『cs231n』视频数据处理
视频信息
和我之前的臆想不同,视频数据不仅仅是一帧一帧的图片本身,还包含个帧之间的联系,也就是还有一个时序的信息维度,包含人的动作判断之类的任务都是要依赖动作的时序信息的
视频数据处理的两种基本方法

- 使用3D卷积网络引入时间维度:由于3D卷积网络每次的输入帧是有长度限定的,所以这种方法更倾向于关注局部(时域)信息的任务
- 使用RNN/LSTM网络系列处理时序信息:由于迭代网络的特性,它更擅长处理全局视频信息

发散:结合两种方法的新思路
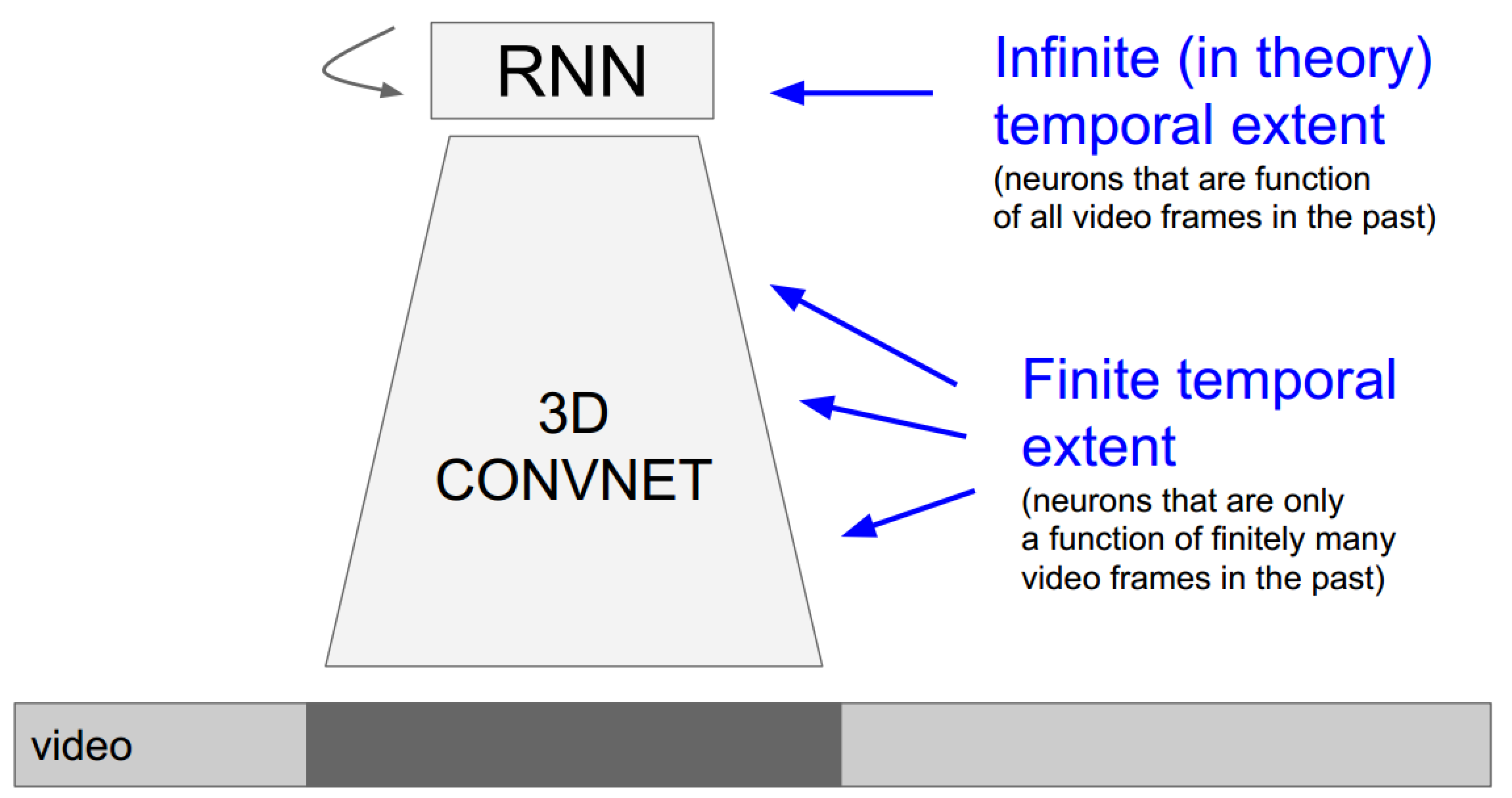
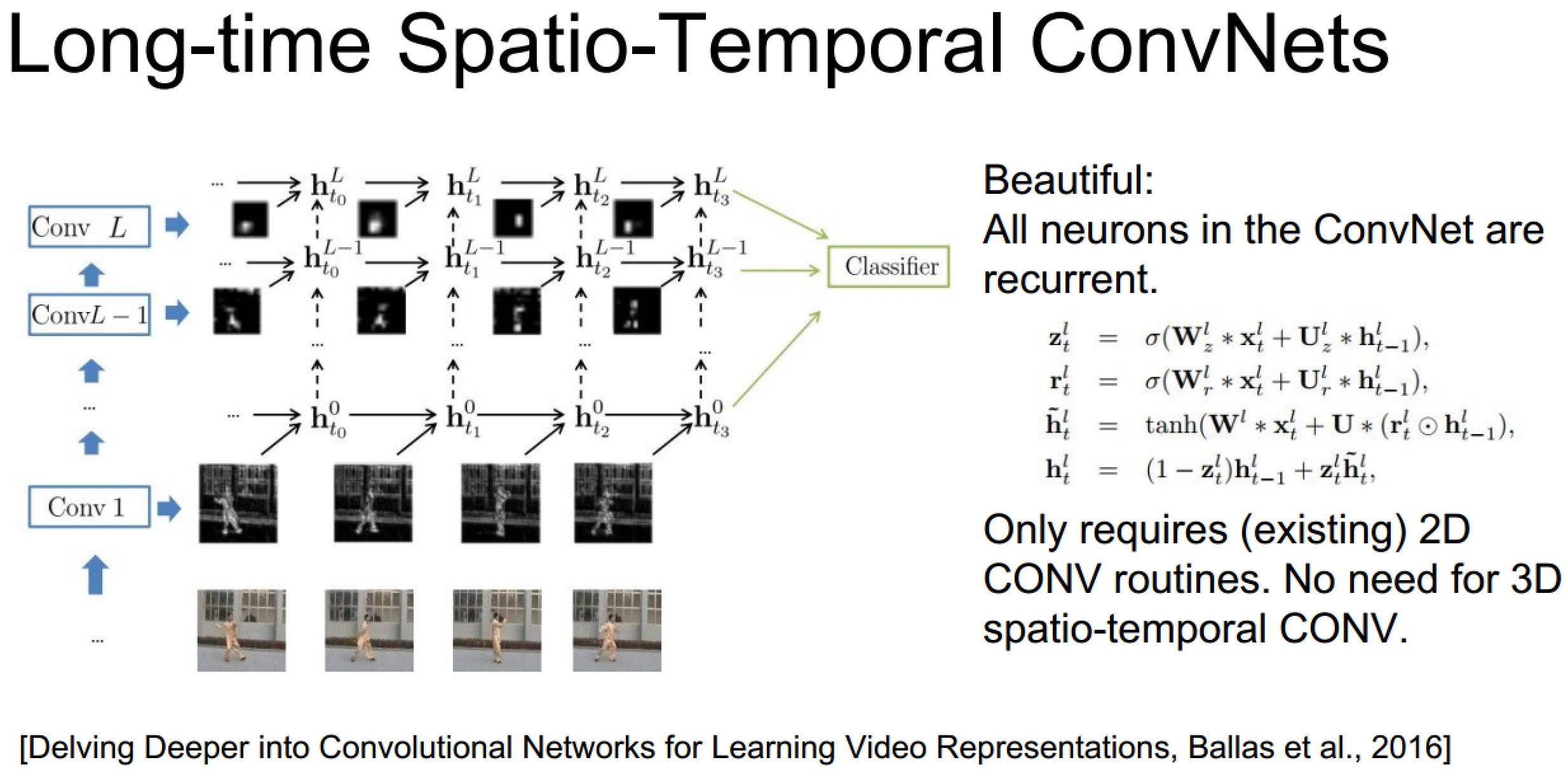
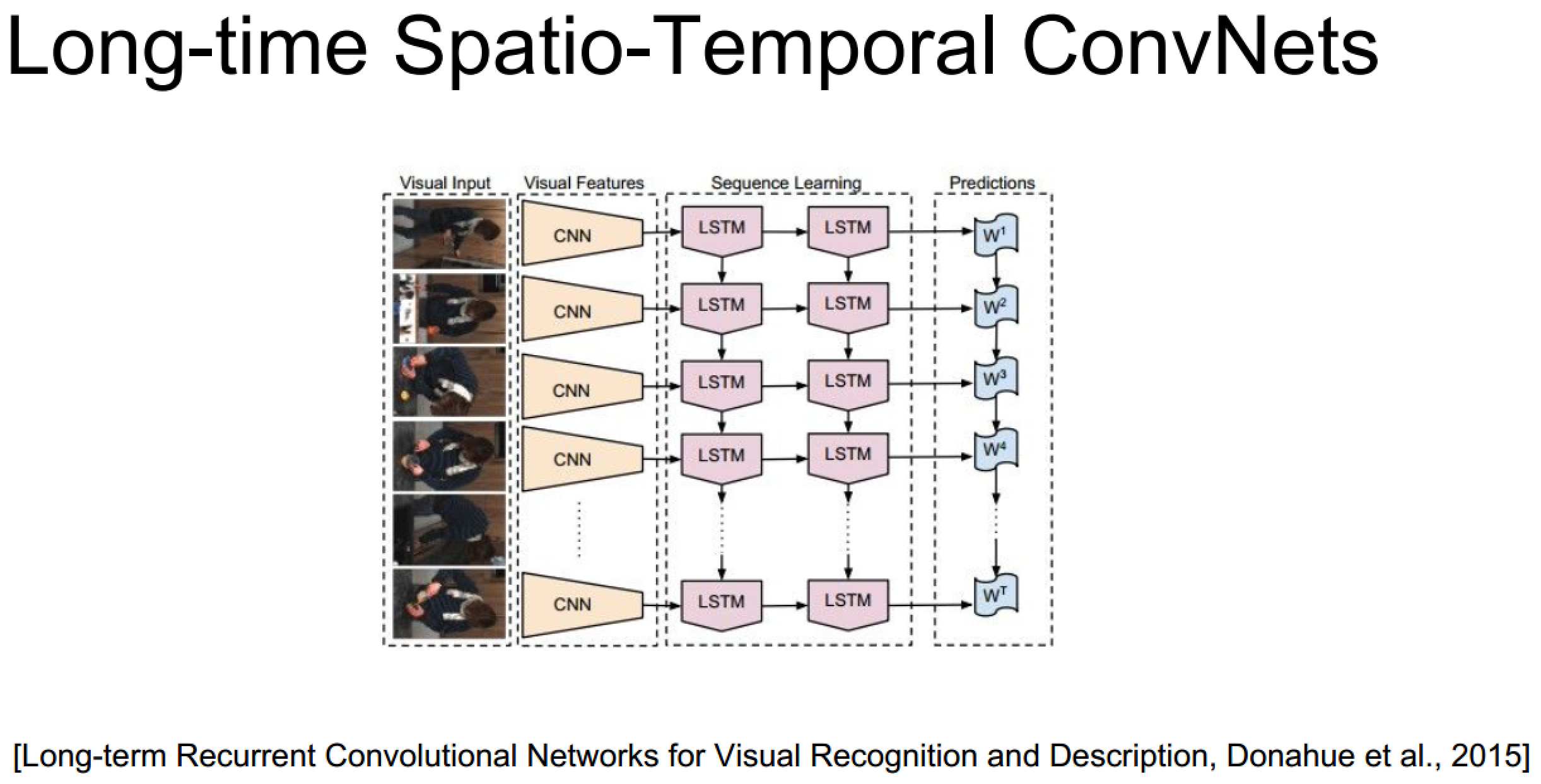
上面的具体实现也未必需要3D卷积,毕竟递归网络自己已经包含了时序信息了:
3D卷积神经网络理解
1、3D卷积
3D卷积是通过堆叠多个连续的帧组成一个立方体,然后在立方体中运用3D卷积核。在这个结构中,卷积层中每一个特征map都会与上一层中多个邻近的连续帧相连,因此捕捉运动信息。例如下图,一个卷积map的某一位置的值是通过卷积上一层的三个连续的帧的同一个位置的局部感受野得到的。
需要注意的是:3D卷积核只能从cube中提取一种类型的特征,因为在整个cube中卷积核的权值都是一样的,也就是共享权值,都是同一个卷积核(图中同一个颜色的连接线表示相同的权值)。我们可以采用多种卷积核,以提取多种特征。
