自己动手实现java数据结构(五)哈希表
1.哈希表介绍
前面我们已经介绍了许多类型的数据结构。在想要查询容器内特定元素时,有序向量使得我们能使用二分查找法进行精确的查询((O(logN)对数复杂度,很高效)。
可人类总是不知满足,依然在寻求一种更高效的特定元素查询的数据结构,哈希表/散列表(hash table)就应运而生啦。哈希表在特定元素的插入,删除和查询时都能够达到O(1)常数的时间复杂度,十分高效。
1.1 哈希算法
哈希算法的定义:把任意长度的输入通过哈希算法转换映射为固定长度的输出,所得到的输出被称为哈希值(hashCode = hash(input))。哈希映射是一种多对一的关系,即多个不同的输入有可能对应着一个相同的哈希值输出;也意味着,哈希映射是不可逆,无法还原的。
举个例子:我们有一个好朋友叫熊大,大家都叫他老熊。可以理解为是一个hash算法:对于一个人名,我们一般称呼为"老" + 姓氏(单姓) (hash(熊大) = 老熊)。同时,我们还有一个好朋友叫熊二,我们也叫他老熊(hash(熊二) = 老熊)。当熊大和熊二两个好朋友同时和我们聚会时,都称呼他们为老熊就不太合适啦,因为这时出现了hash冲突。老熊这个称呼同时对应了多个人,多个不同的输入对应了相同的哈希值输出。
java在Object这一最高层对象中实现了hashCode方法,并允许子类重写更适应自身,冲突概率更低的hashCode方法。
1.2 哈希表实现的基本思路
哈希表存储的是key-value键值对结构的数据,其基础是一个数组。
由于采用hash算法会出现hash冲突,一个数组下标对应了多个元素。常见的解决hash冲突的方法有:开放地址法、重新哈希法、拉链法等等,我们的哈希表实现采用的是拉链法解决hash冲突。
采用拉链法的哈希表将内部数组的每一个元素视为一个插槽(slot)或者桶(bucket),并将数据存放在键值对节点(EntryNode)中。EntryNode除了存放key和value,还维护着一个next节点的引用。为了解决hash冲突,单个插槽内的多个EntryNode构成一个简单的单向链表,插槽指向链表的头部节点,新的数据将会插入当前链表的尾部。
key值不同但映射的hash值相同的元素在哈希表的同一个插槽中以链表的形式共存。
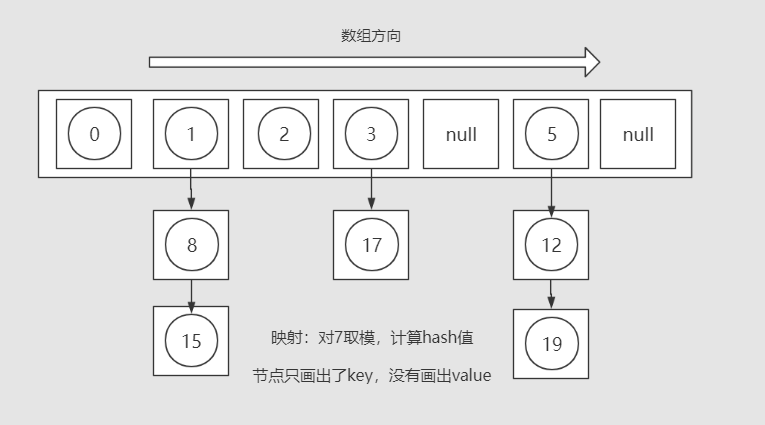
1.3 哈希表的负载因子(loadFactor):
哈希表在查询数据时通过直接计算数据hash值对应的插槽,迅速获取到key值对应的数据,进行非常高效的数据查询。
但依然存在一个问题:虽然设计良好的hash函数可以尽可能的降低hash冲突的概率,但hash冲突还是不可避免的。当发生频繁的哈希冲突时,对应的插槽内可能会存放较多的元素,导致插槽内的链表数据过多。而链表的查询效率是非常低的,在极端情况下,甚至会出现所有元素都映射存放在同一个插槽内,此时的哈希表退化成了一个链表,查询效率急剧降低。
一般的,哈希表存储的数据量一定时,内部数组的大小和数组插槽指向的链表长度成反比。换句话说,总数据量一定,内部数组的容量越大(插槽越多),平均下来桶链表的长度也就越小,查询效率越高。
同等数据量下,哈希表内部数组容量越大,查询效率越高,但同时空间占用也越高,这本质上是一个空间换时间的取舍。
哈希表允许用户在初始化时指定负载因子(loadFactor):负载因子代表着存储的总数据量和内部数组大小的比值。插入新数据时,判断哈希表当前的存储量和内部数组的比值是否超过了负载因子。当比值超过了负载因子时,哈希表认为内部过于拥挤,查询效率太低,会触发一次扩容的rehash操作。rehash会对内部数组扩容,将存储的元素重新进行hash映射,使得哈希表始终保持一个合适的查询效率。
通过指定自定义的负载因子,用户可以控制哈希表在空间和时间上取舍的程度,使哈希表能更有效地适应用户的使用场景。
指定的负载因子越大,哈希表越拥挤(负载高,紧凑),查询效率越低,空间效率越高。
指定的负载因子越小,哈希表越稀疏(负载小,松散),查询效率越高,空间效率越低。
2.哈希表ADT接口
和之前介绍的链表不同,我们在哈希表的ADT接口中暴露出了哈希表内部实现的EntryNode键值对节点。通过暴露出去的public方法,用户在使用哈希表时,可以获得内部的键值对节点,灵活的访问其中的key、value数据(但没有暴露setKey方法,不允许用户自己设置key值)。
public interface Map <K,V>{
/**
* 存入键值对
* @param key key值
* @param value value
* @return 被覆盖的的value值
*/
V put(K key,V value);
/**
* 移除键值对
* @param key key值
* @return 被删除的value的值
*/
V remove(K key);
/**
* 获取key对应的value值
* @param key key值
* @return 对应的value值
*/
V get(K key);
/**
* 是否包含当前key值
* @param key key值
* @return true:包含 false:不包含
*/
boolean containsKey(K key);
/**
* 是否包含当前value值
* @param value value值
* @return true:包含 false:不包含
*/
boolean containsValue(V value);
/**
* 获得当前map存储的键值对数量
* @return 键值对数量
* */
int size();
/**
* 当前map是否为空
* @return true:为空 false:不为空
*/
boolean isEmpty();
/**
* 清空当前map
*/
void clear();
/**
* 获得迭代器
* @return 迭代器对象
*/
Iterator<EntryNode<K,V>> iterator();
/**
* 键值对节点 内部类
* */
class EntryNode<K,V>{
final K key;
V value;
EntryNode<K,V> next;
EntryNode(K key, V value) {
this.key = key;
this.value = value;
}
boolean keyIsEquals(K key){
if(this.key == key){
return true;
}
if(key == null){
//:::如果走到这步,this.key不等于null,不匹配
return false;
}else{
return key.equals(this.key);
}
}
EntryNode<K, V> getNext() {
return next;
}
void setNext(EntryNode<K, V> next) {
this.next = next;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
@Override
public String toString() {
return key + "=" + value;
}
}
}
3.哈希表实现细节
3.1 哈希表基本属性:
public class HashMap<K,V> implements Map<K,V>{
/**
* 内部数组
* */
private EntryNode<K,V>[] elements;
/**
* 当前哈希表的大小
* */
private int size;
/**
* 负载因子
* */
private float loadFactor;
/**
* 默认的哈希表容量
* */
private final static int DEFAULT_CAPACITY = 16;
/**
* 扩容翻倍的基数
* */
private final static int REHASH_BASE = 2;
/**
* 默认的负载因子
* */
private final static float DEFAULT_LOAD_FACTOR = 0.75f;
//========================================构造方法===================================================
/**
* 默认构造方法
* */
@SuppressWarnings("unchecked")
public HashMap() {
this.size = 0;
this.loadFactor = DEFAULT_LOAD_FACTOR;
elements = new EntryNode[DEFAULT_CAPACITY];
}
/**
* 指定初始容量的构造方法
* @param capacity 指定的初始容量
* */
@SuppressWarnings("unchecked")
public HashMap(int capacity) {
this.size = 0;
this.loadFactor = DEFAULT_LOAD_FACTOR;
elements = new EntryNode[capacity];
}
/**
* 指定初始容量和负载因子的构造方法
* @param capacity 指定的初始容量
* @param loadFactor 指定的负载因子
* */
@SuppressWarnings("unchecked")
