k最邻近算法——使用kNN进行手写识别
上篇文章中提到了使用pillow对手写文字进行预处理,本文介绍如何使用kNN算法对文字进行识别。
基本概念
k最邻近算法(k-Nearest Neighbor, KNN),是机器学习分类算法中最简单的一类。假设一个样本空间被分为几类,然后给定一个待分类的特征数据,通过计算距离该数据的最近的k个样本来判断这个数据属于哪一类。如果距离待分类属性最近的k个类大多数都属于某一个特定的类,那么这个待分类的数据也就属于这个类。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。kNN在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别,在决策时,只与极少量的相邻样本有关。通常,k是不大于20的整数。
下图所示,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
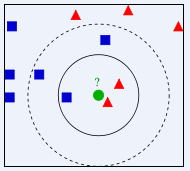
在理想情况下,k值选择1,即只选择最近的邻居。在现实生活中往往没这么理想,比如对于价格来说,有些顾客消息闭塞,可能会为 “最近的邻居”多付很多钱,所以应当货比三家,多选择一些邻居,取均值来减少噪声。实际上,k值过大或过小都将影响结果。
计算过程
过程如下:
- 计算训练集中的点与当前点之间的距离;
- 按距离降序排序;
- 选取与当前点距离最小的k个点;
- 如果是数值型数据,计算前k个点的均值;如果是离散数据,计算前k个点所在类别出现的频率;
- 如果是数值型数据,返回前k个点的均值作为预测数值;如果是离散数据,返回前k个点出现频率最高的类别作为预测分类。
代码如下:
from os import listdir #将图片文件转换为向量
def img2vector(filename):
with open(filename) as fobj:
arr = fobj.readlines() vec, demension = [], len(arr)
for i in range(demension):
line = arr[i].strip()
for j in range(demension):
vec.append(int(line[j])) return vec #读取训练数据
def createDataset(dir):
dataset, labels = [], []
files = listdir(dir)
for filename in files:
label = int(filename[0])
labels.append(label)
dataset.append(img2vector(dir + '/' + filename)) return dataset, labels #计算谷本系数
def tanimoto(vec1, vec2):
c1, c2, c3 = 0, 0, 0
for i in range(len(vec1)):
if vec1[i] == 1: c1 += 1
if vec2[i] == 1: c2 += 1
if vec1[i] == 1 and vec2[i] == 1: c3 += 1 return c3 / (c1 + c2 - c3) def classify(dataset, labels, testData, k=20):
distances = [] for i in range(len(labels)):
d = tanimoto(dataset[i], testData)
distances.append((d, labels[i])) distances.sort(reverse=True)
#key label, value count of the label
klabelDict = {}
for i in range(k):
klabelDict.setdefault(distances[i][1], 0)
klabelDict[distances[i][1]] += 1 / k #按value降序排序
predDict = sorted(klabelDict.items(), key=lambda item: item[1], reverse=True)
return predDic dataset, labels = createDataset('trainingDigits')
testData = img2vector('testDigits/8_19.txt')
print(classify(dataset, labels, testData))
我们事先使用pillow对手写数字进行了二值化处理,形成一个32*32的矩阵,并将每个训练样本保存到一个txt文件,文件名以数字开头,这个数字就是手写数字的label,如3_1.txt,其中的内容是:
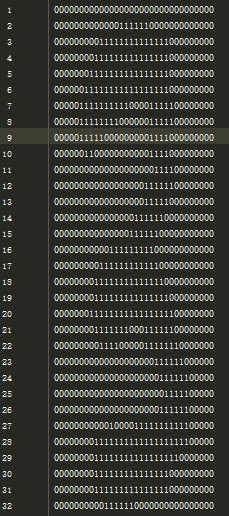 由于特征值仅由0和1构成,可以将二维的样本数据保存到一维数组,img2vector完成了数据的转换。在计算相似度时,使用谷本系数(Tanimoto)计算有限离散集之间的距离,其公式是:
由于特征值仅由0和1构成,可以将二维的样本数据保存到一维数组,img2vector完成了数据的转换。在计算相似度时,使用谷本系数(Tanimoto)计算有限离散集之间的距离,其公式是: ,两者重合(相交)的越多,其相似度越高。classify对测试数据进行分类,返回一个包含了预测结果和结果几率的字典。
,两者重合(相交)的越多,其相似度越高。classify对测试数据进行分类,返回一个包含了预测结果和结果几率的字典。
加权kNN
在上述手写识别的例子中,供使用了900个测试样本,其中34个产生了误判,下图是一个误判的例子:

图中是手写数字1,程序判断为7,其原因是代码所用的方法有可能会选择很远的近邻:
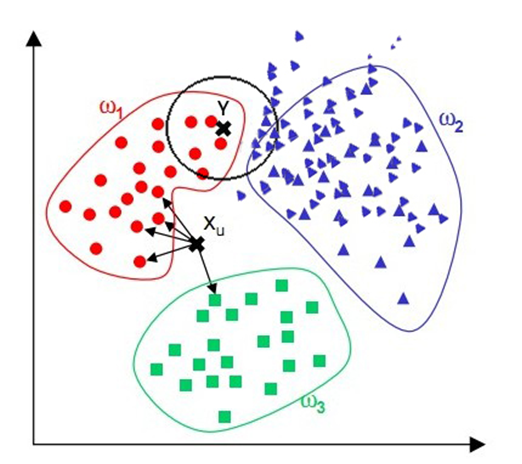
Y点肉眼去看因为在红色区域内很容易判断出多半属于红色一类,但因为蓝色过多,若K值选取稍大则很容易将其归为蓝色一类。为了改进这一点,可以为每个点的距离增加一个权重,这样距离近的点可以得到更大的权重。具体的加权方法将会在下一篇文章中介绍。
出处:微信公众号 "我是8位的"
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”

k最邻近算法——使用kNN进行手写识别的更多相关文章
- 机器学习实战kNN之手写识别
kNN算法算是机器学习入门级绝佳的素材.书上是这样诠释的:“存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都有标签,即我们知道样本集中每一条数据与所属分类的对应关系.输入没有标签的新数据 ...
