现如下提示则正确
$ python
Python 2.7.17 |Anaconda, Inc.| (default, Oct 21 2019, 19:04:46)
[GCC 7.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
安装LIMS系统依赖
$ sudo apt install build-essential
$ sudo apt install python2.7 python2.7-dev
$ sudo apt install libxml2 libxml2-dev libxslt1.1 libxslt1-dev
$ sudo apt install libffi-dev libcairo2 libpango-1.0-0 libgdk-pixbuf2.0-0 libpangocairo-1.0-0 libgdk-pixbuf2.0-0
$ sudo apt install zlib1g zlib1g-dev
安装Plone
下载Plone
$ wget --no-check-certificate https://launchpad.net/plone/4.3/4.3.19/+download/Plone-4.3.19-UnifiedInstaller.tgz
$ tar xzf Plone-4.3.19-UnifiedInstaller.tgz
$ cd Plone-4.3.19-UnifiedInstaller
安装Plone
$ ./install.sh standalone --target=/home/senaite --instance=senaitelims --password=admin
账号admin,密码admin,安装目录/home/senaite
修改buildout.cfg配置文件
$ cd /home/senaite/senaitelims
$ vim buildout.cfg
使用vim或nano等编辑器编辑cfg配置文件
添加senaite配置
[buildout]
...
eggs =
...
senaite.lims
simplejson
zcml =
...
修改版本
[versions]
zc.buildout =