public HashMap(int capacity,int loadFactor) {
this.size = 0;
this.loadFactor = loadFactor;
elements = new EntryNode[capacity];
}
}
3.2 通过hash值获取对应插槽下标:
获取hash的方法仅和数据自身有关,不受到哈希表存储数据量的影响。
因此getIndex方法的时间复杂度为O(1)。
/**
* 通过key的hashCode获得对应的内部数组下标
* @param key 传入的键值key
* @return 对应的内部数组下标
* */
private int getIndex(K key){
return getIndex(key,this.elements);
} /**
* 通过key的hashCode获得对应的内部数组插槽slot下标
* @param key 传入的键值key
* @param elements 内部数组
* @return 对应的内部数组下标
* */
private int getIndex(K key,EntryNode<K,V>[] elements){
if(key == null){
//::: null 默认存储在第0个桶内
return 0;
}else{
int hashCode = key.hashCode(); //:::通过 高位和低位的异或运算,获得最终的hash映射,减少碰撞的几率
int finalHashCode = hashCode ^ (hashCode >>> 16);
return (elements.length-1) & finalHashCode;
}
}
3.3 链表查询方法:
当出现hash冲突时,会在对应插槽处生成一个单链表。我们需要提供一个方便的单链表查询方法,将增删改查接口的部分公用逻辑抽象出来,简化代码的复杂度。
值得注意的是:在判断Key值是否相等时使用的是EntryNode.keyIsEquals方法,内部最终是通过equals方法进行比较的。也就是说,判断key值是否相等和其它数据结构一样,依然是由equals方法决定的。hashCode方法的作用仅仅是使我们能够更快的定位到所映射的插槽处,加快查询效率。
思考一下,为什么要求在重写equals方法的同时,也应该重写hashCode方法?
/**
* 获得目标节点的前一个节点
* @param currentNode 当前桶链表节点
* @param key 对应的key
* @return 返回当前桶链表中"匹配key的目标节点"的"前一个节点"
* 注意:当桶链表中不存在匹配节点时,返回桶链表的最后一个节点
* */
private EntryNode<K,V> getTargetPreviousEntryNode(EntryNode<K,V> currentNode,K key){
//:::不匹配
EntryNode<K,V> nextNode = currentNode.next;
//:::遍历当前桶后面的所有节点
while(nextNode != null){
//:::如果下一个节点的key匹配
if(nextNode.keyIsEquals(key)){
return currentNode;
}else{
//:::不断指向下一个节点
currentNode = nextNode;
nextNode = nextNode.next;
}
}
//:::到达了桶链表的末尾,返回最后一个节点
return currentNode;
}
3.4 增删改查接口:
哈希表的增删改查接口都是通过hash值直接计算出对应的插槽下标(getIndex方法),然后遍历插槽内的桶链表进行进一步的精确查询(getTargetPreviousEntryNode方法)。在负载因子位于正常范围内时(一般小于1),桶链表的平均长度非常短,可以认为单个桶链表的遍历查询时间复杂度为(O(1))。
因此哈希表的增删改查接口的时间复杂度都是O(1)。
@Override
public V put(K key, V value) {
if(needReHash()){
reHash();
} //:::获得对应的内部数组下标
int index = getIndex(key);
//:::获得对应桶内的第一个节点
EntryNode<K,V> firstEntryNode = this.elements[index]; //:::如果当前桶内不存在任何节点
if(firstEntryNode == null){
//:::创建一个新的节点
this.elements[index] = new EntryNode<>(key,value);
//:::创建了新节点,size加1
this.size++;
return null;
} if(firstEntryNode.keyIsEquals(key)){
//:::当前第一个节点的key与之匹配
V oldValue = firstEntryNode.value;
firstEntryNode.value = value;
return oldValue;
}else{
//:::不匹配 //:::获得匹配的目标节点的前一个节点
EntryNode<K,V> targetPreviousNode = getTargetPreviousEntryNode(firstEntryNode,key);
//:::获得匹配的目标节点
EntryNode<K,V> targetNode = targetPreviousNode.next;
if(targetNode != null){
//:::更新value的值
V oldValue = targetNode.value;
targetNode.value = value;
return oldValue;
}else{
//:::在桶链表的末尾 新增一个节点
targetPreviousNode.next = new EntryNode<>(key,value);
//:::创建了新节点,size加1
this.size++;
return null;
}
}
} @Override
public V remove(K key) {
//:::获得对应的内部数组下标
int index = getIndex(key);
//:::获得对应桶内的第一个节点
EntryNode<K,V> firstEntryNode = this.elements[index]; //:::如果当前桶内不存在任何节点
if(firstEntryNode == null){
return null;
}
if(firstEntryNode.keyIsEquals(key)){
//:::当前第一个节点的key与之匹配 //:::将桶链表的第一个节点指向后一个节点(兼容next为null的情况)
this.elements[index] = firstEntryNode.next;
//:::移除了一个节点 size减一
this.size--;
//:::返回之前的value值
return firstEntryNode.value;
}else{
//:::不匹配 //:::获得匹配的目标节点的前一个节点
EntryNode<K,V> targetPreviousNode = getTargetPreviousEntryNode(firstEntryNode,key);
//:::获得匹配的目标节点
EntryNode<K,V> targetNode = targetPreviousNode.next; if(targetNode != null){
//:::将"前一个节点的next" 指向 "目标节点的next" ---> 相当于将目标节点从桶链表移除
targetPreviousNode.next = targetNode.next;
//:::移除了一个节点 size减一
this.size--;
return targetNode.value;
}else{
//:::如果目标节点为空,说明key并不存在于哈希表中
return null;
}
}
} @Override
public V get(K key) {
//:::获得对应的内部数组下标
int index = getIndex(key);
//:::获得对应桶内的第一个节点
EntryNode<K,V> firstEntryNode = this.elements[index]; //:::如果当前桶内不存在任何节点
if(firstEntryNode == null){
return null;
}
if(firstEntryNode.keyIsEquals(key)){
//:::当前第一个节点的key与之匹配
return firstEntryNode.value;
}else{
//:::获得匹配的目标节点的前一个节点
EntryNode<K,V> targetPreviousNode = getTargetPreviousEntryNode(firstEntryNode,key);
//:::获得匹配的目标节点
EntryNode<K,V> targetNode = targetPreviousNode.next; if(targetNode != null){
return targetNode.value;
}else{
//:::如果目标节点为空,说明key并不存在于哈希表中
return null;
}
}
}
3.5 扩容rehash操作:
