Kaggle-tiantic数据建模与分析
1.数据可视化
kaggle中数据解释:https://www.kaggle.com/c/titanic/data
数据形式:
读取数据,并显示数据信息
data_train = pd.read_csv("./data/train.csv")
print(data_train.info())
数据结果如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
数据解释:
PassengerId => 乘客ID
Survive => 乘客是否生还(仅在训练集中有,测试集中没有)
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
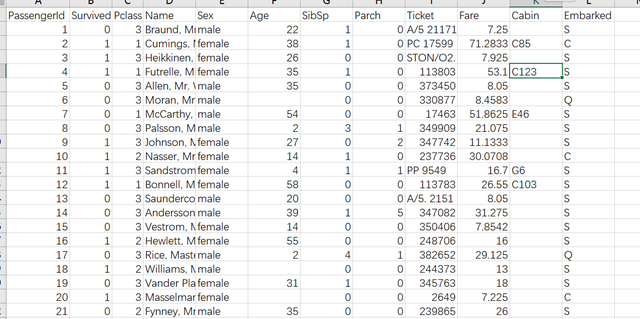
1.1 生存/死亡人数统计
# # 统计 存活/死亡 人数
def sur_die_analysis(data_train):
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)") # 标题
plt.ylabel(u"人数")
plt.show()
1.2 PClass

# PClass
def pclass_analysis(data_train):
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
sur_data = data_train.Pclass[data_train.Survived == 1].value_counts()
die_data = data_train.Pclass[data_train.Survived == 0].value_counts()
pd.DataFrame({'Survived':sur_data,'Died':die_data}).plot(kind='bar')
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.show()
通过数据分布可以很明显的看出 Pclass 为 1/2 的乘客存活率比 3 的高很多
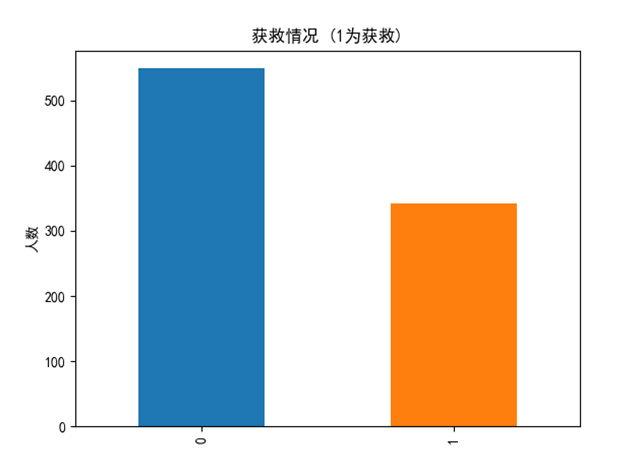
1.3 Sex
#Sex
def sex_analysis(data_train):
no_survived_g = data_train.Sex[data_train.Survived == 0].value_counts()
no_survived_g.to_csv("no_survived_g.csv")
survived_g = data_train.Sex[data_train.Survived == 1].value_counts()
df_g = pd.DataFrame({'Survived': survived_g, 'Died': no_survived_g})
df_g.plot(kind='bar', stacked=True)
plt.title('性别存活率分析')
plt.xlabel('People')
plt.ylabel('Survive')
plt.show()
女性的存活率比男性高
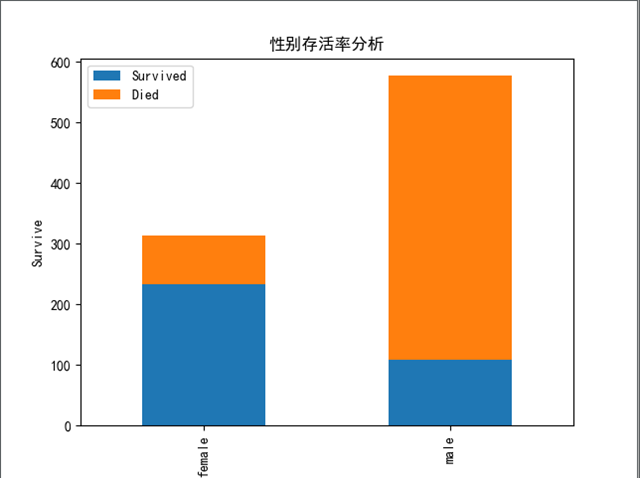
1.4 Age
# age : 将年龄分成十段,分别统计 存活人数和死亡人数
def age_analysis(data_train):
data_series = pd.DataFrame(columns=['Survived', 'dies'])
cloms = []
for num in range(0, 10):
clo = "" + str(num * 10) + "-" + str((num + 1) * 10)
cloms.append(clo)
sur_df = data_train.Age[(10 * (num + 1) > data_train.Age) & (10 * num < data_train.Age) & (data_train.Survived == 1)].shape[0]
die_df = data_train.Age[(10 * (num + 1) > data_train.Age) & (10 * num < data_train.Age) & (data_train.Survived == 0)].shape[0]
data_series.loc[num] = [sur_df,die_df]
data_series.index = cloms
data_series.plot(kind='bar', stacked=True)
