python网络爬虫学习笔记(二)BeautifulSoup库
Beautiful Soup库也称为beautiful4库、bs4库,它可用于解析HTML/XML,并将所有文件、字符串转换为'utf-8'编码。HTML/XML文档是与“标签树一一对应的。具体地说,Beautiful Soup库是可以解析、遍历、维护HTML/XML文件的“标签树”的功能库。本文总结了BeautifulSoup的基本使用方法。
一、Beautiful Soup库基本元素
库的比较常见的引用方式如下
from bs4 import BeautifulSoup #从Beautiful Soup库引入BeautifulSoup类
import bs4 #直接引入Beautiful Soup库
Beautiful Soup库可用的解析器有以下4种:
- bs4的HTML解析器:BeautifulSoup(mk, 'html.parser')
- lxml的HTML解析器:BeautifulSoup(mk, 'lxml')
- lxml的XML解析器:BeautifulSoup(mk, 'xml')
- html5lib的解析器:BeautifulSoup(mk, 'html5lb')
BeautifulSoup类对应一个HTML/XML文档的全部内容,其5种基本元素罗列如下:
- Tag:标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾
- Name:标签的名字,<p>...</p>的名字是'p',格式<tag>.name
- Attributes:标签的属性,字典形式组织,格式<tag>.attrs
- NavigableString:标签内非属性字符串,<>...</>中字符串,格式<tag>.string
- Comment:标签内字符串的注释部分,一种特殊的Comment类型
下面一段运行实例,其中demo是一段HTML代码

我们看一下a标签,其父标签以及祖父标签的名字

接下来,解析a标签的属性

从中可以看到,属性是字典类型。
再看一看标签本身的类型

标签的NavigableString元素

获取标签的Comment(与获取NavigableString比较)

p标签包含b标签,然而p.string并不包含b标签,这说明NavigableString是可以跨越多个标签层次的。
二、利用Beautiful Soup库遍历HTML内容
前面提到,HTML文档其实就是一棵标签树。对HTML的遍历即是对标签树的遍历。遍历的方式分为上行遍历、下行遍历和平行遍历。
2.1 标签树的下行遍历
标签树的下行遍历包含三个属性
- .contents:子节点的列表,将<tag>所有儿子节点存入列表
- .children:子节点的迭代类型,与.content相似,用于循环遍历儿子节点
- .descendants:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
使用.contents获取子节点列表的示例如下
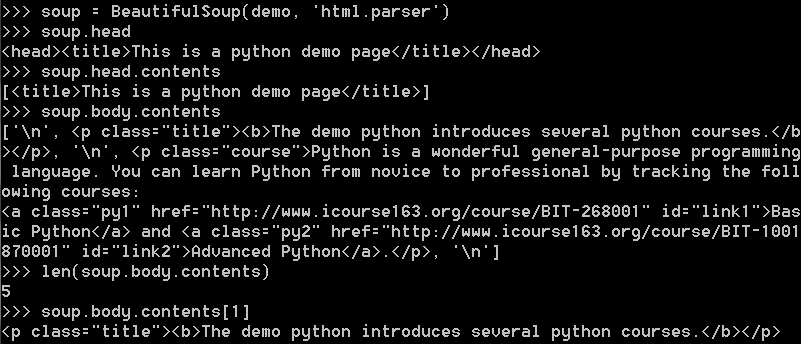
一般地,如果要遍历子节点,可以用如下代码框架
for child in soup.body.children:
print(child)
如果要遍历子孙节点,则可以用如下代码框架
for child in soup.body.descendents:
print(child)
2.2 标签树的上行遍历
上行遍历包含的属性罗列如下:
- .parent:节点的父亲标签
- .parents:节点先辈标签的迭代模型,用于循环遍历先辈节点
下面是使用.parent获取父标签的一段实例
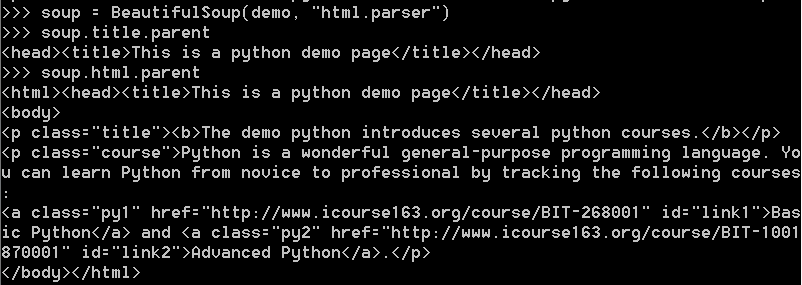
这里看到,html是最高级的标签,因此其父标签即为自己。
一般地,对标签树进行上行遍历,可采用如下代码框架
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
相应给出一段运行实例:打印所有先辈标签的名字