前面提到,当插入数据时发现哈希表过于拥挤,超过了负载因子指定的值时,会触发一次rehash扩容操作。
扩容时,我们的内部数组扩容了2倍,所以对于每一个插槽内的元素在rehash时存在两种可能:
1.依然映射到当前下标插槽处
2.映射到高位下标处(当前下标 + 扩容前内部数组长度大小)
注意观察0,4,8三个元素节点,在扩容前(对4取模)都位于下标0插槽;扩容后,数组容量翻倍(对8取模),存在两种情况,0,8两个元素哈希值依然映射在下标0插槽(低位插槽),而元素4则被映射到了下标4插槽(高位插槽)(当前下标(0) + 扩容前内部数组长度大小(4))。
通过遍历每个插槽,将内部元素按顺序进行rehash,得到扩容两倍后的哈希表(数据保留了之前的顺序,即先插入的节点依然位于桶链表靠前的位置)。
和向量扩容一样,虽然rehash操作的时间复杂度为O(n)。但是由于只在插入时偶尔的被触发,总体上看,rehash操作的时间复杂度为O(1)。
哈希表扩容前:
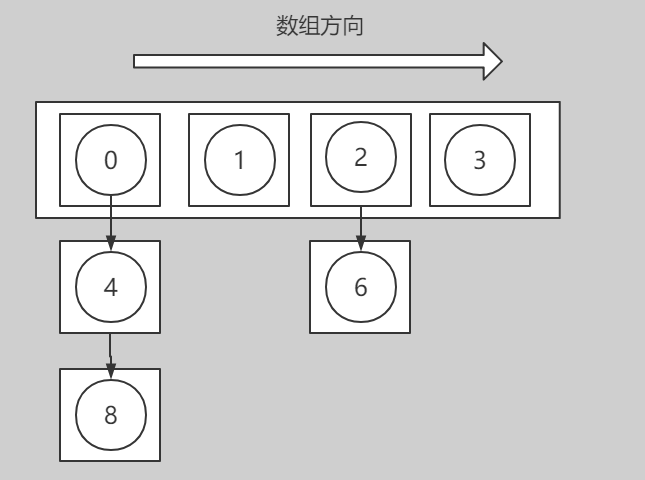
哈希表扩容后:

/**
* 哈希表扩容
* */
@SuppressWarnings("unchecked")
private void reHash(){
//:::扩容两倍
EntryNode<K,V>[] newElements = new EntryNode[this.elements.length * REHASH_BASE]; //:::遍历所有的插槽
for (int i=0; i<this.elements.length; i++) {
//:::为单个插槽内的元素 rehash
reHashSlot(i,newElements);
} //:::内部数组 ---> 扩容之后的新数组
this.elements = newElements;
} /**
* 单个插槽内的数据进行rehash
* */
private void reHashSlot(int index,EntryNode<K, V>[] newElements){
//:::获得当前插槽第一个元素
EntryNode<K, V> currentEntryNode = this.elements[index];
if(currentEntryNode == null){
//:::当前插槽为空,直接返回
return;
} //:::低位桶链表 头部节点、尾部节点
EntryNode<K, V> lowListHead = null;
EntryNode<K, V> lowListTail = null;
//:::高位桶链表 头部节点、尾部节点
EntryNode<K, V> highListHead = null;
EntryNode<K, V> highListTail = null; while(currentEntryNode != null){
//:::获得当前节点 在新数组中映射的插槽下标
int entryNodeIndex = getIndex(currentEntryNode.key,newElements);
//:::是否和当前插槽下标相等
if(entryNodeIndex == index){
//:::和当前插槽下标相等
if(lowListHead == null){
//:::初始化低位链表
lowListHead = currentEntryNode;
lowListTail = currentEntryNode;
}else{
//:::在低位链表尾部拓展新的节点
lowListTail.next = currentEntryNode;
lowListTail = lowListTail.next;
}
}else{
//:::和当前插槽下标不相等
if(highListHead == null){
//:::初始化高位链表
highListHead = currentEntryNode;
highListTail = currentEntryNode;
}else{
//:::在高位链表尾部拓展新的节点
highListTail.next = currentEntryNode;
highListTail = highListTail.next;
}
}
//:::指向当前插槽的下一个节点
currentEntryNode = currentEntryNode.next;
} //:::新扩容elements(index)插槽 存放lowList
newElements[index] = lowListHead;
//:::lowList末尾截断
if(lowListTail != null){
lowListTail.next = null;
} //:::新扩容elements(index + this.elements.length)插槽 存放highList
newElements[index + this.elements.length] = highListHead;
//:::highList末尾截断
if(highListTail != null){
highListTail.next = null;
}
} /**
* 判断是否需要 扩容
* */
private boolean needReHash(){
return ((this.size / this.elements.length) > this.loadFactor);
}
3.6 其它接口实现:
@Override
public boolean containsKey(K key) {
V value = get(key);
return (value != null);
} @Override
public boolean containsValue(V value) {
//:::遍历全部桶链表
for (EntryNode<K, V> element : this.elements) {
//:::获得当前桶链表第一个节点
EntryNode<K, V> entryNode = element; //:::遍历当前桶链表
while (entryNode != null) {
//:::如果value匹配
if (entryNode.value.equals(value)) {
//:::返回true
return true;
} else {
//:::不匹配,指向下一个节点
entryNode = entryNode.next;
}
}
}
//:::所有的节点都遍历了,没有匹配的value
return false;
} @Override
public int size() {
return this.size;
} @Override
public boolean isEmpty() {
return (this.size == 0);
} @Override
public void clear() {
//:::遍历内部数组,将所有桶链表全部清空
for(int i=0; i<this.elements.length; i++){
this.elements[i] = null;
} //:::size设置为0
this.size = 0;
} @Override
public Iterator<EntryNode<K,V>> iterator() {
return new Itr();
} @Override
public String toString() {
Iterator<EntryNode<K,V>> iterator = this.iterator(); //:::空容器
if(!iterator.hasNext()){
return "[]";
} //:::容器起始使用"["
StringBuilder s = new StringBuilder("["); //:::反复迭代
while(true){
//:::获得迭代的当前元素
EntryNode<K,V> data = iterator.next(); //:::判断当前元素是否是最后一个元素
if(!iterator.hasNext()){
//:::是最后一个元素,用"]"收尾
s.append(data).append("]");
//:::返回 拼接完毕的字符串
return s.toString();
}else{
//:::不是最后一个元素
//:::使用", "分割,拼接到后面
s.append(data).append(", ");
}
}
}
4.哈希表迭代器
1. 由于哈希表中数据分布不是连续的,所以在迭代器的初始化过程中必须先跳转到第一个非空数据节点,以避免无效的迭代。
2. 当迭代器的下标到达当前插槽链表的末尾时,迭代器下标需要跳转到靠后插槽的第一个非空数据节点。
/**
* 哈希表 迭代器实现
*/
private class Itr implements Iterator<EntryNode<K,V>> {
/**
* 迭代器 当前节点
* */
private EntryNode<K,V> currentNode; /**
* 迭代器 下一个节点
* */
private EntryNode<K,V> nextNode; /**
* 迭代器 当前内部数组的下标
* */
private int currentIndex; /**
* 默认构造方法
* */
private Itr(){
//:::如果当前哈希表为空,直接返回
if(HashMap.this.isEmpty()){
return;
}
//:::在构造方法中,将迭代器下标移动到第一个有效的节点上 //:::遍历内部数组,找到第一个不为空的数组插槽slot
