python基础之小数据池、代码块、编码和字节之间换算
一、代码块
if True:
print(333)
print(666) for i in "":
print(i)
虽然上面的缩进的内容都叫代码块,但是他不是python中严格定义的代码块。
python中真正意义的代码块是什么?
块是一个python程序的文本,他是作为一个单元执行的。
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而对于一个文件中的两个函数,也分别是两个不同的代码块:
def func():
print(333) class A:
name = 'xiaojing'
交互模式下,每一行是一个代码块。
什么叫交互方式?就是咱们在cmd中进入Python解释器里面,每一行代码都是一个代码块
>>> i1 = 520 可以理解为这一行在一个文件中。
>>> i2 = 520 可以理解为这一行在另一个文件中。
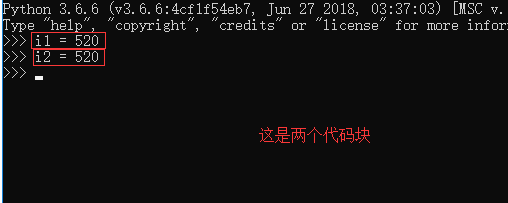
二、id is ==
在Python中,id是什么?id是内存地址,== 是比较的两边的数值是否相等,而 is 是比较的两边的内存地址是否相等。
如果内存地址相等,那么这两边其实是指向同一个内存地址。

name = 'shuaige' # 赋值
print('shuaige' == 'shuaige') # True, 数值相同 name2 = 'abc123'
name3 = 'abc123'
print(id(name2), id(name3)) # 2370269674608 2370269674608
print(name2 is name3) # True
在内存中id都是唯一的,如果两个变量指向的值的id相同,就证明他们在内存中是同一个。
is 判断的是两个变量的id值是否相同。
如果is是True, == 一定是True。== 是True,is不一定是True
三、小数据池(缓存机制,驻留机制)
1、介绍
小数据池的应用的数据类型: 一定范围内的整数,一定规则的字符串,bool值
小数据池是python对内存做的一个优化:
python将 -5 ~256 的整数,以及一定规则的字符串,bool值,进行了缓存,就是提前在内存中创建了池(容器),
在这些容器里固定的放了这些数据。
为什么这么做???
- 节省内存。
- 提高性能与效率。
2、一定范围内的整数
对于整数来说,小数据池的范围是 -5~256 ,如果多个变量都是指向同一个(在这个范围内的)数字,他们在内存中指向的都是一个内存地址。
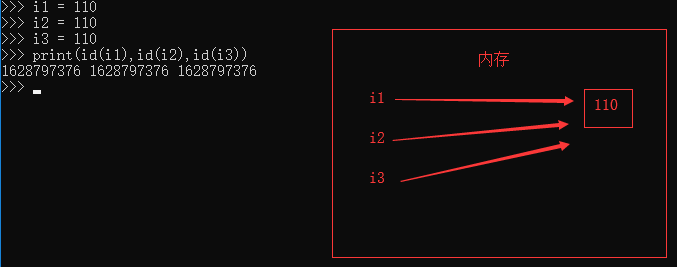
3、一定规则的字符串
1,字符串的长度为0或者1,默认都采用了驻留机制(小数据池)

2,字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认驻留。
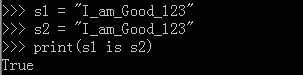
3,用乘法得到的字符串,分两种情况。
3.1 乘数为1时:仅含大小写字母,数字,下划线,默认驻留。

3.1.2含其他字符,长度<=1,默认驻留。
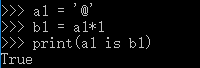
3.1.3含其他字符,长度>1,默认驻留
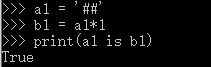
3.2 乘数>=2时:仅含大小写字母,数字,下划线,总长度<=20,默认驻留。
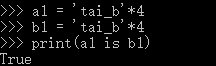
4,指定驻留。
from sys import intern
a = intern('hello!@'*20)
b = intern('hello!@'*20)
print(a is b)
#指定驻留是你可以指定任意的字符串加入到小数据池中,让其只在内存中创建一个对象,多个变量都是指向这一个字符串。
四、代码块与小数据池的关系
同样一段代码,为什么在交互方式中(cmd命令的终端)执行,和通过pycharm执行结果不同呢?
