python简单爬虫 使用pandas解析表格,不规则表格
url = http://www.hnu.edu.cn/xyxk/xkzy/zylb.htm
部分表格如图:

部分html代码:
<table class="MsoNormalTable" style="width:353.0pt;margin-left:4.65pt;border-collapse:collapse;border:none; mso-border-alt:solid windowtext .5pt;mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-border-insideh:.5pt solid windowtext;mso-border-insidev:.5pt solid windowtext" width="471" cellspacing="0" cellpadding="0" border="1">
<tbody>
<tr class="firstRow" style="mso-yfti-irow:0;mso-yfti-firstrow:yes;height:36.75pt">
<td style="width:170.0pt;border:solid windowtext 1.0pt;mso-border-alt: solid windowtext .5pt;padding:0cm 5.4pt 0cm 5.4pt;height:36.75pt" width="227"><p class="MsoNormal" style="text-align:center;margin-top:6.0pt;margin-right:0cm; margin-bottom:6.0pt;margin-left:0cm;mso-para-margin-top:.5gd;mso-para-margin-right: 0cm;mso-para-margin-bottom:.5gd;mso-para-margin-left:0cm; mso-pagination:widow-orphan"><strong><span style="font-size:9.0pt;font-family: 宋体;mso-bidi-font-family:宋体;mso-font-kerning:0pt">学院<span lang="EN-US">
<o:p></o:p></span></span></strong></p></td>
<td style="width:183.0pt;border:solid windowtext 1.0pt; border-left:none;mso-border-left-alt:solid windowtext .5pt;mso-border-alt: solid windowtext .5pt;padding:0cm 5.4pt 0cm 5.4pt;height:36.75pt" width="244" nowrap=""><p class="MsoNormal" style="text-align:center;margin-top:6.0pt;margin-right:0cm; margin-bottom:6.0pt;margin-left:0cm;mso-para-margin-top:.5gd;mso-para-margin-right: 0cm;mso-para-margin-bottom:.5gd;mso-para-margin-left:0cm; mso-pagination:widow-orphan"><strong><span style="font-size:9.0pt;font-family: 宋体;mso-bidi-font-family:宋体;mso-font-kerning:0pt">专业名称<span lang="EN-US">
<o:p></o:p></span></span></strong></p></td>
</tr>
<tr style="mso-yfti-irow:1;height:16.5pt">
<td rowspan="4" style="width:170.0pt;border:solid windowtext 1.0pt; border-top:none;mso-border-top-alt:solid windowtext .5pt;mso-border-alt:solid windowtext .5pt; padding:0cm 5.4pt 0cm 5.4pt;height:16.5pt" width="227"><p class="MsoNormal" style="text-align:center;margin-top:6.0pt;margin-right:0cm; margin-bottom:6.0pt;margin-left:0cm;mso-para-margin-top:.5gd;mso-para-margin-right: 0cm;mso-para-margin-bottom:.5gd;mso-para-margin-left:0cm; mso-pagination:widow-orphan"><span style="font-size:9.0pt;font-family:宋体; mso-bidi-font-family:宋体;mso-font-kerning:0pt">土木工程学院<span lang="EN-US">450
<o:p></o:p></span></span></p></td>
<td style="width:183.0pt;border-top:none;border-left:none; border-bottom:solid windowtext 1.0pt;border-right:solid windowtext 1.0pt; mso-border-top-alt:solid windowtext .5pt;mso-border-left-alt:solid windowtext .5pt; mso-border-alt:solid windowtext .5pt;padding:0cm 5.4pt 0cm 5.4pt;height:16.5pt" width="244" nowrap=""><p class="MsoNormal" style="text-align:center;margin-top:6.0pt;margin-right:0cm; margin-bottom:6.0pt;margin-left:0cm;mso-para-margin-top:.5gd;mso-para-margin-right: 0cm;mso-para-margin-bottom:.5gd;mso-para-margin-left:0cm; mso-pagination:widow-orphan"><span style="font-size:9.0pt;font-family:宋体; mso-bidi-font-family:宋体;mso-font-kerning:0pt">土木工程<span lang="EN-US">
<o:p></o:p></span></span></p></td>
</tr>
......