for(int i=0; i<HashMap.this.elements.length; i++){
//:::设置当前index
this.currentIndex = i; EntryNode<K,V> firstEntryNode = HashMap.this.elements[i];
//:::找到了第一个不为空的插槽slot
if(firstEntryNode != null){
//:::nextNode = 当前插槽第一个节点
this.nextNode = firstEntryNode; //:::构造方法立即结束
return;
}
}
} @Override
public boolean hasNext() {
return (this.nextNode != null);
} @Override
public EntryNode<K,V> next() {
this.currentNode = this.nextNode;
//:::暂存需要返回的节点
EntryNode<K,V> needReturn = this.nextNode; //:::nextNode指向自己的next
this.nextNode = this.nextNode.next;
//:::判断当前nextNode是否为null
if(this.nextNode == null){
//:::说明当前所在的桶链表已经遍历完毕 //:::寻找下一个非空的插槽
for(int i=this.currentIndex+1; i<HashMap.this.elements.length; i++){
//:::设置当前index
this.currentIndex = i; EntryNode<K,V> firstEntryNode = HashMap.this.elements[i];
//:::找到了后续不为空的插槽slot
if(firstEntryNode != null){
//:::nextNode = 当前插槽第一个节点
this.nextNode = firstEntryNode;
//:::跳出循环
break;
}
}
}
return needReturn;
} @Override
public void remove() {
if(this.currentNode == null){
throw new IteratorStateErrorException("迭代器状态异常: 可能在一次迭代中进行了多次remove操作");
} //:::获得需要被移除的节点的key
K currentKey = this.currentNode.key;
//:::将其从哈希表中移除
HashMap.this.remove(currentKey); //:::currentNode设置为null,防止反复调用remove方法
this.currentNode = null;
}
}
5.哈希表性能
5.1 空间效率:
哈希表的空间效率很大程度上取决于负载因子。通常,为了保证哈希表查询的高效性,负载因子都设置的比较小(小于1),因而可能会出现许多空的插槽,浪费空间。
总体而言,哈希表的空间效率低于向量和链表。
5.2 时间效率:
一般的,哈希表增删改查接口的时间复杂度都是O(1)。但是出现较多的hash冲突时,冲突范围内的key的增删改查效率较低,时间效率会有一定的波动。
总体而言,哈希表的时间效率高于向量和链表。
哈希表的时间效率很高,可天下没有免费的午餐,据统计,哈希表的空间利用率通常情况下还不到50%。
哈希表是一个使用空间来换取时间的数据结构,对查询性能有较高要求的场合,可以考虑使用哈希表。
6.哈希表总结
6.1 当前版本缺陷
至此,我们已经实现了一个基础的哈希表,但还存在许多明显缺陷:
1.当hash冲突比较频繁时,查询效率急剧降低。
jdk在1.8版本的哈希表实现(java.util.HashMap)中,对这一场景进行了优化。当内部桶链表的节点个数超过一定数量(默认为8)时,会将插槽中的桶链表转换成一个红黑树(查询效率为O(logN))。
2.不支持多线程
在多线程的环境,并发的访问一个哈希表会导致诸如:扩容时内部节点死循环、丢失插入数据等异常情况。
6.2 查询特定元素的方法
我们目前查询特定元素有几种不同的方法:
1.顺序查找
在无序向量或者链表中,查找一个特定元素是通过从头到尾遍历容器内元素的方式实现的,执行速度正比于数据量的大小,顺序查找的时间复杂度为O(n),效率较低。
2.二分查找
在有序向量以及后面要介绍的二叉搜索树中,由于容器内部的元素是有序的,因此可以通过二分查找比较的方式查询特定的元素,二分查找的时间复杂度为O(logN),效率较高。
3.哈希查找
在哈希表中,通过直接计算出数据hash值对应的插槽(slot)(时间复杂度O(1)),查找出对应的数据,哈希查找的时间复杂度为O(1),效率极高。
特定元素的查找方式和排序算法的关系
1.顺序查找对应冒泡排序、选择排序等,效率较低,时间复杂度(O(n²))。
2.二分查找对应快速排序、归并排序等,效率较高,时间复杂度(O(nLogn))。
3.哈希查找对应基排序,效率极高,时间复杂度(O(n))。
在大牛刘未鹏的博客中有更为详细的说明,http://mindhacks.cn/2008/06/13/why-is-quicksort-so-quick。
6.3 完整代码
哈希表ADT接口:
public interface Map <K,V>{
/**
* 存入键值对
* @param key key值
* @param value value
* @return 被覆盖的的value值
*/
V put(K key,V value);
/**
* 移除键值对
* @param key key值
* @return 被删除的value的值
*/
V remove(K key);
/**
* 获取key对应的value值
* @param key key值
* @return 对应的value值
*/
V get(K key);
/**
* 是否包含当前key值
* @param key key值
* @return true:包含 false:不包含
*/
boolean containsKey(K key);
/**
* 是否包含当前value值
* @param value value值
* @return true:包含 false:不包含
*/
boolean containsValue(V value);
/**
* 获得当前map存储的键值对数量
* @return 键值对数量
* */
int size();
/**
* 当前map是否为空
* @return true:为空 false:不为空
*/
boolean isEmpty();
/**
* 清空当前map
*/
void clear();
/**
* 获得迭代器
* @return 迭代器对象
*/
Iterator<EntryNode<K,V>> iterator();
/**
* 键值对节点 内部类
* */
class EntryNode<K,V>{
final K key;
V value;
EntryNode<K,V> next;
EntryNode(K key, V value) {
this.key = key;
this.value = value;
}
boolean keyIsEquals(K key){
if(this.key == key){
return true;
}
if(key == null){
//:::如果走到这步,this.key不等于null,不匹配
return false;
}else{
return key.equals(this.key);
}
}
EntryNode<K, V> getNext() {
return next;
}
void setNext(EntryNode<K, V> next) {
this.next = next;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
@Override
public String toString() {
return key + "=" + value;
}
}
}
哈希表实现:
public class HashMap<K,V> implements Map<K,V>{
//===========================================成员属性================================================
/**
* 内部数组
* */
private EntryNode<K,V>[] elements;
/**
* 当前哈希表的大小
* */
private int size;
/**
* 负载因子
* */
private float loadFactor;
/**
* 默认的哈希表容量
* */
private final static int DEFAULT_CAPACITY = 16;
/**
* 扩容翻倍的基数 两倍
* */
private final static int REHASH_BASE = 2;
/**
* 默认的负载因子
* */
private final static float DEFAULT_LOAD_FACTOR = 0.75f;
//========================================构造方法===================================================