2.3 标签树的平行遍历
Beautiful Soup库提供以下四种平行遍历属性:
- .next_sibling:返回按照HTML文本顺序的下一个平行节点标签
- .previous_sibling:返回按照HTML文本顺序的上一个平行节点标签
- .next_siblings:迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
- .previous_siblings:迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
值得注意的是,平行遍历是在同一个父节点下建立的。
一段运行实例
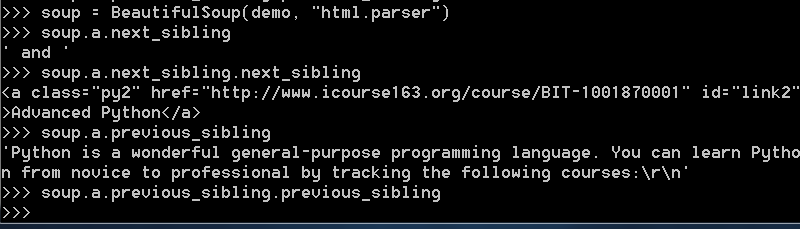
最后,soup.a.previous_sibling.previous_sibling没有输出,说明a标签的前一个再前一个节点标签为空。
一般地,标签树的平行遍历可采用如下代码框架
for sibling in soup.a.next_siblings: #遍历后续节点
print(sibling)
for sibling in soup.a.previous_siblings: #遍历前续节点
print(sibling)
三、基于Beautiful Soup库的HTML格式输出
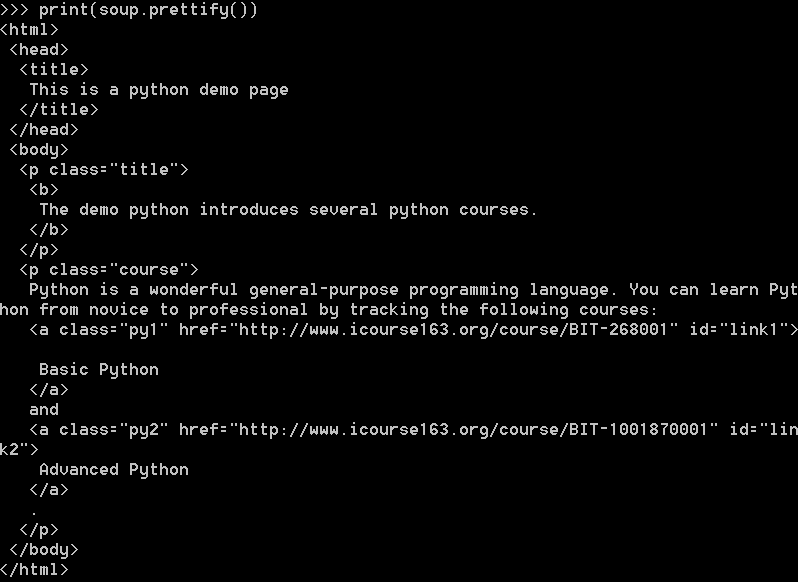
bs4库提供了prettify()方法,用于对HTML的内容给出更友好的输出。
下面是一段运行实例
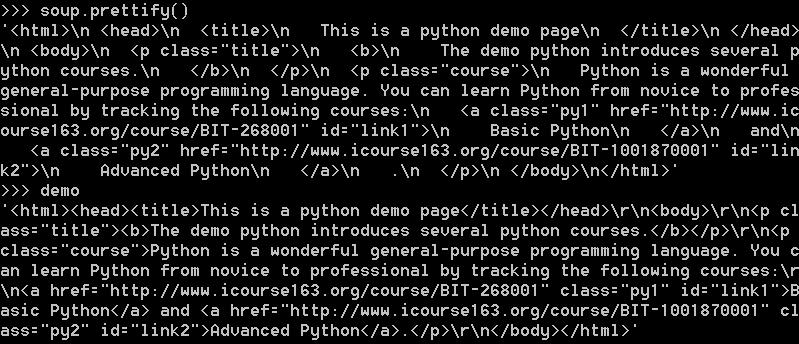
看到pretiffy()在每个标签后添加了换行符'\n'。将相关信息打印出来,得到如下结果
prettify()也可以对某一个标签进行处理,示例如下