plt.ylabel(u"存活率") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布")
plt.show()
低年龄段的获救的百分比明显占的比例较多
1.5 Family : SibSp + Parch
定义Family项,代表家庭成员数量,并离散分类为三个等级:
0: 代表没有任何成员
1: 1-4
2: > 4
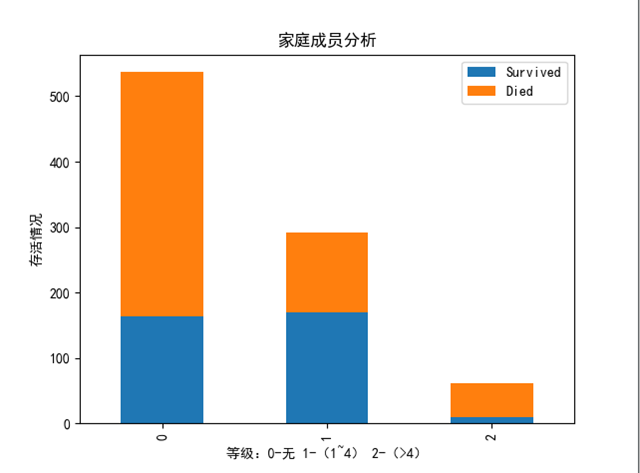
# Family: Sibsp + Parch 家庭成员人数
def family_analysis(data_train):
data_train['Family'] = data_train['SibSp'] + data_train['Parch']
data_train.loc[(data_train.Family == 0), 'Family'] = 0
data_train.loc[((data_train.Family > 0) & (data_train.Family < 4)), 'Family'] = 1
data_train.loc[((data_train.Family >= 4)), 'Family'] = 2 no_survived_g = data_train.Family[data_train.Survived == 0].value_counts()
survived_g = data_train.Family[data_train.Survived == 1].value_counts()
df_g = pd.DataFrame({'Survived': survived_g, 'Died': no_survived_g})
df_g.plot(kind='bar', stacked=True)
plt.title('家庭成员分析')
plt.xlabel('等级:0-无 1-(1~4) 2-(>4)')
plt.ylabel('存活情况')
plt.show()
由于数据分布很不均衡,sibsp 是否和存活率的关系,可以将所有列都除以该列总人数。这里不再赘述。
1.6 Fare
费用统计:
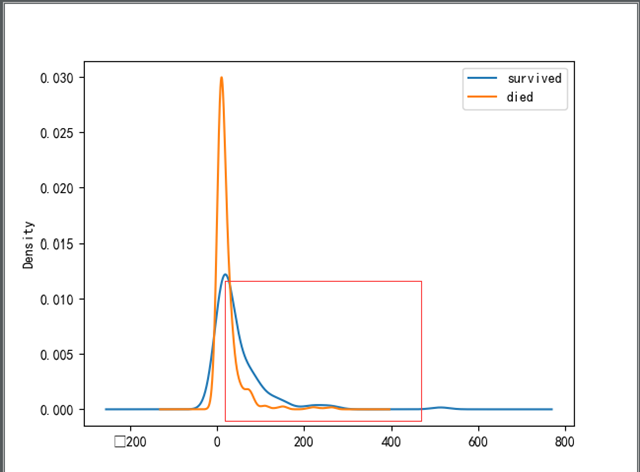
当费用升高到一定时,存活人数已经超过了死亡人数
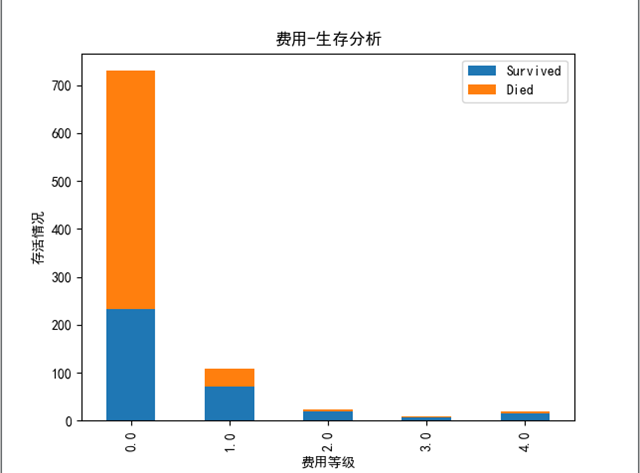
# Fare
def fare_analysis(data_train):
# data_train.Fare[data_train.Survived == 1].plot(kind='kde')
# data_train.Fare[data_train.Survived == 0].plot(kind='kde')
# data_train["Fare"].plot(kind='kde')
# plt.legend(('survived', 'died','all'), loc='best')
# plt.show()
data_train['NewFare'] = data_train['Fare']
data_train.loc[(data_train.Fare < 50), 'NewFare'] = 0
data_train.loc[((data_train.Fare>=50) & (data_train.Fare<100)), 'NewFare'] = 1
data_train.loc[((data_train.Fare >= 100) & (data_train.Fare < 150)), 'NewFare'] = 2
data_train.loc[((data_train.Fare >= 150) & (data_train.Fare < 200)), 'NewFare'] = 3
data_train.loc[(data_train.Fare >= 200), 'NewFare'] = 4
no_survived_g = data_train.NewFare[data_train.Survived == 0].value_counts()
survived_g = data_train.NewFare[data_train.Survived == 1].value_counts()
df_g = pd.DataFrame({'Survived': survived_g, 'Died': no_survived_g})
df_g.plot(kind='bar', stacked=True)
plt.title('费用-生存分析')
plt.xlabel('费用等级')
plt.ylabel('存活情况')
plt.show()
很明显可以看出 费用等级较高的人存活率会高很多。
优化:
上述只是任意的选取了五个费用段,作为五类,但是具体是多少类才能最好的拟合数据?