/**
* 默认构造方法
* */
@SuppressWarnings("unchecked")
public HashMap() {
this.size = 0;
this.loadFactor = DEFAULT_LOAD_FACTOR;
elements = new EntryNode[DEFAULT_CAPACITY];
}
/**
* 指定初始容量的构造方法
* @param capacity 指定的初始容量
* */
@SuppressWarnings("unchecked")
public HashMap(int capacity) {
this.size = 0;
this.loadFactor = DEFAULT_LOAD_FACTOR;
elements = new EntryNode[capacity];
}
/**
* 指定初始容量和负载因子的构造方法
* @param capacity 指定的初始容量
* @param loadFactor 指定的负载因子
* */
@SuppressWarnings("unchecked")
public HashMap(int capacity,int loadFactor) {
this.size = 0;
this.loadFactor = loadFactor;
elements = new EntryNode[capacity];
}
//==========================================内部辅助方法=============================================
/**
* 通过key的hashCode获得对应的内部数组下标
* @param key 传入的键值key
* @return 对应的内部数组下标
* */
private int getIndex(K key){
return getIndex(key,this.elements);
}
/**
* 通过key的hashCode获得对应的内部数组插槽slot下标
* @param key 传入的键值key
* @param elements 内部数组
* @return 对应的内部数组下标
* */
private int getIndex(K key,EntryNode<K,V>[] elements){
if(key == null){
//::: null 默认存储在第0个桶内
return 0;
}else{
int hashCode = key.hashCode();
//:::通过 高位和低位的异或运算,获得最终的hash映射,减少碰撞的几率
int finalHashCode = hashCode ^ (hashCode >>> 16);
return (elements.length-1) & finalHashCode;
}
}
/**
* 获得目标节点的前一个节点
* @param currentNode 当前桶链表节点
* @param key 对应的key
* @return 返回当前桶链表中"匹配key的目标节点"的"前一个节点"
* 注意:当桶链表中不存在匹配节点时,返回桶链表的最后一个节点
* */
private EntryNode<K,V> getTargetPreviousEntryNode(EntryNode<K,V> currentNode,K key){
//:::不匹配
EntryNode<K,V> nextNode = currentNode.next;
//:::遍历当前桶后面的所有节点
while(nextNode != null){
//:::如果下一个节点的key匹配
if(nextNode.keyIsEquals(key)){
return currentNode;
}else{
//:::不断指向下一个节点
currentNode = nextNode;
nextNode = nextNode.next;
}
}
//:::到达了桶链表的末尾,返回最后一个节点
return currentNode;
}
/**
* 哈希表扩容
* */
@SuppressWarnings("unchecked")
private void reHash(){
//:::扩容两倍
EntryNode<K,V>[] newElements = new EntryNode[this.elements.length * REHASH_BASE];
//:::遍历所有的插槽
for (int i=0; i<this.elements.length; i++) {
//:::为单个插槽内的元素 rehash
reHashSlot(i,newElements);
}
//:::内部数组 ---> 扩容之后的新数组
this.elements = newElements;
}
/**
* 单个插槽内的数据进行rehash
* */
private void reHashSlot(int index,EntryNode<K, V>[] newElements){
//:::获得当前插槽第一个元素
EntryNode<K, V> currentEntryNode = this.elements[index];
if(currentEntryNode == null){
//:::当前插槽为空,直接返回
return;
}
//:::低位桶链表 头部节点、尾部节点
EntryNode<K, V> lowListHead = null;
EntryNode<K, V> lowListTail = null;
//:::高位桶链表 头部节点、尾部节点
EntryNode<K, V> highListHead = null;
EntryNode<K, V> highListTail = null;
while(currentEntryNode != null){
//:::获得当前节点 在新数组中映射的插槽下标
int entryNodeIndex = getIndex(currentEntryNode.key,newElements);
//:::是否和当前插槽下标相等
if(entryNodeIndex == index){
//:::和当前插槽下标相等
if(lowListHead == null){
//:::初始化低位链表
lowListHead = currentEntryNode;
lowListTail = currentEntryNode;
}else{
//:::在低位链表尾部拓展新的节点
lowListTail.next = currentEntryNode;
lowListTail = lowListTail.next;
}
}else{
//:::和当前插槽下标不相等
if(highListHead == null){
//:::初始化高位链表
highListHead = currentEntryNode;
highListTail = currentEntryNode;
}else{
//:::在高位链表尾部拓展新的节点
highListTail.next = currentEntryNode;
highListTail = highListTail.next;
}
}
//:::指向当前插槽的下一个节点
currentEntryNode = currentEntryNode.next;
}
//:::新扩容elements(index)插槽 存放lowList
newElements[index] = lowListHead;
//:::lowList末尾截断
if(lowListTail != null){
lowListTail.next = null;
}
//:::新扩容elements(index + this.elements.length)插槽 存放highList
newElements[index + this.elements.length] = highListHead;
//:::highList末尾截断
if(highListTail != null){
highListTail.next = null;
}
}
/**
* 判断是否需要 扩容
* */
private boolean needReHash(){
return ((this.size / this.elements.length) > this.loadFactor);
}
//============================================外部接口================================================
@Override
public V put(K key, V value) {
if(needReHash()){
reHash();
}
//:::获得对应的内部数组下标
int index = getIndex(key);
//:::获得对应桶内的第一个节点
EntryNode<K,V> firstEntryNode = this.elements[index];
//:::如果当前桶内不存在任何节点
if(firstEntryNode == null){
//:::创建一个新的节点
this.elements[index] = new EntryNode<>(key,value);
//:::创建了新节点,size加1
this.size++;
return null;
}