相关内容为笔者根据中国大学MOOC网站嵩天教授的python爬虫课程所撰写的学习笔记,感谢中国MOOC学习平台提供的学习资源与嵩老师的授课。
python网络爬虫学习笔记(二)BeautifulSoup库的更多相关文章
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- python网络爬虫学习笔记(一)Request库
一.Requests库的基本说明 引入Rquests库的代码如下 import requests 库中支持REQUEST, GET, HEAD, POST, PUT, PATCH, DELETE共7个 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- python爬虫学习(一):BeautifulSoup库基础及一般元素提取方法
最近在看爬虫相关的东西,一方面是兴趣,另一方面也是借学习爬虫练习python的使用,推荐一个很好的入门教程:中国大学MOOC的<python网络爬虫与信息提取>,是由北京理工的副教授嵩天老 ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
- python网络爬虫(三)requests库的13个控制访问参数及简单案例
酱酱~小编又来啦~
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
随机推荐
- linux 配置ftp服务器
在Linux中搭建一个FTP服务器 [实现步骤] 1.检查安装vsftpd服务器 以root进入终端后(其他账户进入终端的可以用su root 输入密码后进入root 模式)之后,在终端命令窗口输入以 ...
- I/O 模型与 Java
本文主要记录 Java 中 I/O 模型及相关知识点 .另,由于自身知识水平有限,如有不正之处,望各位能够谅解,欢迎批评指正! 一.I/O 基础 由于 Java 中 I/O 相关的 API ,无论是 ...
- 远程过程调用发展历程 WebAPI GRPC Hprose
作者:马秉尧链接:https://www.zhihu.com/question/23299132/answer/109978084来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注 ...
- JavaScript原型链及继承
在JavaScript中,所有的东西都是对象,但是JavaScript中的面向对象并不是面向类,而是面向原型的,这是与C++.Java等面向对象语言的区别,比较容易混淆,因此把我自己学习的过程记录下来 ...
- 田螺便利店—filezilla实现Linux和windows通信(二)
filezilla,FileZilla是一个免费开源的FTP软件,分为客户端版本和服务器版本,具备所有的FTP软件功能.可控性.有条理的界面和管理多站点的简化方式使得Filezilla客户端版成为一个 ...
- 将jar包安装到本地repository中
mvn install:install-file -Dfile=G:/lcn_springboot2.0/tx-plugins-db-4.1.2.jar -DgroupId=com.codingapi ...
- vue day6 分页显示
@{ ViewBag.Title = "Home Page"; Layout = null; } <!DOCTYPE html> <html> <he ...
- Linux下安装gradle
Linux下安装gradle 1. Gradle 是以 Groovy 语言为基础,面向Java应用为主.基于DSL(领域特定语言)语法的自动化构建工具 下面就描述一下如何在linux环境下安装配置gr ...
- Windows环境下C++中关于文件结束符的问题
参考资料:http://www.cnblogs.com/day-dayup/p/3572374.html 一.前言 在不同的OS环境下,程序中对应的文件结束符有所不一样,根据<C++ Prime ...
- P2930 [USACO09HOL]假期绘画Holiday Painting
线段树水题,考虑到只有15列,所以我们对于每一列,我们都去维护一个线段树. 现在来考虑一下修改操作,因为每次修改的时候,我们都是将黑的改成白的,白的改成黑的,所以我们对线段树的每个节点维护当前这段区间 ...