setuptools =
Pillow = 5.1.0
cssselect2 = 0.2.2
soupsieve = 1.9.5
buildout.sanitycheck = 1.0.2
collective.recipe.backup = 4.0
plone.recipe.unifiedinstaller = 4.3.2
升级 pip, setuptools 和 zc.buildout
创建requirements.txt,定义依赖版本
$ cd /home/senaite/senaitelims
$ cat << EOF > requirements.txt
setuptools==39.2.0
zc.buildout==2.13.2
pip==19.3.1
EOF
使用pip安装依赖
$ which pip
/home/senaite/miniconda2/envs/senaite/bin/pip
$ pip install -r requirements.txt
重写运行buildout脚本
$ which buildout
/home/training/miniconda2/envs/senaite/bin/buildout
$ PYTHONHTTPSVERIFY=0 buildout
运行SENAITE
前台运行
$ bin/instance fg
后台服务运行
启动:
bin/instance start
停止:
bin/instance stop
访问8080端口
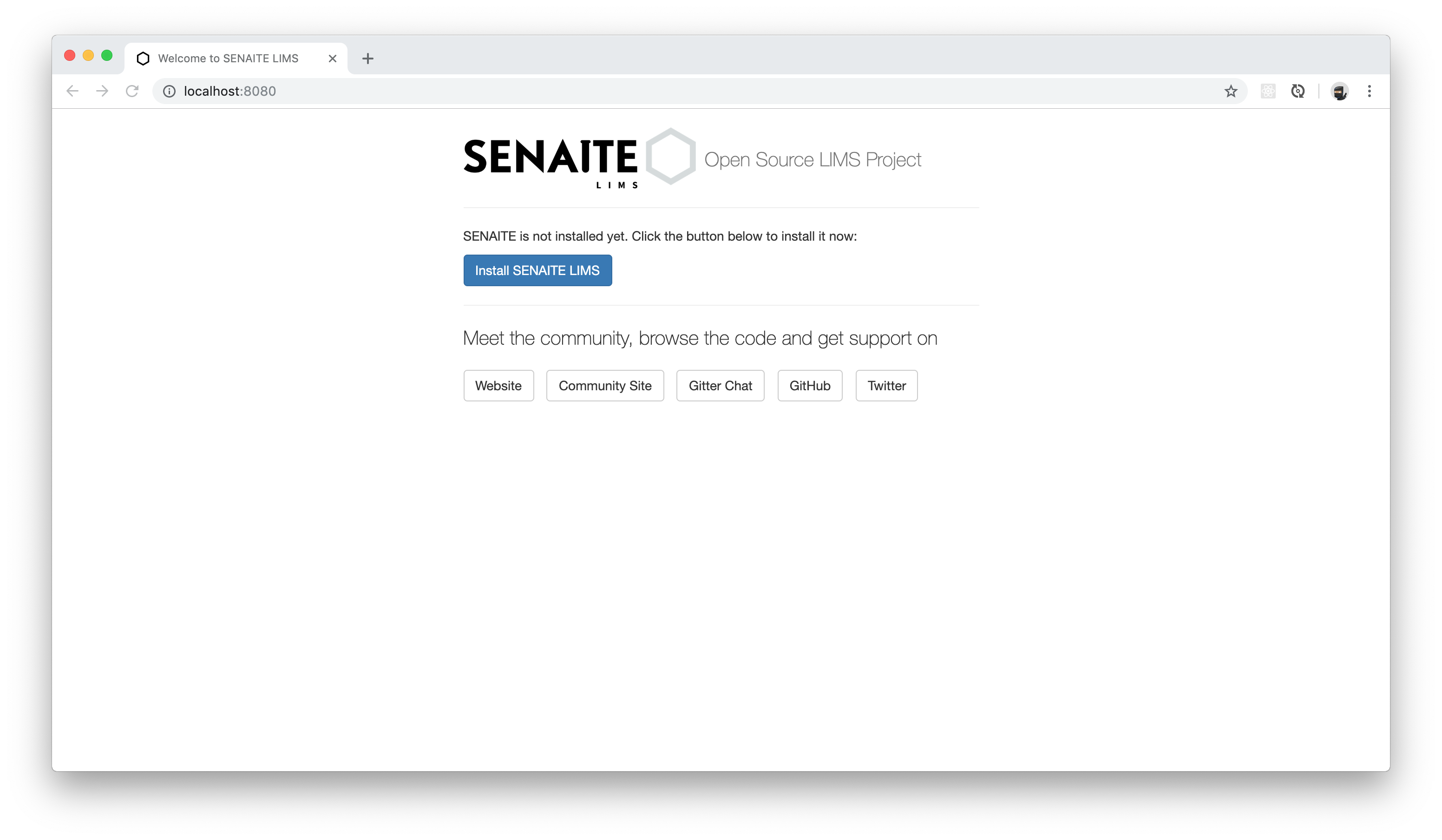
使用admin\admin登录系统,输入系统名称、UI语言后,创建LIMS
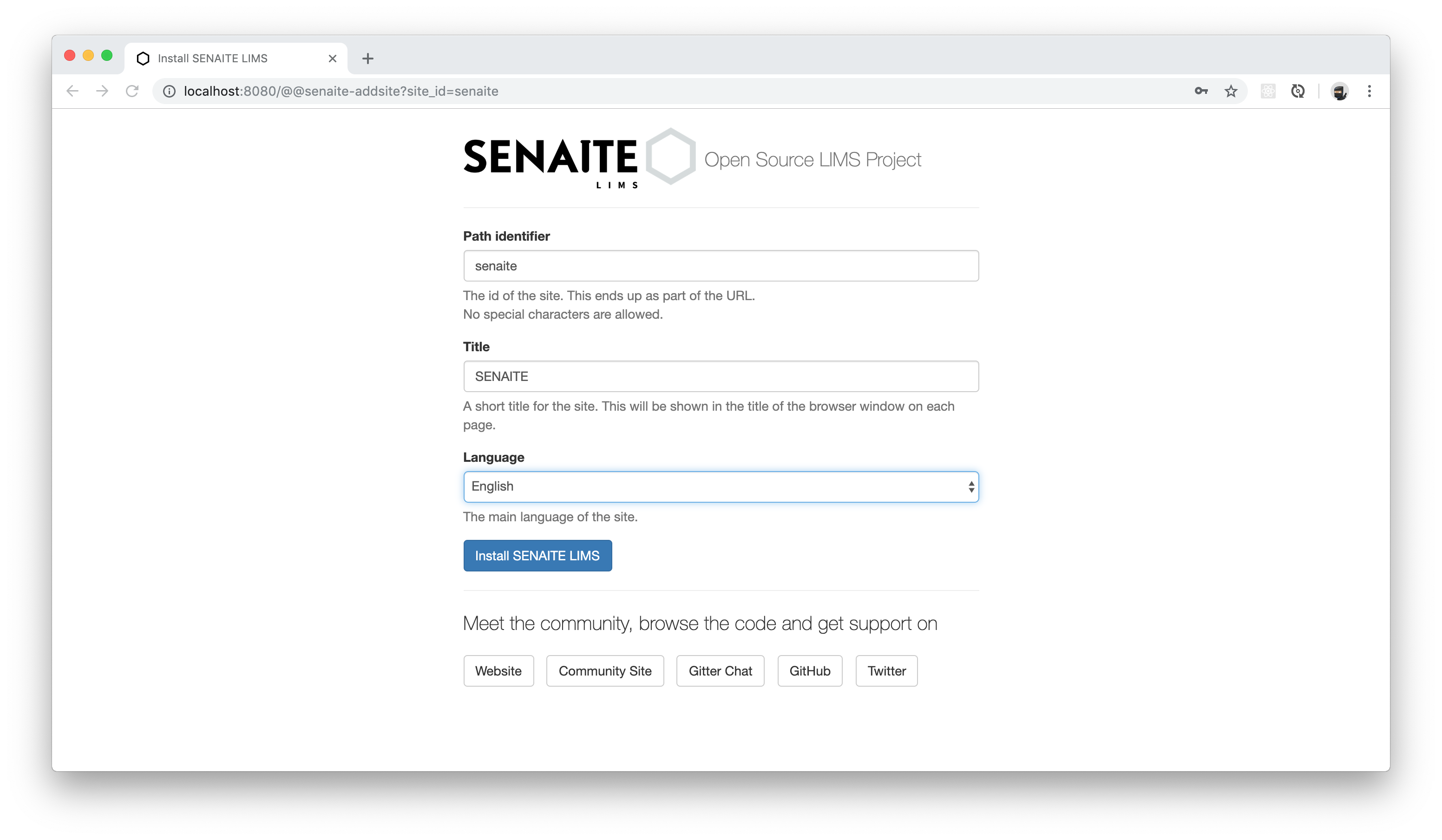
创建好后的LIMS系统如下:

Bika LIMS 开源LIMS集—— SENAITE的安装的更多相关文章
- Bika LIMS 开源LIMS集—— SENAITE的使用(用户、角色、部门)
设置 添加实验室人员,系统用户 因为创建实验室时必须选择实验室经理/主任/负责人,因此需要先创建实验室经理人员. 创建人员时输入人员姓名,可上传签名图片. 创建实验室部门 输入实验室名称.代码,选择实 ...
