神经网络权值初始化方法-Xavier
https://blog.csdn.net/u011534057/article/details/51673458
https://blog.csdn.net/qq_34784753/article/details/78668884
https://blog.csdn.net/kangroger/article/details/61414426
https://www.cnblogs.com/lindaxin/p/8027283.html
神经网络中权值初始化的方法
《Understanding the difficulty of training deep feedforward neural networks》
可惜直到近两年,这个方法才逐渐得到更多人的应用和认可。
为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等。
基于这个目标,现在我们就去推导一下:每一层的权重应该满足哪种条件。
文章先假设的是线性激活函数,而且满足0点处导数为1,即
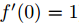
现在我们先来分析一层卷积: 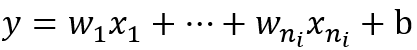
其中ni表示输入个数。
根据概率统计知识我们有下面的方差公式:
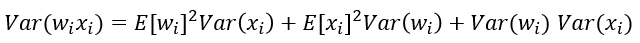
特别的,当我们假设输入和权重都是0均值时(目前有了BN之后,这一点也较容易满足),上式可以简化为:
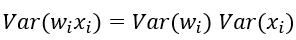
进一步假设输入x和权重w独立同分布,则有:
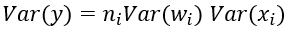
于是,为了保证输入与输出方差一致,则应该有:
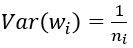
对于一个多层的网络,某一层的方差可以用累积的形式表达:
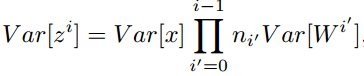
特别的,反向传播计算梯度时同样具有类似的形式:
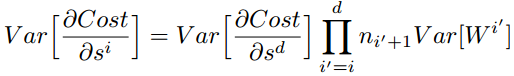
综上,为了保证前向传播和反向传播时每一层的方差一致,应满足:
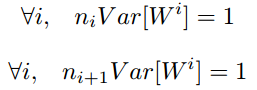
但是,实际当中输入与输出的个数往往不相等,于是为了均衡考量,最终我们的权重方差应满足:
——————————————————————————————————————— 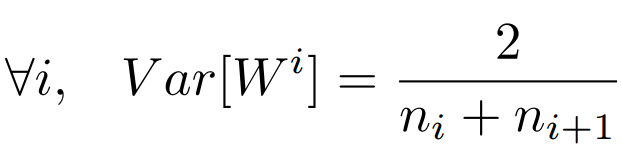
———————————————————————————————————————
学过概率统计的都知道 [a,b] 间的均匀分布的方差为:
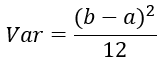
因此,Xavier初始化的实现就是下面的均匀分布:
——————————————————————————————————————————
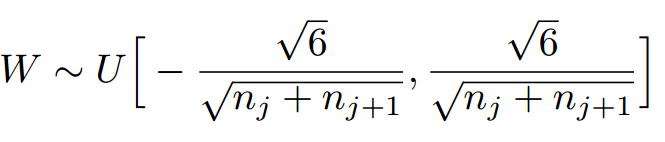
caffe的Xavier实现有三种选择
(1) 默认情况,方差只考虑输入个数:
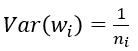
(2) FillerParameter_VarianceNorm_FAN_OUT,方差只考虑输出个数:
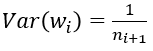
(3) FillerParameter_VarianceNorm_AVERAGE,方差同时考虑输入和输出个数:
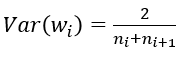
之所以默认只考虑输入,我个人觉得是因为前向信息的传播更重要一些
———————————————————————————————————————————
Tensorflow 调用接口
https://www.tensorflow.org/api_docs/python/tf/glorot_uniform_initializer
tf.glorot_uniform_initializer
Aliases:
tf.glorot_uniform_initializertf.keras.initializers.glorot_uniform
tf.glorot_uniform_initializer(
seed=None,
dtype=tf.float32
)
Defined in tensorflow/python/ops/init_ops.py.
The Glorot uniform initializer, also called Xavier uniform initializer.
It draws samples from a uniform distribution within [-limit, limit] where limit is sqrt(6 / (fan_in + fan_out))where fan_in is the number of input units in the weight tensor and fan_out is the number of output units in the weight tensor.
Reference: http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf
Args:
seed: A Python integer. Used to create random seeds. Seetf.set_random_seedfor behavior.dtype: The data type. Only floating point types are supported.
Returns:
An initializer.
Mxnet 调用接口
https://mxnet.apache.org/api/python/optimization/optimization.html#mxnet.initializer.Xavier
class mxnet.initializer.Xavier(rnd_type='uniform', factor_type='avg', magnitude=3)[source]
Returns an initializer performing “Xavier” initialization for weights.
This initializer is designed to keep the scale of gradients roughly the same in all layers.
By default, rnd_type is 'uniform' and factor_type is 'avg', the initializer fills the weights with random numbers in the range of [−c,c][−c,c], where c=3.0.5∗(nin+nout)−−−−−−−−−√c=3.0.5∗(nin+nout). ninnin is the number of neurons feeding into weights, and noutnout is the number of neurons the result is fed to.
If rnd_type is 'uniform' and factor_type is 'in', the c=3.nin−−−√c=3.nin. Similarly when factor_type is 'out', the c=3.nout−−−√c=3.nout.
