Tomcat工作原理详解
Redis的集合操作
实话说,Redis提供的集合操作是我选择它成为内存数据库的一个主要理由,它弥补了传统关系型数据库在这方面带来的复杂度,使得只需要简单的一个命令就可以完成一个复杂SQL任务,并且交、并、差操作在实际的业务场景中应用非常广泛,比如快速检索出具备一系列标签属性的一个集合,本篇文章将主要介绍对于求交集操作结果缓存的设计方案。
Redis命令
对于set类型,提供了sinter、sinterstore进行交集操作,对于sortedset,提供了zinter、zinterstore进行交集操作。命令十分便捷,对于不保存结果的方法sinter和zinter只需要输入待求交集的集合的key的数组就可以得到求交集后的结果集合,对于保存结果的方法,你可以将求交集后的结果集合保存到你指定key的一个集合中。
设计方案
目标
计算给定集合群的交集集合,并对计算过程中所产生的中间结果集合进行缓存,从而达到下次计算给定集合群的一些子群集时,先查询是否存在交集key,如果存在直接读取,避免重复计算。
原始方法(Only)
以下我们以Redis Java客户端库Jedis进行举例,Jedis提供了与Redis命令的一致接口方法,实现了交集操作,如下代码:
public Set<String> inter(String[] keys, String keycached){
int size = keys.length;
Jedis jedis = new Jedis("127.0.0.1");
if(size < 2){
try{
return jedis.smembers(keys[0]);
} finally {
jedis.close();
}
}
try{
jedis.sinterstore(keycached, keys);
return jedis.smembers(keycached);
} finally {
jedis.close();
}
}
原始方法的问题在于只对最终的交集key进行了缓存,简洁方便,但每次变更给定集合群时,都需要重新在此计算。
原始方法上的改造方案(All)
在原始方法上进行改造,我们可以在计算过程中依次增加计算集合群的集合数量,比如给定的集合群key{A,B,C,D},我们先计算A、B,保存一个{A,B}的交集结果,再依次计算A、B、C和A、B、C、D并对结果进行保存。
显然,这是个糟糕的方案,但确实完成了我们设定的目标,参考代码如下:
private Set<String> interByAll(String... keys){
Jedis jedis = new Jedis("127.0.0.1");
Set<String> value = null;
int interNum = 2;
for(int i = 0; i < (keys.length - 1); i++){
String keystored = "";
String[] keyintered = new String[interNum];
for(int j = 0; j < interNum; j++){
keystored += (keys[j] + "&");
keyintered[j] = keys[j];
}
if(jedis.sinterstore(keystored, keyintered) == 0){
jedis.sadd(keystored, "nocache");
}
if(interNum == keys.length){
value = jedis.smembers(keystored);
}
interNum++;
}
jedis.close();
return value;
}
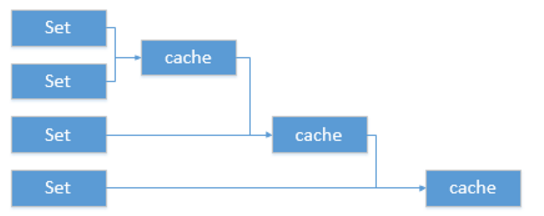
递归方案(Recursive)
根据上面糟糕的设计方案,你应该改进实现一种递归方案,递归方案的好处是你每次只求一对集合的交集,逐步完成对整个给定集合群的交集计算,计算过程如下图所示:
private boolean isEnd = false;
private Set<String> value = null;
private Set<String> getKeysWithInner(String[] keys, String srckey, Jedis jedis, int i){ String key = null; if(srckey == null){//表示为第一次求交集
srckey = keys[i++];
key = keys[i++]; } else {
key = keys[i++];
} String keystored = srckey + "&" + key;//生成缓存key if(jedis.sinterstore(keystored, srckey, key) == 0){
jedis.sadd(keystored, "nocache");
} if(i == keys.length){ //当与最后一个key求交集后,返回结果,并跳出递归调用
value = jedis.smembers(keystored);
isEnd = true;
} while(!isEnd){//递归调用,一对key集合求交集
getKeysWithInner(keys, keystored, jedis, i);
} return value; } public Set<String> interByRecursive(String... keys){
int size = keys.length;
Jedis jedis = new Jedis("127.0.0.1");
if(size < 2){
try{
return jedis.smembers(keys[0]);
} finally {
jedis.close();
}
} try{ return getKeysWithInner(keys, null, jedis, 0);
} finally {
isEnd = false;
jedis.close();
} }
该方案的优势不仅仅是对计算过程进行了缓存,而且,每次都只是完成一对集合的计算,计算量显著降低。
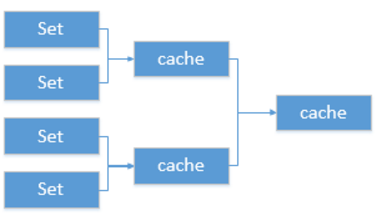
Fork-Join方案(Fork-Join)
一写递归方案,你就可以直接想到使用Fork-Join框架进行改造,并使其并行化,计算过程如下图所示:
InterTask类:
public class InterTask extends RecursiveTask<String>{