对于CNNs,有一个通用的设计规则就是:在后面的层(离输出层近的)特征map的个数应该增加,这样就可以从低级的特征maps组合产生更多类型的特征。
传统的2D卷积方法是用一个2维的卷积层对特征图进行采样,从而得到下一层的特征图,形式如下:
Convolutional
Networks则是进一步探寻了这种3D时间卷积的实用性,用实验证明,3*3*3的时空卷积核,是最适合于这种新型神经网络结构的卷积核。


tf.nn.conv3d(input, filter, strides, padding, name=None) Computes a 3-D convolution given 5-D input and filter tensors. In signal processing, cross-correlation is a measure of similarity of two waveforms as a function of a time-lag applied to one of them. This is also known as a sliding dot product or sliding inner-product. Our Conv3D implements a form of cross-correlation. Args: input: A Tensor. Must be one of the following types: float32, float64, int64, int32, uint8, uint16, int16, int8, complex64, complex128, qint8, quint8, qint32, half. Shape [batch, in_depth, in_height, in_width, in_channels].
filter: A Tensor. Must have the same type as input. Shape [filter_depth, filter_height, filter_width, in_channels, out_channels]. in_channels must match between input and filter.
strides: A list of ints that has length >= 5. 1-D tensor of length 5. The stride of the sliding window for each dimension of input. Must have strides[0] = strides[4] = 1.
padding: A string from: "SAME", "VALID". The type of padding algorithm to use.
name: A name for the operation (optional).
Returns: A Tensor. Has the same type as input. tf.nn.avg_pool3d(input, ksize, strides, padding, name=None) Performs 3D average pooling on the input. Args: input: A Tensor. Must be one of the following types: float32, float64, int64, int32, uint8, uint16, int16, int8, complex64, complex128, qint8, quint8, qint32, half. Shape [batch, depth, rows, cols, channels] tensor to pool over.
ksize: A list of ints that has length >= 5. 1-D tensor of length 5. The size of the window for each dimension of the input tensor. Must have ksize[0] = ksize[4] = 1.
strides: A list of ints that has length >= 5. 1-D tensor of length 5. The stride of the sliding window for each dimension of input. Must have strides[0] = strides[4] = 1.
padding: A string from: "SAME", "VALID". The type of padding algorithm to use.
name: A name for the operation (optional).