If rnd_type is 'gaussian' and factor_type is 'avg', the initializer fills the weights with numbers from normal distribution with a standard deviation of 3.0.5∗(nin+nout)−−−−−−−−−√3.0.5∗(nin+nout).
| Parameters: |
|
|---|
神经网络权值初始化方法-Xavier的更多相关文章
- caffe中权值初始化方法
首先说明:在caffe/include/caffe中的 filer.hpp文件中有它的源文件,如果想看,可以看看哦,反正我是不想看,代码细节吧,现在不想知道太多,有个宏观的idea就可以啦,如果想看代 ...
- [PyTorch 学习笔记] 4.1 权值初始化
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson4/grad_vanish_explod.py 在搭建好网络 ...
- pytorch(14)权值初始化
权值的方差过大导致梯度爆炸的原因 方差一致性原则分析Xavier方法与Kaiming初始化方法 饱和激活函数tanh,非饱和激活函数relu pytorch提供的十种初始化方法 梯度消失与爆炸 \[H ...
- 权值初始化 - Xavier和MSRA方法
设计好神经网络结构以及loss function 后,训练神经网络的步骤如下: 初始化权值参数 选择一个合适的梯度下降算法(例如:Adam,RMSprop等) 重复下面的迭代过程: 输入的正向传播 计 ...
- PyTorch 学习笔记(四):权值初始化的十种方法
pytorch在torch.nn.init中提供了常用的初始化方法函数,这里简单介绍,方便查询使用. 介绍分两部分: 1. Xavier,kaiming系列: 2. 其他方法分布 Xavier初始化方 ...
- python面向对象的基础语法(dir内置函数、self参数、初始化方法、内置方法和属性)
面相对象基础语法 目标 dir 内置函数 定义简单的类(只包含方法) 方法中的 self 参数 初始化方法 内置方法和属性 01. dir 内置函数(知道) 在 Python 中 对象几乎是无所不在的 ...
- 深度学习----Xavier初始化方法
“Xavier”初始化方法是一种很有效的神经网络初始化方法,方法来源于2010年的一篇论文<Understanding the difficulty of training deep feedf ...
- 网络权重初始化方法总结(下):Lecun、Xavier与He Kaiming
目录 权重初始化最佳实践 期望与方差的相关性质 全连接层方差分析 tanh下的初始化方法 Lecun 1998 Xavier 2010 ReLU/PReLU下的初始化方法 He 2015 for Re ...
- 深度学习——Xavier初始化方法
“Xavier”初始化方法是一种很有效的神经网络初始化方法,方法来源于2010年的一篇论文<Understanding the difficulty of training deep feedf ...
随机推荐
- Android性能优化系列之apk瘦身
Android性能优化系列之布局优化 Android性能优化系列之内存优化 为什么APK要瘦身.APK越大,在下载安装过程中.他们耗费的流量会越多,安装等待时间也会越长:对于产品本身,意味着下载转化率 ...
- TCP/IP 三次握手,温故知新
今天看网络编程.又又一次看了一遍三次握手.曾经只知道连接有三次握手.今天发现原来断开也有三次握手. 三次握手:指通信两方彼此交换三次信息. 三次握手是在存在数据报丢失.反复和延迟的情况下,确保通信两方 ...
- LeetCode——4Sum & 总结
LeetCode--4Sum & 总结 前言 有人对 Leetcode 上 2Sum,3Sum,4Sum,K Sum问题作了总结: http://blog.csdn.net/nanjunxia ...
- 关于https中的算法
1,对称加密算法,是指加密和解密使用相同的密钥,典型的算法有RSA,DSA,DH 2,非对称加密算法:又称为公钥加密算法,是指加密和解密使用不同的密钥,公共的公钥用于加密,私钥用于解密,比如第一次请求 ...
- 在sublime text3中安装sass编译scss文件
一 搭建环境 首先安装ruby环境,不然会编译失败,在这里下载ruby ,安装的时候选择第二项 在cmd中输入gem -v 显示版本号说明ruby安装成功 待ruby安装成功后,在cmd中输入 gem ...
- SQL 中 replace 替换字符串中的字符 ''
update CfmRcd set reconsource=replace(reconsource,'''',''), cmffile =replace(cmffile,'''',''), cfmda ...
- [Windows Azure] Getting Started with Windows Azure SQL Database
In this tutorial you will learn the fundamentals of Windows Azure SQL Database administration using ...
- win10+VS2015+boost_1.60.0
安装boost库的初衷boost库是一个C++'准'标准库,对于一个C++程序员来说,了解强大的boost库是很有必要的.当然,在学习使用这样一个强大的库之前,首先要学会安装.本文讲述了boost_1 ...
- jsonrpc使用
jsonrpc使用 1.什么是rpc RPC(Remote Procedure Call)远程过程调用,简单说就是通过网络请求服务,不需要了解底层网络技术的协议. 常用语分布式应用程序. 2.rpc数 ...
- c语言中条件编译相关的预编译指令
一. 内容概述 本文主要介绍c语言中条件编译相关的预编译指令,包括#define.#undef.#ifdef.#ifndef.#if.#elif.#else.#endif.defined. 二.条件编 ...