斯坦福大学公开课机器学习:梯度下降运算的特征缩放(gradient descent in practice 1:feature scaling)
以房屋价格为例,假设有两个特征向量:X1:房子大小(1-2000 feets), X2:卧室数量(1-5)
关于这两个特征向量的代价函数如下图所示:
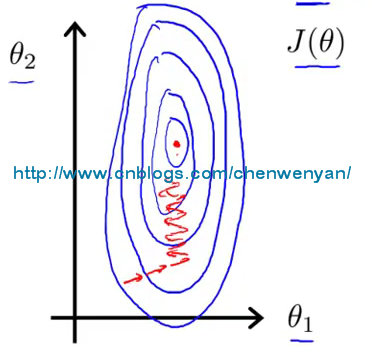
从上图可以看出,代价函数是一个又瘦又高的椭圆形轮廓图,如果用这个代价函数来运行梯度下降的话,得到最终的梯度值,可能需要花费很长的时间,甚至可能来回震动,最终才能收敛到全局最小值。为了减少梯度下来花费的时间,最好的办法就是对特征向量进行缩放(feature scaling)。
特征向量缩放(feature scaling):具体来说,还是以上面的房屋价格为例,假设有两个特征向量:X1:房子大小(1-2000 feets), X2:卧室数量(1-5),现在将它们转化为如下公式:

即将房子大小除以2000,卧室的数量除以5.
这个时候代价函数就会变得比较圆,计算最终梯度值的速度也会随之变快,如下图所示:

一般情况下,我们进行特征向量缩放的目的是将特征的取值约束到[-1 ,1]之间,而特征X0恒等于1,[-1,1]这个范围并不是很严格的,事实上,假如存在特征向量X1,其缩放以后为[0,3]或者[-2,0.5]之间,这也是允许的。但是如果是在[-100,100]或者[-0.0001,0.0001]之间,则是不允许的,跟[-1,1]差距太大了。
将特征向量除以最大值是特征缩放的其中一种方式,还有另一种方式是均值归一化(mean normalization),其思想如下:
假设将特征向量Xi用Xi-μi代替,使其均值接近0,假设房子平均大小为1000 feets,平均卧室数量为2,则特征向量可以转化为如下公式:
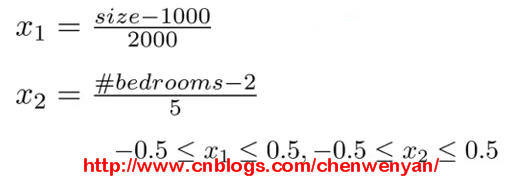
一般情况下,可以用X1来代替原来的特征X1,具体公式如下:
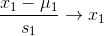
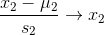
x1,x2指的是原来的特征向量,u1,u2指的是在训练集中,特征向量x1,x2分别的平均值,s1,s2指的是该特征值的范围(即最大值减去最小值),也可以把s1,s2改为变量的标准差
斯坦福大学公开课机器学习:梯度下降运算的特征缩放(gradient descent in practice 1:feature scaling)的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | diagnosing bias vs. variance(机器学习:诊断偏差和方差问题)
当我们运行一个学习算法时,如果这个算法的表现不理想,那么有两种原因导致:要么偏差比较大.要么方差比较大.换句话说,要么是欠拟合.要么是过拟合.那么这两种情况,哪个和偏差有关.哪个和方差有关,或者是不是 ...
- 第19月第8天 斯坦福大学公开课机器学习 (吴恩达 Andrew Ng)
1.斯坦福大学公开课机器学习 (吴恩达 Andrew Ng) http://open.163.com/special/opencourse/machinelearning.html 笔记 http:/ ...