Returns: A Tensor. Has the same type as input. The average pooled output tensor. tf.nn.max_pool3d(input, ksize, strides, padding, name=None) Performs 3D max pooling on the input. Args: input: A Tensor. Must be one of the following types: float32, float64, int64, int32, uint8, uint16, int16, int8, complex64, complex128, qint8, quint8, qint32, half. Shape [batch, depth, rows, cols, channels] tensor to pool over.
ksize: A list of ints that has length >= 5. 1-D tensor of length 5. The size of the window for each dimension of the input tensor. Must have ksize[0] = ksize[4] = 1.
strides: A list of ints that has length >= 5. 1-D tensor of length 5. The stride of the sliding window for each dimension of input. Must have strides[0] = strides[4] = 1.
padding: A string from: "SAME", "VALID". The type of padding algorithm to use.
name: A name for the operation (optional).
Returns: A Tensor. Has the same type as input. The max pooled output tensor.
2、3D卷积神经网络架构
文中的3D CNN架构包含一个硬连线hardwired层、3个卷积层、2个下采样层和一个全连接层。每个3D卷积核卷积的立方体是连续7帧,每帧patch大小是60x40,架构如下:

在第一层,我们应用了一个固定的hardwired的核去对原始的帧进行处理,产生多个通道的信息,然后对多个通道分别处理。最后再将所有通道的信息组合起来得到最终的特征描述。这个实线层实际上是编码了我们对特征的先验知识,这比随机初始化性能要好对于这个做法(原文“相比于随机初始化,通过先验知识对图像的特征提取使得反向传播训练有更好的表现”),梯度表征了图像的边沿的分布,而光流则表征物体运动的趋势,3D卷积通过提取这两种信息来进行行为识别。,每帧提取五个通道的信息分别是:灰度、x和y方向的梯度,x和y方向的光流。其中,前面三个都可以每帧都计算。然后水平和垂直方向的光流场需要两个连续帧才确定。所以是7x3 + (7-1)x2=33个特征maps。
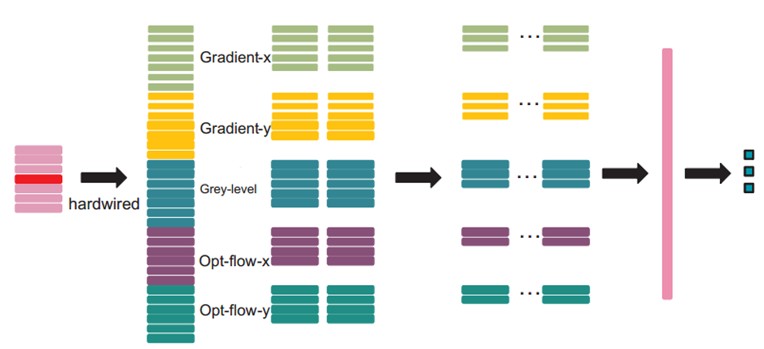
然后我们用一个7x7x3的3D卷积核(7x7在空间,3是时间维)在五个通道的每一个通道分别进行卷积。为了增加特征map的个数(实际上就是提取不同的特征),我们在每一个位置都采用两个不同的卷积核,这样在C2层的两个特征maps组中,每组都包含23个特征maps。23是(7-3+1)x3+(6-3+1)x2前面那个是:七个连续帧,其灰度、x和y方向的梯度这三个通道都分别有7帧,然后水平和垂直方向的光流场都只有6帧。54x34是(60-7+1)x(40-7+1)。
在紧接着的下采样层S3层max pooling,我们在C2层的特征maps中用2x2窗口进行下采样,这样就会得到相同数目但是空间分辨率降低的特征maps。下采样后,就是27x17=(52/2)*(34/2)。
