mysql覆盖索引与回表
mysql覆盖索引与回表

select id,name where name='shenjian'
select id,name,sex* where name='shenjian'*
多查询了一个属性,为何检索过程完全不同?
什么是回表查询?
什么是索引覆盖?
如何实现索引覆盖?
哪些场景,可以利用索引覆盖来优化SQL?
这些,这是今天要分享的内容。
画外音:本文试验基于MySQL5.6-InnoDB。
一、什么是回表查询?
这先要从InnoDB的索引实现说起,InnoDB有两大类索引:
聚集索引(clustered index)
普通索引(secondary index)
InnoDB聚集索引和普通索引有什么差异?
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
画外音:所以PK查询非常快,直接定位行记录。
InnoDB普通索引的叶子节点存储主键值。
画外音:注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
举个栗子,不妨设有表:
t(id PK, name KEY, sex, flag);
画外音:id是聚集索引,name是普通索引。
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
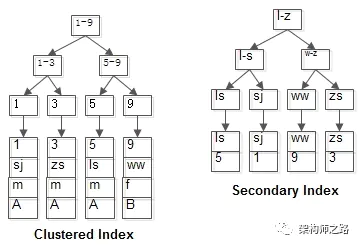
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
通常情况下,需要扫码两遍索引树。
例如:
select * from t where name='lisi';
是如何执行的呢?
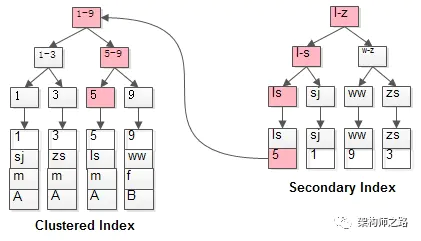
如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
二、什么是索引覆盖****(Covering index)****?
额,楼主并没有在MySQL的官网找到这个概念。
画外音:治学严谨吧?
借用一下SQL-Server官网的说法。

MySQL官网,类似的说法出现在explain查询计划优化章节,即explain的输出结果Extra字段为Using index时,能够触发索引覆盖。

三、如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
仍是《迅猛定位低效SQL?》中的例子:
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
第一个SQL语句:
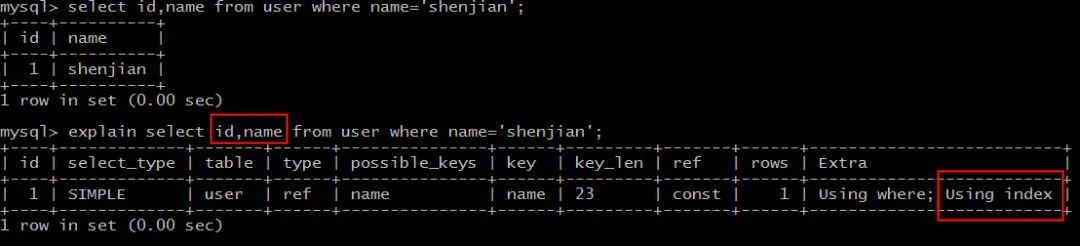
select id,name from user where name='shenjian';
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
画外音,Extra:Using index。
第二个SQL语句:
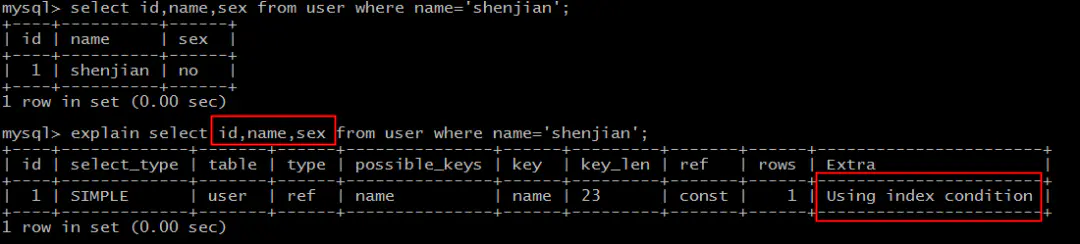