if(firstEntryNode.keyIsEquals(key)){
//:::当前第一个节点的key与之匹配
V oldValue = firstEntryNode.value;
firstEntryNode.value = value;
return oldValue;
}else{
//:::不匹配
//:::获得匹配的目标节点的前一个节点
EntryNode<K,V> targetPreviousNode = getTargetPreviousEntryNode(firstEntryNode,key);
//:::获得匹配的目标节点
EntryNode<K,V> targetNode = targetPreviousNode.next;
if(targetNode != null){
//:::更新value的值
V oldValue = targetNode.value;
targetNode.value = value;
return oldValue;
}else{
//:::在桶链表的末尾 新增一个节点
targetPreviousNode.next = new EntryNode<>(key,value);
//:::创建了新节点,size加1
this.size++;
return null;
}
}
}
@Override
public V remove(K key) {
//:::获得对应的内部数组下标
int index = getIndex(key);
//:::获得对应桶内的第一个节点
EntryNode<K,V> firstEntryNode = this.elements[index];
//:::如果当前桶内不存在任何节点
if(firstEntryNode == null){
return null;
}
if(firstEntryNode.keyIsEquals(key)){
//:::当前第一个节点的key与之匹配
//:::将桶链表的第一个节点指向后一个节点(兼容next为null的情况)
this.elements[index] = firstEntryNode.next;
//:::移除了一个节点 size减一
this.size--;
//:::返回之前的value值
return firstEntryNode.value;
}else{
//:::不匹配
//:::获得匹配的目标节点的前一个节点
EntryNode<K,V> targetPreviousNode = getTargetPreviousEntryNode(firstEntryNode,key);
//:::获得匹配的目标节点
EntryNode<K,V> targetNode = targetPreviousNode.next;
if(targetNode != null){
//:::将"前一个节点的next" 指向 "目标节点的next" ---> 相当于将目标节点从桶链表移除
targetPreviousNode.next = targetNode.next;
//:::移除了一个节点 size减一
this.size--;
return targetNode.value;
}else{
//:::如果目标节点为空,说明key并不存在于哈希表中
return null;
}
}
}
@Override
public V get(K key) {
//:::获得对应的内部数组下标
int index = getIndex(key);
//:::获得对应桶内的第一个节点
EntryNode<K,V> firstEntryNode = this.elements[index];
//:::如果当前桶内不存在任何节点
if(firstEntryNode == null){
return null;
}
if(firstEntryNode.keyIsEquals(key)){
//:::当前第一个节点的key与之匹配
return firstEntryNode.value;
}else{
//:::获得匹配的目标节点的前一个节点
EntryNode<K,V> targetPreviousNode = getTargetPreviousEntryNode(firstEntryNode,key);
//:::获得匹配的目标节点
EntryNode<K,V> targetNode = targetPreviousNode.next;
if(targetNode != null){
return targetNode.value;
}else{
//:::如果目标节点为空,说明key并不存在于哈希表中
return null;
}
}
}
@Override
public boolean containsKey(K key) {
V value = get(key);
return (value != null);
}
@Override
public boolean containsValue(V value) {
//:::遍历全部桶链表
for (EntryNode<K, V> element : this.elements) {
//:::获得当前桶链表第一个节点
EntryNode<K, V> entryNode = element;
//:::遍历当前桶链表
while (entryNode != null) {
//:::如果value匹配
if (entryNode.value.equals(value)) {
//:::返回true
return true;
} else {
//:::不匹配,指向下一个节点
entryNode = entryNode.next;
}
}
}
//:::所有的节点都遍历了,没有匹配的value
return false;
}
@Override
public int size() {
return this.size;
}
@Override
public boolean isEmpty() {
return (this.size == 0);
}
@Override
public void clear() {
//:::遍历内部数组,将所有桶链表全部清空
for(int i=0; i<this.elements.length; i++){
this.elements[i] = null;
}
//:::size设置为0
this.size = 0;
}
@Override
public Iterator<EntryNode<K,V>> iterator() {
return new Itr();
}
@Override
public String toString() {
Iterator<EntryNode<K,V>> iterator = this.iterator();
//:::空容器
if(!iterator.hasNext()){
return "[]";
}
//:::容器起始使用"["
StringBuilder s = new StringBuilder("[");
//:::反复迭代
while(true){
//:::获得迭代的当前元素
EntryNode<K,V> data = iterator.next();
//:::判断当前元素是否是最后一个元素
if(!iterator.hasNext()){
//:::是最后一个元素,用"]"收尾
s.append(data).append("]");
//:::返回 拼接完毕的字符串
return s.toString();
}else{
//:::不是最后一个元素
//:::使用", "分割,拼接到后面
s.append(data).append(", ");
}
}
}
/**
* 哈希表 迭代器实现
*/
private class Itr implements Iterator<EntryNode<K,V>> {
/**
* 迭代器 当前节点
* */
private EntryNode<K,V> currentNode;
/**
* 迭代器 下一个节点
* */
private EntryNode<K,V> nextNode;
/**
* 迭代器 当前内部数组的下标
* */
private int currentIndex;
/**
* 默认构造方法
* */
private Itr(){
//:::如果当前哈希表为空,直接返回
if(HashMap.this.isEmpty()){
return;
}
//:::在构造方法中,将迭代器下标移动到第一个有效的节点上
//:::遍历内部数组,找到第一个不为空的数组插槽slot
for(int i=0; i<HashMap.this.elements.length; i++){
//:::设置当前index
this.currentIndex = i;
EntryNode<K,V> firstEntryNode = HashMap.this.elements[i];
//:::找到了第一个不为空的插槽slot
if(firstEntryNode != null){
//:::nextNode = 当前插槽第一个节点
this.nextNode = firstEntryNode;
//:::构造方法立即结束
return;
}
}
}
@Override
public boolean hasNext() {
return (this.nextNode != null);
}
@Override
public EntryNode<K,V> next() {
this.currentNode = this.nextNode;