private String[] keys = null;
private static final int THRESHOLD = 3;
public InterTask(String[] keys){
this.keys = keys;
}
private static String genKeyinnered(String... keys){
StringBuilder sb = new StringBuilder();
for(String key : keys){
sb.append(key);
sb.append("&");
}
return sb.toString().substring(0, sb.length() - 1);
}
@Override
protected String compute() {
int size = keys.length;
if(size < THRESHOLD){//当keys数组中元素数为2个或1个时,计算交集,并退出递归
if(size < 2){
return keys[0];
}
Jedis jedis = new Jedis("127.0.0.1");
try{
jedis.sinterstore(genKeyinnered(keys), keys[0], keys[1]);
} finally {
jedis.close();
}
return genKeyinnered(keys);
} else {
//取keys数组的中值进行分治算法
String[] leftkeys = new String[size / 2];
String[] rightkeys = new String[size - (size / 2)];
//按中值拆分keys数组
for(int i = 0; i < size; i++){
if(i < leftkeys.length){
leftkeys[i] = keys[i];
} else {
rightkeys[i - leftkeys.length] = keys[i];
}
}
InterTask lefttask = new InterTask(leftkeys);
InterTask righttask = new InterTask(rightkeys);
lefttask.fork();
righttask.fork();
//取得从递归中返回的一对存储交集结果的key
String left = lefttask.join();
String right = righttask.join();
Jedis jedis = new Jedis("127.0.0.1");
try{
jedis.sinterstore(left + "&" + right, left, right);
} finally {
jedis.close();
}
return left + "&" + right;
}
}
}
这里运用了最基础的分治算法思想,逐步将一个大的给定集合拆解为若干个成对的集合进行交集计算。
调用方法:
public Set<String> interByForkJoin(String... keys){
Set<String> value = null;
Jedis jedis = new Jedis("127.0.0.1");
InterTask task = new InterTask(keys);
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future<String> result = forkJoinPool.submit(task);
try {
String key = result.get();
value = jedis.smembers(key);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
jedis.close();
}
return value;
}
测试
测试数据准备
我们这里准备100个集合,每个给定集合包含1000000个元素,参考如下代码:
Jedis jedis = new Jedis("127.0.0.1");
jedis.flushAll();
String token = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
Random rand = new Random();
String[] keys = new String[100];
for(int i = 0; i < 100; i++){
keys[i] = "ct" + i;
String[] values = new String[1000000];
for(int j = 0; j < 1000000; j++){
StringBuilder sb = new StringBuilder();
for(int k = 0;k < 2; k++){
sb.append(token.charAt(rand.nextInt(62)));
}
values[j] = sb.toString();
}
jedis.sadd(keys[i], values);
}
jedis.close();
测试结果
我们分别对25、50、75、100的给定集合进行交集计算,测试结果如下:
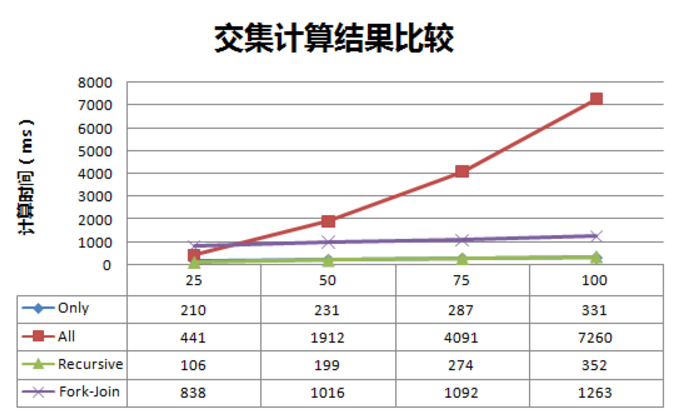
我们可以清楚的看到,All方案是多么的糟糕,剔除All方案的结果:
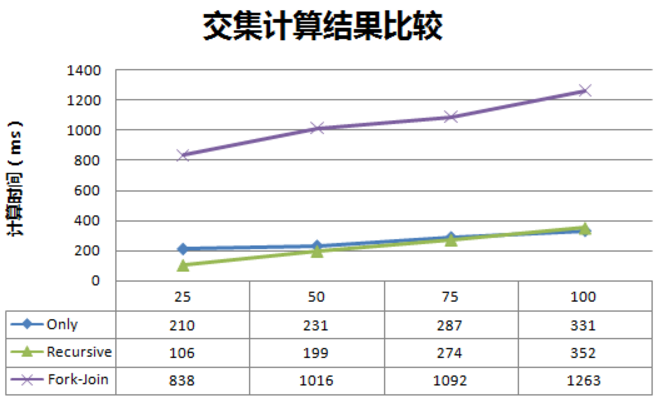
总体来说Only方案和Recursive方案不分伯仲,但在相对较小的给定合集计算场景下,Recursive存在优势,而且其进行了计算过程结果的缓存。
对于Fork-Join方案表示比较遗憾,当然这里可以采用另外一种更优的分解算法完成并行过程,但是就Redis本身作为通过单线程epoll模型实现的异步IO来说,可能客户端的并行计算在服务端仍然被串行化处理,另外,分治算法拆分数组的时间损耗也不能忽略。
转载:https://blog.csdn.net/xreztento/article/details/53289193
Tomcat工作原理详解的更多相关文章
- [转]Tomcat工作原理详解
一.Tomcat背景 自从JSP发布之后,推出了各式各样的JSP引擎.Apache Group在完成GNUJSP1.0的开发以后,开始考虑在SUN的JSWDK基础上开发一个可以直接提供Web服务的JS ...