C4是在5个通道中分别采用7x6x3的3D卷积核。为了增加特征maps个数,我们在每个位置都采用3个不同的卷积核,这样就可以得到6组不同的特征maps,每组有13个特征maps。13是((7-3+1)-3+1)x3+((6-3+1)-3+1)x2前面那个是:七个连续帧,其灰度、x和y方向的梯度这三个通道都分别有7帧,然后水平和垂直方向的光流场都只有6帧。21x12是(27-7+1)x(17-6+1)。
S5层用的是3x3的下采样窗口,所以得到7x4。

到这个阶段,时间维上帧的个数已经很小了, (3 for gray, gradient-x, gradient-y, and 2 for optflow-x and optflow-y)。在这一层,我们只在空间维度上面卷积,这时候我们使用的核是7x4,然后输出的特征maps就被减小到1x1的大小。而C6层就包含有128个特征map,每个特征map与S5层中所有78(13x6)个特征maps全连接,这样每个特征map就是1x1,也就是一个值了,而这个就是最终的特征向量了。共128维。

经过多层的卷积和下采样后,每连续7帧的输入图像都被转化为一个128维的特征向量,这个特征向量捕捉了输入帧的运动信息。输出层的节点数与行为的类型数目一致,而且每个节点与C6中这128个节点是全连接的。
在这里,我们采用一个线性分类器来对这128维的特征向量进行分类,实现行为识别。
模型中所有可训练的参数都是随机初始化的,然后通过BP训练。
后面还有一些其他的处理,不过对于理解3D卷积意义不大了,不再赘述,有兴趣的自行查阅相关文章吧(cs231n课件上引用论文图时均给出了出处)
2、双流神经网络(了解发展脉络)
时间轴:时间+空间双流神经网络 -> 16年CVPR的3D卷积+双流网络
Two-Stream Convolutional Networks for Action Recognition in Videos提出的是一个双流的CNN网络,分别捕捉空间和时间信息
3D Convolutional Neural Networks for Human Action Recognition提出了3D卷积方法
Convolutional Two-Stream Network Fusion for Video Action Recognition在原双流论文的基础上做了改进
左边是单纯在某一层融合,右边是融合之后还保留时间网络,在最后再把结果融合一次。论文的实验表明,后者的准确率要稍高。
融合的前提要求是,在这一层,空间与时间网络的特征图长宽相等,且channel数一样(channel在很多论文都有提及,暂时的理解是,channel就代表对应的卷积层中,特征图的个数,因为对上一层输入的特征图,每用一个卷积核,就会产生一个新的特征图,所以需要一个channel来统计总共产生了多少特征图)。具体融合方法很多,详见论文即可。
在把两个网络的特征图融合后,还需要进行另一次卷积操作。假设在时间t,我们得到的特征图是xt,那么对于一大段时间t=1….T,我们要把这段时间内的所有特征图(x1,…,xT)综合起来,进行一次3D时间卷积,最后得到的,就是融合后的特征图输出。注意,此时输出的,仍然是一系列在时间上的特征图。然后再输入到更高层网络,继续训练学习。
『cs231n』视频数据处理的更多相关文章
- 『cs231n』通过代码理解风格迁移
『cs231n』卷积神经网络的可视化应用 文件目录 vgg16.py import os import numpy as np import tensorflow as tf from downloa ...
- 『cs231n』计算机视觉基础
线性分类器损失函数明细: 『cs231n』线性分类器损失函数 最优化Optimiz部分代码: 1.随机搜索 bestloss = float('inf') # 无穷大 for num in range ...
- 『cs231n』通过代码理解gan网络&tensorflow共享变量机制_上
GAN网络架构分析 上图即为GAN的逻辑架构,其中的noise vector就是特征向量z,real images就是输入变量x,标签的标准比较简单(二分类么),real的就是tf.ones,fake ...
- 『cs231n』RNN之理解LSTM网络
概述 LSTM是RNN的增强版,1.RNN能完成的工作LSTM也都能胜任且有更好的效果:2.LSTM解决了RNN梯度消失或爆炸的问题,进而可以具有比RNN更为长时的记忆能力.LSTM网络比较复杂,而恰 ...