//:::暂存需要返回的节点
EntryNode<K,V> needReturn = this.nextNode;
//:::nextNode指向自己的next
this.nextNode = this.nextNode.next;
//:::判断当前nextNode是否为null
if(this.nextNode == null){
//:::说明当前所在的桶链表已经遍历完毕
//:::寻找下一个非空的插槽
for(int i=this.currentIndex+1; i<HashMap.this.elements.length; i++){
//:::设置当前index
this.currentIndex = i;
EntryNode<K,V> firstEntryNode = HashMap.this.elements[i];
//:::找到了后续不为空的插槽slot
if(firstEntryNode != null){
//:::nextNode = 当前插槽第一个节点
this.nextNode = firstEntryNode;
//:::跳出循环
break;
}
}
}
return needReturn;
}
@Override
public void remove() {
if(this.currentNode == null){
throw new IteratorStateErrorException("迭代器状态异常: 可能在一次迭代中进行了多次remove操作");
}
//:::获得需要被移除的节点的key
K currentKey = this.currentNode.key;
//:::将其从哈希表中移除
HashMap.this.remove(currentKey);
//:::currentNode设置为null,防止反复调用remove方法
this.currentNode = null;
}
}
}
哈希表简单的测试代码:
public class MapTest {
public static void main(String[] args){
testJDKHashMap();
System.out.println("=================================================");
testMyHashMap();
}
private static void testJDKHashMap(){
java.util.Map<Integer,String> map1 = new java.util.HashMap<>(1,2);
System.out.println(map1.put(1,"aaa"));
System.out.println(map1.put(2,"bbb"));
System.out.println(map1.put(3,"ccc"));
System.out.println(map1.put(1,"aaa"));
System.out.println(map1.put(2,"bbb"));
System.out.println(map1.put(3,"ccc"));
System.out.println(map1.put(1,"111"));
System.out.println(map1.put(3,"aaa"));
System.out.println(map1.put(4,"ddd"));
System.out.println(map1.put(5,"eee"));
System.out.println(map1.put(6,"fff"));
System.out.println(map1.put(8,"ggg"));
System.out.println(map1.put(11,"bbb"));
System.out.println(map1.put(22,"ccc"));
System.out.println(map1.put(33,"111"));
System.out.println(map1.put(9,"111"));
System.out.println(map1.put(10,"111"));
System.out.println(map1.put(12,"111"));
System.out.println(map1.put(13,"111"));
System.out.println(map1.put(14,"111"));
System.out.println(map1.toString());
System.out.println(map1.containsKey(1));
System.out.println(map1.containsKey(11));
System.out.println(map1.containsValue("bbb"));
System.out.println(map1.containsValue("aaa"));
System.out.println(map1.size());
System.out.println(map1.get(1));
System.out.println(map1.get(2));
System.out.println(map1.get(3));
System.out.println(map1.remove(1));
System.out.println(map1.remove(2));
System.out.println(map1.size());
}
private static void testMyHashMap(){
com.xiongyx.datastructures.map.Map<Integer,String> map2 = new com.xiongyx.datastructures.map.HashMap<>(1,2);
System.out.println(map2.put(1,"aaa"));
System.out.println(map2.put(2,"bbb"));
System.out.println(map2.put(3,"ccc"));
System.out.println(map2.put(1,"aaa"));
System.out.println(map2.put(2,"bbb"));
System.out.println(map2.put(3,"ccc"));
System.out.println(map2.put(1,"111"));
System.out.println(map2.put(3,"aaa"));
System.out.println(map2.put(4,"ddd"));
System.out.println(map2.put(5,"eee"));
System.out.println(map2.put(6,"fff"));
System.out.println(map2.put(8,"ggg"));
System.out.println(map2.put(11,"bbb"));
System.out.println(map2.put(22,"ccc"));
System.out.println(map2.put(33,"111"));
System.out.println(map2.put(9,"111"));
System.out.println(map2.put(10,"111"));
System.out.println(map2.put(12,"111"));
System.out.println(map2.put(13,"111"));
System.out.println(map2.put(14,"111"));
System.out.println(map2.toString());
System.out.println(map2.containsKey(1));
System.out.println(map2.containsKey(11));
System.out.println(map2.containsValue("bbb"));
System.out.println(map2.containsValue("aaa"));
System.out.println(map2.size());
System.out.println(map2.get(1));
System.out.println(map2.get(2));
System.out.println(map2.get(3));
System.out.println(map2.remove(1));
System.out.println(map2.remove(2));
System.out.println(map2.size());
}
}
我们的哈希表实现是demo级别的,功能简单,也比较好理解,希望这能够成为大家理解更加复杂的产品级哈希表实现的一个跳板。在理解了demo级别代码的基础之上,去阅读更加复杂的产品级实现代码,更好的理解哈希表,更好的理解自己所使用的数据结构,写出更高效,易维护的程序。
本系列博客的代码在我的 github上:https://github.com/1399852153/DataStructures,存在许多不足之处,请多多指教。
自己动手实现java数据结构(五)哈希表的更多相关文章
- JAVA数据结构之哈希表
Hash表简介: Hash表是基于数组的,优点是提供快速的插入和查找的操作,编程实现相对容易,缺点是一旦创建就不好扩展,当hash表被基本填满的时候,性能下降非常严重(发生聚集引起的性能的下降),而且 ...