- python 实现 KNN 分类器——手写识别
1 算法概述 1.1 优劣 优点:进度高,对异常值不敏感,无数据输入假定 缺点:计算复杂度高,空间复杂度高 应用:主要用于文本分类,相似推荐 适用数据范围:数值型和标称型 1.2 算法伪代码 (1)计 ...
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- k最邻近算法——加权kNN
加权kNN 上篇文章中提到为每个点的距离增加一个权重,使得距离近的点可以得到更大的权重,在此描述如何加权. 反函数 该方法最简单的形式是返回距离的倒数,比如距离d,权重1/d.有时候,完全一样或非常接 ...
- kNN算法实例(约会对象喜好预测和手写识别)
import numpy as np import operator import random import os def file2matrix(filePath):#从文本中提取特征矩阵和标签 ...
- 基于kNN的手写字体识别——《机器学习实战》笔记
看完一节<机器学习实战>,算是踏入ML的大门了吧!这里就详细讲一下一个demo:使用kNN算法实现手写字体的简单识别 kNN 先简单介绍一下kNN,就是所谓的K-近邻算法: [作用原理]: ...
- 机器学习实战一:kNN手写识别系统
实战一:kNN手写识别系统 本文将一步步地构造使用K-近邻分类器的手写识别系统.由于能力有限,这里构造的系统只能识别0-9.需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小:32像素*3 ...
- 利用神经网络算法的C#手写数字识别
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 下载Demo - 2.77 MB (原始地址):handwritten_character_recognition.zip 下载源码 - 70. ...
- KNN实现手写数字识别
KNN实现手写数字识别 博客上显示这个没有Jupyter的好看,想看Jupyter Notebook的请戳KNN实现手写数字识别.ipynb 1 - 导入模块 import numpy as np i ...
随机推荐
- UVA-1252 Twenty Questions (状压DP)
题目大意:有n件物品,每件物品有m个特征,可以对特征进行询问,询问的结果是得知某个物体是否含有该特征,要把所有的物品区分出来(n个物品的特征都互不相同)最小需要多少次询问? 题目分析:定义dp(s,a ...
- 怎么使用response.write来做一个javascript的alert弹出窗口
Page.RegisterStartupScript("alert", "<script language=javascript>alert('添加成功'); ...
- Idea破解办法+idea免费生成注册码+jsp属性选择器+注解什么的都报错
Idea破解办法: http://blog.csdn.net/bitcarmanlee/article/details/54951589 idea免费生成注册码: http://idea.iteblo ...
- for each...in,for...in, for...of
一.for each ...in explanation: 该语句在对象属性的所有值上迭代指定的变量.对于每个不同的属性,执行指定的语句. 句法: for each (variable in obj ...
- pymssql
用与连接sql server数据库的python接口 import pymssql 1.配置信息 conf={ "host": "118.190.41.846:9099& ...
- C++基础:什么是命名空间
命名空间是类的逻辑分组,它组织成一个层次结构——逻辑树.这个树的根是System.名字空间是为了防止名字污染在标准C++中引入的.它可以将其中定义的名字隐藏起来,不同的名字空间中可以有相同的名字而互不 ...
- koa 微信小程序 项目
这个微信号入门, 应该能自己模仿做一个微信公众号了 另外 微信小程序开发 和 微信公众号h5嵌入 还是有区别的 h5嵌入在体验上和 微信小程序 差距还是比较大, 因为小程序直接调用了微信的原生组件, ...
- 如何把dos命令窗口里的字符复制下来?
简单一点的操作就是右键点“标记”选中需要复制的内容点左上角的小图标 编辑 复制
- vs2010将写好的软件打包安装包经验
(1) 用VS2010打开已经编写好准备做安装包的软件程序,右击解决方案,添加新建项目. (2) 在“新建项目”对话框中,选择“其他项目类型”,再选择“安装和部署”,然后在模板中选择“安装项目” (3 ...
- ztree树形菜单的增加删除修改和换图标
首先需要注意一点,如果有研究过树形菜单,就会发现实现删除和修改功能特别简单,但是增加却有一点复杂.造成这个现象是ztree树形菜单的历史遗留问题.大概是之前的版本没有增加这个功能,后来的版本加上了这个 ...