- 斯坦福大学公开课机器学习:梯度下降运算的学习率a(gradient descent in practice 2:learning rate alpha)
本章节主要讲怎么确定梯度下降的工作是正确的,第二是怎么选择学习率α,如下图所示: 上图显示的是梯度下降算法迭代过程中的代价函数j(θ)的值,横轴是迭代步数,纵轴是j(θ)的值 如果梯度算法正常工作,那 ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
- 斯坦福大学公开课机器学习:machine learning system design | error metrics for skewed classes(偏斜类问题的定义以及针对偏斜类问题的评估度量值:查准率(precision)和召回率(recall))
上篇文章提到了误差分析以及设定误差度量值的重要性.那就是设定某个实数来评估学习算法并衡量它的表现.有了算法的评估和误差度量值,有一件重要的事情要注意,就是使用一个合适的误差度量值,有时会对学习算法造成 ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | learning curves (改进学习算法:高偏差和高方差与学习曲线的关系)
绘制学习曲线非常有用,比如你想检查你的学习算法,运行是否正常.或者你希望改进算法的表现或效果.那么学习曲线就是一种很好的工具.学习曲线可以判断某一个学习算法,是偏差.方差问题,或是二者皆有. 为了绘制 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning - deciding what to try next(设计机器学习系统时,怎样确定最适合、最正确的方法)
假如我们在开发一个机器学习系统,想试着改进一个机器学习系统的性能,我们应该如何决定接下来应该选择哪条道路? 为了解释这一问题,以预测房价的学习例子.假如我们已经得到学习参数以后,要将我们的假设函数放到 ...
随机推荐
- 阿里云Https通配符证书购买
先付款,再绑定证书. 会款后会审核,等待... DNS解析配置错误 按域名授权配置,增加一条 DNS Txt记录值.
- Linux运维笔记-日常操作命令总结(2)
回想起来,从事linux运维工作已近5年之久了,日常工作中会用到很多常规命令,之前简单罗列了一些命令:http://www.cnblogs.com/kevingrace/p/5985486.html今 ...
- 网易2018.03.27算法岗,三道编程题100%样例AC题解
博主欢迎转载,但请给出本文链接,我尊重你,你尊重我,谢谢~http://www.cnblogs.com/chenxiwenruo/p/8660814.html特别不喜欢那些随便转载别人的原创文章又不给 ...
- C. Banh-mi
链接 [http://codeforces.com/contest/1062/problem/C] 题意 给你有n个字符(0 or 1)的串,当去某个位置时所有的剩下的位置都加上这个位置的数字,q次查 ...
- Personal Reading Assignment 2 -读推荐文章有感以及项目开发目前总结
在经过个人作业和结对作业的磨练和现在正在进行的团队作业的考验中,我对自己软件开发的一点得失有了些许感悟,同时读了老师推荐的文章后,自己也是有了一些感受. 首先在“No Silver Bullet”一文 ...
- Rop框架学习笔记
1. 提供了开发服务平台的解决方案:比如应用认证.会话管理.安全控制.错误模型.版本管理.超时限制 2. 启动:RopServlet截获http请求 配置: <servlet> < ...
- Linux内核分析 期末总结
Linux内核分析 期末总结 一.知识概要 1. 计算机是如何工作的 存储程序计算机工作模型:冯诺依曼体系结构 X86汇编基础 会变一个简单的C程序分析其汇编指令执行过程 2. 操作系统是如何工作的 ...
- 第二个spring冲刺第10天(及第二阶段总结)
第二阶段算是结束了,第二阶段,我们实现了基本的功能,这是软件的开始页面,点击便会进入学习画面,目前学习画面还有待改善 燃尽图3 眨眼就完结了第二阶段的冲刺了,大致整体结构已经完成. 第二阶段总体是 ...
- eclipse repository connector
- Windows查看端口被什么进程占用的简单方法----菜鸟养成
1. 还是因为同事告知Oracle的服务器连不上 最后发现改了端口就可以了, 但是很困惑 不知道为什么会这样,然后简单查了下: 命令 netstat -ano 查看监听的端口 baidu出来一个管道 ...