- 自己动手实现java数据结构(一) 向量
1.向量介绍 计算机程序主要运行在内存中,而内存在逻辑上可以被看做是连续的地址.为了充分利用这一特性,在主流的编程语言中都存在一种底层的被称为数组(Array)的数据结构与之对应.在使用数组时需要事先 ...
- 数据结构 5 哈希表/HashMap 、自动扩容、多线程会出现的问题
上一节,我们已经介绍了最重要的B树以及B+树,使用的情况以及区别的内容.当然,本节课,我们将学习重要的一个数据结构.哈希表 哈希表 哈希也常被称作是散列表,为什么要这么称呼呢,散列.散列.其元素分布较 ...
- 自己动手实现java数据结构(六)二叉搜索树
1.二叉搜索树介绍 前面我们已经介绍过了向量和链表.有序向量可以以二分查找的方式高效的查找特定元素,而缺点是插入删除的效率较低(需要整体移动内部元素):链表的优点在于插入,删除元素时效率较高,但由于不 ...
- 自己动手实现java数据结构(九) 跳表
1. 跳表介绍 在之前关于数据结构的博客中已经介绍过两种最基础的数据结构:基于连续内存空间的向量(线性表)和基于链式节点结构的链表. 有序的向量可以通过二分查找以logn对数复杂度完成随机查找,但由于 ...
- 数据结构是哈希表(hashTable)
哈希表也称为散列表,是根据关键字值(key value)而直接进行访问的数据结构.也就是说,它通过把关键字值映射到一个位置来访问记录,以加快查找的速度.这个映射函数称为哈希函数(也称为散列函数),映射 ...
- python数据结构之哈希表
哈希表(Hash table) 众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry.这些个键值对(Entry)分散存储在一个数组当中,这个数组就是Has ...
- 算法与数据结构基础 - 哈希表(Hash Table)
Hash Table基础 哈希表(Hash Table)是常用的数据结构,其运用哈希函数(hash function)实现映射,内部使用开放定址.拉链法等方式解决哈希冲突,使得读写时间复杂度平均为O( ...
- 数据结构HashMap哈希表原理分析
先看看定义:“散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构.也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度. 哈希 ...
随机推荐
- boost的下载和安装(windows版)
1 简介 boost是一个准C++标准库,相当于STL的延续和扩充,它的设计理念和STL比较接近,都是利用泛型让复用达到最大化. boost主要包含以下几个大类: 字符串及文本处理.容器.迭代器(it ...
- 开始Dev之路
从今天开始,开启Dev的发展之路.
- frp使用笔记
参考文档: https://github.com/fatedier/frp/blob/master/README_zh.md#%E9%80%9A%E8%BF%87-frpc-%E6%89%80%E5% ...
- js使用锚点回到顶部
使用锚点链接是一种简单的返回顶部的功能实现.该实现主要在页面顶部放置一个指定名称的锚点链接,然后在页面下方放置一个返回到该锚点的链接,用户点击该链接即可返回到该锚点所在的顶部位置 <body s ...
- mybatis的resultMap与resultType的区别
一.概述MyBatis中在查询进行select映射的时候,返回类型可以用resultType,也可以用resultMap,resultType是直接表示返回类型的,而resultMap则是对外部Res ...
- SAS对数据变量的处理
SAS对数据变量的处理 在使用DATA步基于已经存在的数据集生成新数据集时,可以指定在新数据集中不需要包含的变量而仅读取其他变量,或者指定仅需要在 新数据集中包含的变量.该功能可以通过DATA步中的S ...
- React Native桥接器初探
本文假设你已经有一定的React Native基础,并且想要了解React Native的JS和原生代码之间是如何交互的. React Native的工作线程 shadow queue:布局在这个线程 ...
- CUDA并行编程思维过程
CUDA并行编程思维过程 1)确定应用程序中需要且可以并行化的部分 2)将并行化代码中需要用到的数据分离出来,具体方法是用API函数在并行技术设备上分配内存空间 3)用API函数将数据传输到并行计算设 ...
- 隐藏字符 BOM
如果您在修改任何PHP文件後发生: * 不能登入或者不能登出: * 页顶出现一条空白: * 页顶出现错误警告: * 其它不正常的情况. 则多半是编辑器的问题. 本程序采用UTF-8编码.现在几乎所 ...
- Latex一次添加两个图(并列),半栏
\begin{figure}[t] \centering \includegraphics[width=0.9\columnwidth, clip=true, trim=0 0 0 32]{figur ...