- 块级格式化上下文(block formatting context)、浮动和绝对定位的工作原理详解
CSS的可视化格式模型中具有一个非常重要地位的概念——定位方案.定位方案用以控制元素的布局,在CSS2.1中,有三种定位方案——普通流.浮动和绝对定位: 普通流:元素按照先后位置自上而下布局,inli ...
- log4j-over-slf4j工作原理详解
log4j-over-slf4j工作原理详解 摘自:https://blog.csdn.net/john1337/article/details/76152906 置顶 2017年07月26日 17: ...
- Tomcat服务器原理详解
[目录]本文主要讲解Tomcat启动和部署webapp时的原理和过程,以及其使用的配置文件的详解.主要有三大部分: 第一部分.Tomcat的简介和启动过程 第二部分.Tomcat部署webapp 第三 ...
- ASP.NET页面与IIS底层交互和工作原理详解
转载自:http://www.cnblogs.com/lidabo/archive/2012/03/13/2393200.html 第一回: 引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是 ...
- ASP.NET页面与IIS底层交互和工作原理详解(第一回)
引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是站在一个比较高的层次上讲解Asp.Net.他们耐心.细致地告诉你如何一步步拖放控件.设置控件属性.编写CodeBehind代码,以实现某个特定 ...
- 交换机工作原理、MAC地址表、路由器工作原理详解
一:MAC地址表详解 说到MAC地址表,就不得不说一下交换机的工作原理了,因为交换机是根据MAC地址表转发数据帧的.在交换机中有一张记录着局域网主机MAC地址与交换机接口的对应关系的表,交换机就是根据 ...
- HTTP响应报文与工作原理详解
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到 ...
- 【转】HTTP响应报文与工作原理详解
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到 ...
随机推荐
- php 工作模式
PHP运行模式 1.cgi通用网关接口 (少用)2.fast-cgi常驻型的 cgi [ngixn常用]3.cli命令运行 (命令行用得多)4.web模块模式(apache等web服务器的运行模式)[ ...
- H5 APP开发必读,20个你不知道的Html5新特征和窍门
Jeffrey Way曾发表过一篇博文<28 HTML5 Features, Tips, and Techniques you Must Know >讲述了28个HTML5特征.窍门和技术 ...
- cms开发笔记2
1 创建数据库表 //配置文件CREATE TABLE IF NOT EXISTS `mc_config` ( `en_name` varchar(80) NOT NULL, `ch_name` va ...
- PL/SQL — 隐式游标
一.隐式游标的定义及其属性 定义 隐式游标由系统自动定义,非显示定义游标的DML语句即被赋予隐式游标属性.其过程由oracle控制,完全自动化.隐式游标的名称是SQL,不能对SQL游标显式地执行OPE ...
- UML用户指南--UML图简介
本节和大家一起学习一下UML图,这里主要介绍UML结构图和UML行为图两部分,下面让我们一起看一下UML图的详细介绍吧. UML图 这里再次提到对软件体系结构进行可视化.详述.构造和文档化,有5种最重 ...
- 长达半年的苹果发布会:亮点与槽点(iPhone5s,iPhone5c)
不知出于什么原因,今天凌晨召开的苹果发布会并没有视频直播,所以大家都守着The Verge家的图文直播.结果,苹果再一次用事实证明了他们没有保密体系,或者,故意没有保密体系. 整场发布会正经的亮点如下 ...
- JavaScript: top对象
一般的JS书里都会在讲框架集的时候讲top,这会让人误解,认为top对象只是代表框架集,其实top的含义应该是说浏览器直接包含的那一个页面对象,也就是说如果你有一个页面被其他页面以iframe的方式包 ...
- AMH4.2免费版手动编译升级Nginx1.8版本方法
从AMH免费版本停留在4.2版本之后就没有进行更新和升级,而且官方提供的解决文档也比较少,毕竟免费且没有盈利的产品还是没有多少兴趣的.但是,对于大部分网站环境来说,安装和使用AMH4.2免费版本还是够 ...
- 关于 IIS 上的 Speech 设置
在之前的开发过程中,发现在 微软各个版本的Speech中(从sdk5.1 到 最新的 Speech PlatFarme V11),在本地可以生成音频文件,但是在IIS上却生成无法生成完整的文件. 调试 ...
- Javascript事件传播
MicroSoft的设计是当事件在元素上触发时,该事件将接着在该节点的父节点触发,以此类推,事件一直沿着DOM树向上传播,直到到达顶层对象document元素.这种自底向上的事件传播方式称为" ...