第二篇:R语言数据可视化之数据塑形技术
前言
绘制统计图形时,半数以上的时间会花在调用绘图命令之前的数据塑型操作上。因为在把数据送进绘图函数前,还得将数据框转换为适当格式才行。
本文将给出使用R语言进行数据塑型的一些基本的技巧,更多技术细节推荐参考《R语言核心手册》。
数据框塑型
1. 创建数据框 - data.frame()
# 创建向量p
p = c("A", "B", "C")
# 创建向量q
q = 1:3
# 创建数据框:含p/q两列
dat = data.frame(p, q)
结果展示: 
2. 查看数据框信息 - str()
# 展示数据集dat信息
str(dat)
结果展示:

3. 向数据框添加列
基本格式为:数据框$新列名 = 向量名。如下代码将在dat数据集中创建名为newcol的列,并将向量v赋值给它:
dat$newcol = v
如果向量长度小于数据框的行数,R会重复这个向量,直到所有行被填充。
4. 从数据框中删除列
可以将NULL赋值给某列即可。如下代码将删除数据集中的badcol列:
dat$badcol = NULL
也可以使用subset函数(后面会具体讲),并将一个减号至于待删除的列前:
dat = subset(data, select = -badcol)
5. 重命名数据框中的列名
可以将列名称向量赋值给names函数:
names(dat) = c("name1", "name2", "name3")
如果想通过列名重命名某一列可以这样:
# 将名为ctrl的列更名为Cntrol
names(anthoming)[names(anthoming) == "ctrl"] = c("Cntrol")
6. 重排序数据框的列
可以通过数值位置重排序:
# 通过列的数值位置重排序
dat = dat[c(1,3,2)]
也可以通过列的名称重排序:
# 通过列的名称重排序
dat = dat[c("col1", "col3", "col2")]
7. 从数据框提取子集 - subset()
如下R语言代码从climate数据框中,选定Source属性为"Berkeley"的记录的"Year"、"Anomaly10y"两列:
# subset函数:首参选定数据集, Source参数选定行,select参选定列
subset(climate, Source == "Berkeley", select = c(Year, Anomaly10y))
因子水平塑型
1. 根据数据的值改变因子水平顺序 - reorder()
下面这个例子将根据count列对spray列中的因子水平进行重排序,汇总数据为mean:
# reorder函数:首参选定因子向量,次参选定排序依据的数据向量,FUN参数选定汇总函数
iss$spray = reorder(iss$spray, iss$count, FUN = mean)
2. 改变因子水平的名称 - revalue() / mapvalues() in plyr包
如下两行R语言代码均可将水平因子f中名为"small","medium","large"的因子分别更名为"S","M", "L":
# 方法一
f = revalue(f, c(small = "S", medium = "M", large = "L"))
# 方法二
f = mapvalues(f, c("small", "medium", "large"), c("S", "M", "L"))
3. 去掉因子中不再使用的水平 - droplevels()
如下R语言代码将剔除掉因子f中多余的水平:
droplevels(f)
变量塑型
1. 变量替换 - match()
要将某些值替换为其他特定值,可使用match函数。如下R语言代码将数据框pg的group列的oldvals中的"ctr1","trt1","trt2"的值分别替换为"No","Yes","Yes":
# 旧值
oldvals = c("ctrl1", "trt1", "trt2")
# 新值
newvals = factor(c("No", "Yes", "Yes"))
# 替换
pg$treatment = newvals[match(pg$group, oldvals)]
2. 分组转换数据 - ddply() in plyr包
通过使用ddply()函数的transform参数功能,能够对不同分组内的数据进行转换。如下R语代码能够将cabbages数据框按照Cult列因子进行分组,并在数据框中创建一个新的名为DevWt的列,该新列值由原某列值减分组均值得到:
# ddply函数:首参选定数据框,次参选定分组变量,叁参选定处理方式,肆参输出新列
cb = ddply(cabbages, "Cult", transform, DevWt = HeadWt - mean(HeadWt))
3. 分组汇总数据 - ddply() in plyr包
通过使用ddply()函数的transform参数功能,能够对不同分组内的数据进行汇总。汇总和上面介绍的转换的区别在于汇总结果的记录数等于分组的个数,而转换操作后记录数是不变的,只是对原列进行改动转换。如下R语言代码将cabbages数据框按照Cult和Date列因子进行分组,并在数据框中创建一个新的名为DevWt的列,该新列值由对每个分组进行均值统计得到:
# ddply函数:首参选定数据框,次参选定分组变量,叁参选定处理方式,肆参输出新列
cb = ddply(cabbages, c("Cult", "date"), summarise, Weight = mean(HeadWt))
长/宽数据塑型
1. 宽数据 -> 长数据 - melt() in reshape2包
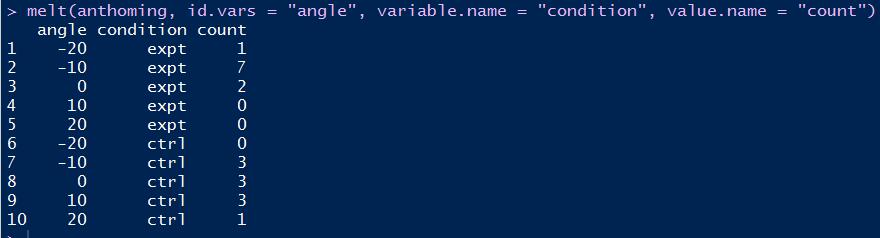
anthoming数据集如下所示:

其中expt和ctrl两列可以合并为一列。合并后的数据框相对合并前的叫长数据,而合并前的数据框相对合并后的数据叫宽数据,是不是很贴切呢?
如下R语言代码使用melt函数将上述数据集"拉长":
# melt函数:首参选定数据框,次参选定记录标识列,variable.name选定拉长后的属性名列,value.name选定拉长后的属性值列
melt(anthoming, id.vars = "angle", variable.name = "condition", value.name = "count")
拉长后的效果:
2. 长数据 -> 宽数据 - dcast() in reshape2包
plum数据集如下所示:

该数据框中length列和time列作为标识列, 如下R语言代码可将该数据框压扁:
# dcast函数:首参选定数据框,次参选定记录标识列和新的属性名列,value.var选定被拉长的属性值列
dcast(plum, length + time ~ survival, value.var = "count")
压扁后的效果:

小结
在调用任何图像绘制函数之前,都要按照绘图函数的要求摆放好数据,这个过程也被称为数据塑型。本文的部分功能可能读者会疑惑有啥用,别着急,先进入到有趣的绘制章节部分吧。随着绘图次数增多,慢慢就会懂了。
第二篇:R语言数据可视化之数据塑形技术的更多相关文章
- R语言中的横向数据合并merge及纵向数据合并rbind的使用
R语言中的横向数据合并merge及纵向数据合并rbind的使用 我们经常会遇到两个数据框拥有相同的时间或观测值,但这些列却不尽相同.处理的办法就是使用merge(x, y ,by.x = ,by.y ...
- R语言系列:生成数据
R语言系列:生成数据 (2014-05-04 17:41:57) 转载▼ 标签: r语言 教育 分类: 生物信息 生成规则数据1.使用“:“,如x=1:10,注意该方法既可以递增也可以递减,如y=10 ...
- 第六篇:R语言数据可视化之数据分布图(直方图、密度曲线、箱线图、等高线、2D密度图)
数据分布图简介 中医上讲看病四诊法为:望闻问切.而数据分析师分析数据的过程也有点相似,我们需要望:看看数据长什么样:闻:仔细分析数据是否合理:问:针对前两步工作搜集到的问题与业务方交流:切:结合业务方 ...
- R语言数据集合并、数据增减、不等长合并
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 数据选取与简单操作: which 返回一个向量 ...
- 用R语言实现对不平衡数据的四种处理方法
https://www.weixin765.com/doc/gmlxlfqf.html 在对不平衡的分类数据集进行建模时,机器学**算法可能并不稳定,其预测结果甚至可能是有偏的,而预测精度此时也变得带 ...
- R语言︱噪声数据处理、数据分组——分箱法(离散化、等级化)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 分箱法在实际案例操作过程中较为常见,能够将一些 ...
- 吴裕雄--天生自然 R语言开发学习:数据集和数据结构
数据集的概念 数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量.表2-1提供了一个假想的病例数据集. 不同的行业对于数据集的行和列叫法不同.统计学家称它们为观测(observation)和 ...
- R语言读取matlab中数据
1. 在matlab中将数据保存到*.mat 文件夹 save("data.mat","data","label")#将data和label ...
- R语言:导入导出数据
主要学习如何把几种常用的数据格式导入到R中进行处理,并简单介绍如何把R中的数据保存为R数据格式和csv文件. 1.保存和加载R的数据(与R.data的交互:save()函数和load()函数) a & ...
随机推荐
- SQL2012之FileTable与C#的联合应用
关于FileTable是什么,请猛击如下链接:http://technet.microsoft.com/zh-cn/library/ff929144(v=SQL.110).aspx:如您已知道,请跳过 ...
- TabControl控件中TabPage的显示和隐藏
TabPage里面含有方法Hide和Show,但没有任何作用,实际隐藏和显示需要使用如下2个方法 方法一:此方法比较简单 TabPageServo.Parent = Nothing //隐藏 Ta ...
- PHP数据库
目录 1.创建数据库连接 2.创建数据库 3.选择数据库 4.设置当前连接使用的字符编码 5.创建表 6.插入数据 7.取得数据查询结果 8.关闭连接 1.创建数据库连接 //mysql_connec ...
- Bootstrap_表单_表单样式
一.基础表单 <form > <div class="form-group"> <label>邮箱:</label> <inp ...
- 【技术宅4】如何把M个苹果平均分给N个小朋友
$apple=array('apple1','apple2','apple3','apple4','apple5','apple6','apple7','apple8','apple9','apple ...
- CentOS 6.8安装Python2.7.13
查看当前系统中的 Python 版本 python --version 返回 Python 2.6.6 为正常. 检查 CentOS 版本 cat /etc/redhat-release 返回 Cen ...
- How to solve "The specified service has been marked for deletion" error
There may be several causes which lead to the service being stuck in “marked for deletion”. Microsof ...
- Flux
Ken Wheeler 构建React 应用的一套架构. 应用程序架构, 单向数据流方案. Dispatcher 的开源库. 一种全局pub/sub 系统的事件处理器, 用于 向所注册的加调函数 ...
- Gnome Tetravex
zoj1008:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=1008 题目意思是有一个游戏,即给出一个图,该图是由n*n个 ...
- SQL Server查看所有表大小,所占空间
create table #Data(name varchar(100),row varchar(100),reserved varchar(100),data varchar(100),index_ ...