</tbody>
</table>
用pandas解析表格,代码如下:
import pandas as pd
url = 'http://www.hnu.edu.cn/xyxk/xkzy/zylb.htm' table = pd.read_html(url)
pd.set_option('display.max_rows', None) # 显示全部的行
with open("湖南大学学院与专业.txt", "wt", encoding='utf8') as out_file: # 保存为txt文件
for i in table:
out_file.write(str(i)+'\n')
运行结果如下(部分):
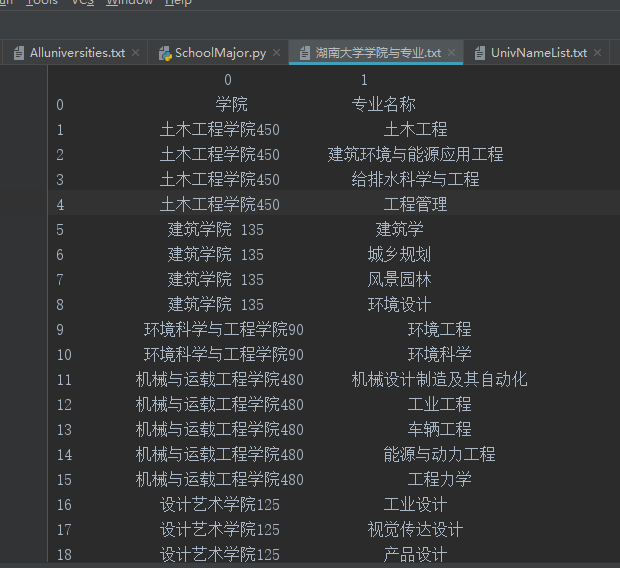
非常简洁高效!
python简单爬虫 使用pandas解析表格,不规则表格的更多相关文章
- python简单爬虫 用lxml解析页面中的表格
目标:爬取湖南大学2018年在各省的录取分数线,存储在txt文件中 部分表格如图: 部分html代码: <table cellspacing="0" cellpadding= ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- python简单爬虫一
简单的说,爬虫的意思就是根据url访问请求,然后对返回的数据进行提取,获取对自己有用的信息.然后我们可以将这些有用的信息保存到数据库或者保存到文件中.如果我们手工一个一个访问提取非常慢,所以我们需要编 ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
- python 简单爬虫(beatifulsoup)
---恢复内容开始--- python爬虫学习从0开始 第一次学习了python语法,迫不及待的来开始python的项目.首先接触了爬虫,是一个简单爬虫.个人感觉python非常简洁,相比起java或 ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
随机推荐
- Python模块1
序列化模块: 将原本的字典.列表等内容转换成一个字符串的过程就叫做序列化. 序列化的目的 1.以某种存储形式使自定义对象持久化: 2.将对象从一个地方传递到另一个地方. 3.使程序更具维护性. jso ...
- Tomcat配置文件入门
转自:http://blog.csdn.net/jubincn/article/details/4856293 Tomcat 基本配置 tomcat读取配置文件 首先简单说一下tomcat是如何读取配 ...
- javascript 之 数组
定义:var colors=new Array(); var colors=new Array(3); var colors=new Array('red'); var colors=['red',' ...
- Python 使用有道翻译
最近想将一些句子翻译成不同的语言,最开始想使用Python向有道发送请求包的方式进行翻译. 这种翻译方式可行,不过只能翻译默认语言,不能选定语言,于是我研究了一下如何构造请求参数,其中有两个参数最复杂 ...
- 新的尝试!ComponentOne WinForm 和 .NET Core 3.0
在微软 Build 2018 开发者大会上,.NET 团队公布了 .NET Core 的下一个主要版本 .NET Core 3.0 的规划蓝图:.NET Core 3将开始支持Windows桌面应用程 ...
- ComponentOne 2019V1:全面支持 Visual Studio 2019
ComponentOne Enterprise 2019V1已经正式发布,本次更新的最大亮点就是 ComponentOne 控件全面支持 Visual Studio 2019. 作为一款专注于企业应用 ...
- 对java中路径的一些理解
开始前先贴一下项目结构 public class TestLocation { @Test public void test1(){ String s1 = Objects.requireNonNul ...
- H5外包团队 技术分享 基于H5+的项目分享
项目截图: 有H5项目需求欢迎联系我们 我们提供免费的项目评估报价 QQ:372900288 WX:Liuxiang0884
- Scss 与 Sass 是什么,他们的区别在哪里?
转载自:http://yunkus.com/difference-between-scss-sass/ 要想了解Scss 与 Sass 是什么以及他们的区别又在哪里,我们不过不先从他们各自的定义说起. ...
- kafka知识点
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...