- 『cs231n』卷积神经网络的可视化与进一步理解
cs231n的第18课理解起来很吃力,听后又查了一些资料才算是勉强弄懂,所以这里贴一篇博文(根据自己理解有所修改)和原论文的翻译加深加深理解,其中原论文翻译比博文更容易理解,但是太长,而博文是业者而非 ...
- 『cs231n』卷积神经网络工程实践技巧_上
概述 数据增强 思路:在训练的时候引入干扰,在测试的时候避免干扰. 翻转图片增强数据. 随机裁切图片后调整大小用于训练,测试时先图像金字塔制作不同尺寸,然后对每个尺寸在固定位置裁切固定大小进入训练,最 ...
- 『cs231n』作业3问题3选讲_通过代码理解图像梯度
Saliency Maps 这部分想探究一下 CNN 内部的原理,参考论文 Deep Inside Convolutional Networks: Visualising Image Classifi ...
- 『cs231n』绪论
笔记链接 cs231n系列所有图片笔记均拷贝自网络,链接如上,特此声明,后篇不再重复. 计算机视觉历史 总结出视觉两个重要结论:1.基础的视觉神经识别的是简单的边缘&轮廓2.视觉是分层的 数据 ...
- 『cs231n』卷积神经网络工程实践技巧_下
概述 计算加速 方法一: 由于计算机计算矩阵乘法速度非常快,所以这是一个虽然提高内存消耗但是计算速度显著上升的方法,把feature map中的感受野(包含重叠的部分,所以会加大内存消耗)和卷积核全部 ...
随机推荐
- python webdriver api-右键另存下载文件
右键另存下载文件 先编辑SciTE脚本: ;ControlFocus("title","text",controlID) ;表示将焦点切换到标题为title窗体 ...
- 如何安装Apache
第一步:将Apache24解压到C盘根目录下 第二步:进入C:\Apache24\bin目录下 第三步:打开浏览器,网页中输入localhost,返回结果为It works!则说明Apache安装配置 ...
- ES6学习--Object.assign()
ES6提供了Object.assign(),用于合并/复制对象的属性. Object.assign(target, source_1, ..., source_n) 1. 初始化对象属性 构造器正是为 ...
- 特征提取的综合实验(多种角度比较SIFT、SURF、BRISK、ORB算法)
代码:https://files.cnblogs.com/files/jsxyhelu/main.zip 一.基本概念: 特征点提取在“目标识别.图像拼接.运动跟踪.图像检索.自动定位”等研究中起着重 ...
- 20145317彭垚《网络对抗》Exp7 网络欺诈技术防范
20145317彭垚<网络对抗>Exp7 网络欺诈技术防范 基础问题回答 通常在什么场景下容易受到DNS spoof攻击? 在同一局域网下比较容易受到DNS spoof攻击,攻击者可以冒充 ...
- 车载项目问题解(memset)
1memset函数解 1.void *memset(void *s,int c,size_t n) 总的作用:将已开辟内存空间 s 的首 n 个字节的值设为值 c.2.例子 #includevoid ...
- P3901 数列找不同
P3901 数列找不同 题目描述 现有数列 \(A_1,A_2,\cdots,A_N\) ,Q 个询问 \((L_i,R_i)\) , \(A_{Li} ,A_{Li+1},\cdots,A_{Ri} ...
- Codeforces Beta Round #95 (Div. 2) D. Subway dfs+bfs
D. Subway A subway scheme, classic for all Berland cities is represented by a set of n stations conn ...
- hdu 5668 Circle 中国剩余定理
Circle Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) Problem D ...
- [STL][C++]VECTOR
参考:http://blog.csdn.net/hancunai0017/article/details/7032383 vector(向量): C++中的一种数据结构,确切的说是一个类.它相当于一个 ...