select id,name,sex* from user where name='shenjian';*
能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取sex字段,效率会降低。
画外音,Extra:Using index condition。
如果把(name)单列索引升级为联合索引(name, sex)就不同了。
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name, sex)
)engine=innodb;
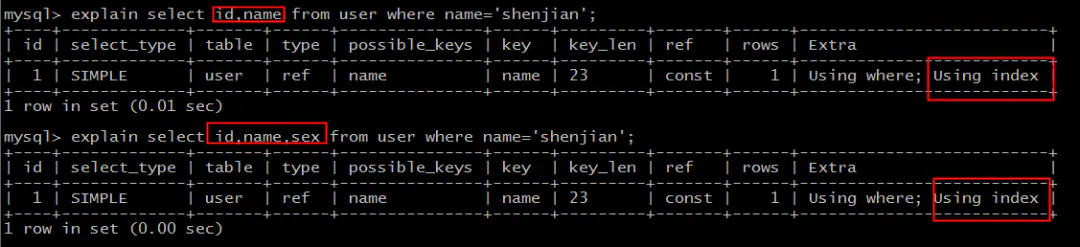
可以看到:
select id,name ... where name='shenjian';
select id,name,sex* ... where name='shenjian';*
都能够命中索引覆盖,无需回表。
画外音,Extra:Using index。
四、哪些场景可以利用索引覆盖来优化SQL?
场景1:全表count查询优化
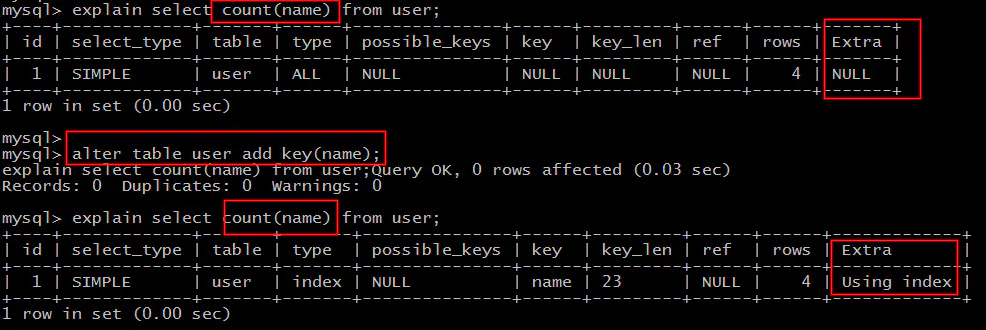
原表为:
user(PK id, name, sex);
直接:
select count(name) from user;
不能利用索引覆盖。
添加索引:
alter table user add key(name);
就能够利用索引覆盖提效。
场景2:列查询回表优化
select id,name,sex ... where name='shenjian';
这个例子不再赘述,将单列索引(name)升级为联合索引(name, sex),即可避免回表。
场景3:分页查询
select id,name,sex ... order by name limit 500,100;
将单列索引(name)升级为联合索引(name, sex),也可以避免回表。
InnoDB聚集索引普通索引,回表,索引覆盖,希望这1分钟大家有收获。
作者:Harri2012
链接:https://www.jianshu.com/p/8991cbca3854
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
mysql覆盖索引与回表的更多相关文章
- mysql:如何利用覆盖索引避免回表优化查询
说到覆盖索引之前,先要了解它的数据结构:B+树. 先建个表演示(为了简单,id按顺序建): id name 1 aa 3 kl 5 op 8 aa 10 kk 11 kl 14 jk 16 ml 17 ...
- 一篇文章讲清楚MySQL的聚簇/联合/覆盖索引、回表、索引下推
迎面走来了你的面试官,身穿格子衫,挺着啤酒肚,发际线严重后移的中年男子. 手拿泡着枸杞的保温杯,胳膊夹着MacBook,MacBook上还贴着公司标语:"加班使我快乐". 面试官: ...
- InnoDB 聚集索引和非聚集索引、覆盖索引、回表、索引下推简述
关于InnoDB 存储引擎的有聚集索引和非聚集索引,覆盖索引,回表,索引下推等概念,这些知识点比较多,也比较零碎,但是概念都是基于索引建立的,本文从索引查找数据讲述上述概念. 聚集索引和非聚集索引 在 ...