# pycharm 通过运行文件的方式执行下列代码:
i1 = 520
i2 = 520
print(i1 is i2) # 结果为True
通过交互方式中执行下面代码:
>>> i1 = 520
>>> i2 = 520
>>> print(i1 is i2) #结果为False
那为什么结果会不同呢?
对于pycharm:
在同一个代码块中的变量(数字,字符串),初始化对象的命令时,首先会从小数据池中找,如果没有找到,它会将变量与值的对应关系放到一个字典中,
同一个代码块中的其他变量遇到初始化对象的命令,他会先从字典中寻找,如果存在相同的值,他会复用,指向的都是同一个内存地址。
所以,在pycharm中的两行变量赋值中(实际上在同一个代码块中的赋值):
(注意:如果这个变量不是数字或者字符串,那么值相同,地址也是不同的)
s1 = 1000
s2 = 1000
print(s1 is s2) # True l1 = [1,2]
l2 = [1,2]
print(id(l1), id(l2)) # 1745841050760 1745840183304
print(l1 == l2) # True
print(l1 is l2) # False
对于cmd命令行:
而在cmd命令的终端中(交互模式),每一行都是一个代码块,因此在cmd命令的终端中,s1和s2是在不同的代码块,因此s1 is s2 是False
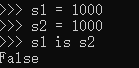
在不同的代码块:初始化对象的命令时,首先从小数据池中寻找,如果在小数据池,那么地址相同,如果不在小数据池中,则创建新的地址。
不同代码块中:
def func():
i1 = 1000
print(id(i1)) # def func1():
i2 = 1000
print(id(i2)) #
func()
func1()
# 一个函数是一个代码块,因此这里的i1的地址跟i2的地址不是同一个地址
总结:
同一代码块中:
如果变量在小数据池,那么地址相同,
如果不在小数据池,那么如果变量是数字或者字符串,也会复用地址,地址也相同,
如果变量不是数字或者字符串,那么地址不同。
不同一代码块中:
如果变量在小数据池,那么地址相同,
如果不在小数据池,那么地址不同。
五、编码二
"""
位:计算机时间里面的二进制
字节:8位二进制 等于 1个字节 # 这是不变的
字符:就是我们平常可以看到的文字、字母之类的,比如: ABC,我爱python等。
"""
ASCII: 只包含字母,数字,特殊字符。
8位二进制(bit)等于1个字节(Bytes),1个字节代表一个字符
A: 0000 0010
B: 0000 0011 unicode: 万国码,包含世界上所有的文字。
创建之初:16位二进制(bit)[即2个字节(Bytes)]代表1个字符
A :0001 0010 0000 0010
中:0011 0010 0000 0110
缺点:还不能完全覆盖世界上的所有文字 升级:32位二进制(bit)[即4个字节(Bytes)]代表1个字符
A :0000 0010 0100 0010 0000 0010 1000 0010
中:0001 0010 0010 0010 0000 0010 0010 0010
缺点:虽然能够覆盖全世界的文字,但是浪费资源。 对unicode升级 --> utf-8:最少用8位表示一个字符。
A :0000 0010 # 字母,数字,特殊字符按照ASCII规则,8位(1个字节)代表1个字符
欧:0000 0010 0100 0010 # 对于欧洲文字,使用16位(2个字节)代表1个字符
中:0000 0010 0001 0010 0000 0010 # 对于中文,使用24位(3个字节)代表1个字符 我国特有的编码 --> GBK(国标):字母,数字,特殊字符,中文。
A :0000 0010 # 字母,数字,特殊字符按照ASCII规则,8位(1个字节)代表1个字符
中:0000 0010 0001 0010 # 对于大部分中文,使用16位(2个字节)代表1个字符
# 国标只包含绝大部分我们日常使用的中文,对于一些比较偏的中文是没有的 1, 编码之间不能互相识别。
2, 网络传输,或者硬盘存储的010101,必须是以非uniocde编码方式的01010101. 3,大环境python3x:
str:内存(内部)编码方式为Unicode,因此python3中的字符串不能直接用于网络传输和硬盘存储,为了解决这个问题,就出现了bytes
bytes:python的基础数据类型之一,他和str相当于双胞胎,str拥有的所有方法,bytes类型都适用。 区别:
英文字母:
str:
表现形式:s1 = 'xiaohei'
内部编码方式:unicode bytes:
表现形式:b1 = b'xiaohei'
内部编码方式:非unicode 中文:
str:
表现形式:s1 = '小黑'
内部编码方式:unicode bytes:
表现形式:b1 = b'\xe5\xb0\x8f\xe9\xbb\x91'
内部编码方式:非unicode 如何使用:
你想将一部分内容(字符串)写入文件,或者通过网络socket传输,这样这部分内容(字符串)必须转化成bytes才可以进行。
在平时的代码中,可以直接使用字符串。 具体使用方法:encode编码 decode解码(bytes拥有str的所有方法) encode()不写参数,默认编码成utf-8 str ---> bytes encode 编码
非中文可以使用encode(),也可直接在字符串前加一个 b 表示bytes
s1 = 'xiaohei' b1 = b'xiaohei' # 等于 b1 = s1.encode()
b2 = b1.upper() print(s1, type(s1)) # xiaohei <class 'str'> print(b1, type(b1)) # b'xiaohei' <class 'bytes'>
print(b2, type(b2)) # b'XIAOHEI' <class 'bytes'> 中文只能使用encode()
s1 = '小黑'
b1 = s1.encode('utf-8')
b2 = s1.encode('gbk')
print(b1) # b'\xe5\xb0\x8f\xe9\xbb\x91'
print(b2) # b'\xd0\xa1\xba\xda' bytes ---> str decode 解码
b1 = b'\xd0\xa1\xba\xda' # gbk的bytes
s2 = b1.decode('gbk') # 对应用gbk的解码
print(s2) # 小黑
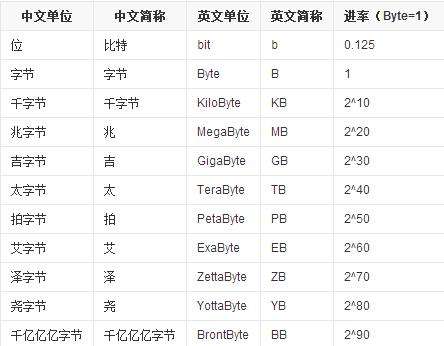
六、字节单位之间的换算
位(bit,缩写为b)是存储器的最小单位,可以表示一位二进制数。1字节(Byte,缩写为B)由8个位组成,即1Byte=8bit,是存储器的基本单位,通常被作为一个存储单元。通常情况下,把B称为字节、b称为字位、KB称为千字节、MB称为兆字节、GB称为吉字节。
1字位(bit)=1个二进制数
1字节(Byte)=8字位=8个二进制数
1B=8b
1KB=1024B
1MB=1024KB
1GB=1024MB
python基础之小数据池、代码块、编码和字节之间换算的更多相关文章
- python基础之小数据池、代码块、编码
一.代码块.if True: print(333) print(666) while 1: a = 1 b = 2 print(a+b) for i in '12324354': print(i) 虽 ...
- python基础之小数据池
一,id,is,== 在Python中,id是什么?id是内存地址,比如你利用id()内置函数去查询一个数据的内存地址: name = '太白' print(id(name)) # 158583128 ...
- python基础之小数据池,is和==区别 编码问题
主要内容 小数据池,is和==区别 编码问题 小数据池 一种缓存机制,也称为驻留机制,是为了能更快提高一些字符串和整数的处理速度is 和 == 的区别 == 主要指对变量值是否相等的判断,只要数值相同 ...
- Python基础篇 -- 小数据池和再谈编码
小数据池 1. id() 通过id()可以查看到一个变量表示的值在内存中的地址 s = "Agoni" print(id(s)) # 2410961093272 2. is 和 = ...