- Bika LIMS 开源LIMS集—— SENAITE的使用(分析/测试、方法)
分析/测试项目分类(Test Category) 定义检测项目的分类,例如理化检测.微生物检测,或者按样品的维度定义,例如食品检测.水质检测等. 分析方法(Test Method) 定义实验室分析方法 ...
- Bika LIMS 开源LIMS集—— SENAITE的使用(检测流程)
客户管理 登记客户信息,包括地址.合同报告邮寄地址.账单邮寄地址.付款银行账号等. 产品批次管理 例如某乳品公司生产处一批产品,该批产品送往实验室检测,实验室登记该批产品批号,如对该批产品做多次检测, ...
- Bika LIMS 开源LIMS集——ERD实体关系定义(数据库设计)
系统数据分类 数据分为四类: template 模板,基础静态数据 static 静态数据,核心静态数据,检测方法等 dynamic 动态数据,样品检测流程数据 organisation 组织机构数据 ...
- Bika LIMS 开源LIMS集——实验室检验流程概述及主页、面板
主页 主页左侧为功能入口菜单.右侧含待办提醒,中间为工作区. 工作区功能将主要工作页面置于首页,便于用户操作. Dashboard 面板 系统面板 包括待排定的实验任务.实验中的任务数.复核/审核中的 ...
- 一脸懵逼学习KafKa集群的安装搭建--(一种高吞吐量的分布式发布订阅消息系统)
kafka的前言知识: :Kafka是什么? 在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算.kafka是一个生产-消费模型. Producer:生产者,只负责数 ...
- 分布式实时日志系统(一)环境搭建之 Jstorm 集群搭建过程/Jstorm集群一键安装部署
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- Dubbo入门到精通学习笔记(十七):FastDFS集群的安装、FastDFS集群的配置
文章目录 FastDFS集群的安装 FastDFS 介绍(参考:http://www.oschina.net/p/fastdfs) FastDFS 上传文件交互过程: FastDFS 下载文件交互过程 ...
随机推荐
- Java---基本程序结构
一个完整的Java程序: /** * 文档注释 * * @author wind8 * */ public class Hello { /** * @param args */ public stat ...
- Mybatsi注解开发-基础操作
1.导入坐标 <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pag ...
- spring原始注解
spring原始注解主要是替代Bean标签的配置 @Component:使用在类上用于实例化Bean @Controller:使用在web层类上用于实例化Bean @Service:使用在servic ...
- 夯实基础上篇-图解 JavaScript 执行机制
讲基础不易,本文通过 9 个 demo.18 张 图.2.4k 文字串讲声明提升.JavaScript 编译和执行.执行上下文.调用栈的基础知识.
- php进制转换
前端html页面代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- angular.js中 路由 用法及概念
在开讲之前,首先谈谈APP应用.平时我们用的app总是多页面,如果用原生安卓或者苹果,那当然很流畅啦.但是当我们用一般的html页面做移动端,简单时候我们可以用<a href="&qu ...
- 2021.12.15 P2328 [SCOI2005]超级格雷码(找规律填空)
2021.12.15 P2328 [SCOI2005]超级格雷码(找规律填空) https://www.luogu.com.cn/problem/P2328 题意: 输出n位B进制的格雷码. 分析: ...
- 使用 VS Code 撰写 Markdown 文档
众所周知, VS Code 是微软和社区一起开发的一款很优秀的高级代码编辑器.它不仅可以写出一手好代码,还能写出一篇好文章.利用 Markdown 就可以写出一篇排版美观的技术文章了. 而 Markd ...
- 微服务状态之python巡查脚本开发
背景 由于后端微服务架构,于是各种业务被拆分为多个服务,服务之间的调用采用RPC接口,而Nacos作为注册中心,可以监听多个服务的状态,比如某个服务是否down掉了.某个服务的访问地址是否改变.以及流 ...
- Python 函数进阶-迭代器
迭代器 什么是迭代器 能被 next 指针调用,并不断返回下一个值的对象,叫做迭代器.表示为Iterator,迭代器是一个对象类型数据. 概念 迭代器指的是迭代取值的工具,迭代是一个重复的过程,每次重 ...