- 【MySQL】覆盖索引和回表
先来了解一下两大类索引 聚簇索引(也称聚集索引,主键索引等) 普通索引(也成非聚簇索引,二级索引等) 聚簇索引 如果表设置了主键,则主键就是聚簇索引 如果表没有主键,则会默认第一个NOT NULL,且 ...
- MySQL 覆盖索引
通常大家都会根据查询的WHERE 条件来穿件合适的索引,不过这只是索引优化的一个方面.设计优秀的索引应该考虑到整个查询,而不单单是WHERE 条件部分.索引确实是一种查找数据的高效方式,但是MySQL ...
- mysql覆盖索引详解
覆盖索引的定义: 如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’.即只需扫描索引而无须回表. 只扫描索引而无需回表的优点: 1.索引条目通常远小于数据行大小,只需要读取索引, ...
- Mysql覆盖索引与延迟关联
延迟关联:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据. 为什innodb的索引叶子节点存的是主键,而不是像myisam一样存数据的物理地址指针? 如果存的是物理地址指针不 ...
- MySQL 优化之 MRR (Multi-Range Read:二级索引合并回表)
MySQL5.6中引入了MRR,专门来优化:二级索引的范围扫描并且需要回表的情况.它的原理是,将多个需要回表的二级索引根据主键进行排序,然后一起回表,将原来的回表时进行的随机IO,转变成顺序IO.文档 ...
- mysql覆盖索引(屌的狠,提高速度)
话说有这么一个表: CREATE TABLE `user_group` ( `id` int(11) NOT NULL auto_increment, `uid` int(11) NOT NULL, ...
随机推荐
- 关于iOS APP转让
需要以下条件即可
- SQL Server 索引结构
索引是数据库的基础,只有先搞明白索引的结构,才能搞明白索引运行的逻辑 本文通过 索引表.数据页.执行计划.IO统计.B+Tree 来尽可能的介绍 SQL 语句中 WHERE 部分,和 SELECT 部 ...
- 记一次慢查询优化sql
sql语句优化(慢查询日志) 最近,旧系统向新系统迁移工程刚刚结束.开发完成后,测试阶段也是好好休息了一把.接到一个需求,由于内部员工使用的网站部分功能加载时间很长,所以需要去优化系统的一些功能.大致 ...
- centos7对外开放端口号
前提:防火墙处于打开状态 1:查看防护墙启动状态:systemctl status firewalld 2:开启:systemctl start firewalld 3:关闭:systemctl s ...
- CobaltStrike逆向学习系列(7):Controller 任务发布流程分析
这是[信安成长计划]的第 7 篇文章 关注微信公众号[信安成长计划] 0x00 目录 0x01 Controller->TeamServer 0x02 TeamServer->Beacon ...
- Gerrit的用法及与gitlab的区别
来到一个新的团队,开发的代码被同事覆盖了.找同事核实,同事却说根本没有看到我的代码.经过一番沟通了解,原来他们的代码没有直接在gitlab上操作,而是先提交到gerrit,然后在提交到git.但是代码 ...
- 思迈特软件Smartbi:传统BI被“革命”,AI是BI技术未来的发展趋势
根据IDC报告,2020年中国BI软件存量市场规模为38.2亿元,到2024年,市场规模将达到78.5亿元,未来4年整体市场年复合增长率(CAGR)为19.2%.此外,还有规模达到100亿元的增量市场 ...
- C#爬虫(02):Web browser控件CefSharp的使用
一.CefSharp介绍 CEF 全称是Chromium Embedded Framework(Chromium嵌入式框架),是个基于Google Chromium项目的开源Web browser控件 ...
- Codeforces Round #773 (Div. 2)D,E
D. Repetitions Decoding 传送门 题目大意: 一个长为 n ( n 2 ≤ 250000 ) n(n^2\leq250000) n(n2≤250000)的序列,每个元素 a i ...
- 设计模式(一) 灵活的javaScript语言
首先先看几个函数: function checkName () {){}// 验证姓名 function checkEmail() {} // 验证邮箱 function checkPassword( ...