- python之路--小数据池,再谈编码,is和 == 的区别
一 . 小数据池 # 小数据池针对的是: int, str, bool 在py文件中几乎所有的字符串都会缓存. # id() 查看变量的内存地址 s = 'attila' print(id(s)) 二 ...
- 百万年薪python之路 -- 小数据池和代码块
1.小数据池和代码块 # 小数据池 -- 缓存机制(驻留机制) # == 判断两边内容是否相等 # a = 10 # b = 10 # print(a == b) # is 是 # a = 10 # ...
- 百万年薪python之路 -- 小数据池和代码块练习
1.请用代码验证 "alex" 是否在字典的值中? info = {'name':'王刚蛋','hobby':'铁锤','age':'18',...100个键值对} info = ...
- python 浅谈小数据池和编码
⼀. ⼩数据池 在说⼩数据池之前. 我们先看⼀个概念. 什么是代码块: 根据提示我们从官⽅⽂档找到了这样的说法: A Python program is constructed from code b ...
- Python细节(二)小数据池
3.8小数据池 python是由代码块构成的 代码块,一个模块.一个函数,一个类,一个文件,eval(),exec()执行的时候也是一个代码块 1.内存地址 id() 通过id() 我们可以查看到一个 ...
随机推荐
- linux学习笔记-linux主机上传下载文件至linux虚拟机的方法
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! 1.上传文件 scp -r file 用户名@ip地址:目标目录 2.下载文件 scp -r 用户名@ip地址:文件 目标目录
- 跨进程SharedPreferences异常。
诡异的SharedPreferences异常,在ACC之后,SharedPreferences获取不到值了,但是另一个应用可以获取到值.同样的方法,一个正常一个异常. Context c = null ...
- 如何程序化的构造Hibernate配置 // How to initialize Hibernate programmably
Java为什么被人诟病,因为一切都是过度设计.Hibernate其实就是实现了一套JPA的ORM,不过用极度冗赘的配置方式,nodejs Sequelize.js,甚至Python SQLAlchem ...
- Android 网络框架 Retrofit2
概述 Retrofit是一个OkHttp网络请求框架的封装库,Retrofit通过注解配置网络参数,可以按照我们的规则去构造实际的HTTP请求,能够灵活设置URL.头部.请求体.返回值等,是目前最优雅 ...
- webpack安装、基本配置
文章结构: 什么是webpack? 安装webpack webpack基本配置 一.什么是webpack? 在学习react时发现大部分文章都是react和webpack结合使用的,所以在学react ...
- Mysql增量写入Hdfs(二) --Storm+hdfs的流式处理
一. 概述 上一篇我们介绍了如何将数据从mysql抛到kafka,这次我们就专注于利用storm将数据写入到hdfs的过程,由于storm写入hdfs的可定制东西有些多,我们先不从kafka读取,而先 ...
- Python爬虫之正则表达式(1)
廖雪峰正则表达式学习笔记 1:用\d可以匹配一个数字:用\w可以匹配一个字母或数字: '00\d' 可以匹配‘007’,但是无法匹配‘00A’; ‘\d\d\d’可以匹配‘010’: ‘\w\w\d’ ...
- SQLServer之创建全文索引
创建全文索引的必须条件 必须具有全文目录,然后才能创建全文索引. 目录是包含一个或多个全文索引的虚拟容器. 使用SSMS数据库管理工具创建全文索引 1.连接数据库,选择数据库,选择数据表->右键 ...
- #021 Java复习第一天
上学期在慧河工作室学习简单过java到面向对象就停止了 现在有事情又要用到java发现全忘了..... 快速复习一下 网课PPT 计算机: 硬件 + 软件 主要硬件: cpu :cpu是一个计算机的运 ...
- Java11新特性!
Java11又出新版本了,我还在Java8上停着.不过这也挡不住我对他的热爱,忍不住查看了一下他的新性能,由于自己知识有限,只总结了以下八个特性: 1.本地变量类型推断 什么是局部变量类型推断? va ...