这里可以通过聚类的方法查找最佳的分类个数,再将每个费用数据映射为其中一类:
def fare_kmeans(data_train):
for i in range(2,10):
clusters = KMeans(n_clusters=i)
clusters.fit(data_train['Fare'].values.reshape(-1,1))
# intertia_ 参数是衡量聚类的效果,越大则表明效果越差
print("" + str(i) + "" + str(clusters.inertia_))
打印结果:
2 846932.9762272763
3 399906.26606199215
4 195618.50643749788
5 104945.73652631264
6 52749.474696547695
7 35141.316334118805
8 26030.553497795216
9 19501.242236941747
由此可以看出看出当 类别数为 5 时分类的效果最好。所以这里将所有的费用映射到为这五类。
#将费用进行聚类,发现 类别数为 5 时聚合的效果最好
def fare_kmeans(data_train):
clusters = KMeans(n_clusters=5)
clusters.fit(data_train['Fare'].values.reshape(-1, 1))
predict = clusters.predict(data_train['Fare'].values.reshape(-1, 1))
print(predict)
data_train['NewFare'] = predict
print(data_train[['NewFare','Survived']].groupby(['NewFare'],as_index=False).mean())
print("" + str(clusters.inertia_))
等级映射后每个等级的存活率如下:(效果明显比上面随便分类的好)
NewFare Survived
0 0 0.319832
1 1 0.647059
2 2 0.606557
3 3 1.000000
4 4 0.757576
1.7 Embarked
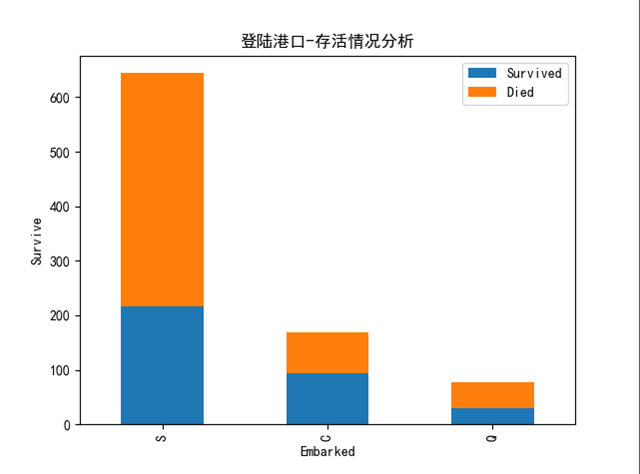
#Embarked 上船港口情况
def embarked_analysis(data_train):
no_survived_g = data_train.Embarked[data_train.Survived == 0].value_counts()
survived_g = data_train.Embarked[data_train.Survived == 1].value_counts()
df_g = pd.DataFrame({'Survived': survived_g, 'Died': no_survived_g})
df_g.plot(kind='bar', stacked=True)
plt.title('登陆港口-存活情况分析')
plt.xlabel('Embarked')
plt.ylabel('Survive')
plt.show()
至于就登陆港口而言,三个港口并看不出明显的差距,C港生还率略高于S港与Q港。
2. 数据预处理
由开头部分数据信息可以看出,有几栏的数据是部分缺失的: Age / Cabin / Embarked
对于缺失数据这里选择简单填充的方式进行处理:(可以以中值/均值/众数等方式填充)
同时对费用进行分类
def dataPreprocess(df):
df.loc[df['Sex'] == 'male', 'Sex'] = 0
df.loc[df['Sex'] == 'female', 'Sex'] = 1 # 由于 Embarked中有两个数据未填充,需要先将数据填满
df['Embarked'] = df['Embarked'].fillna('S')
# 部分年龄数据未空, 填充为 均值
df['Age'] = df['Age'].fillna(df['Age'].median()) df.loc[df['Embarked']=='S', 'Embarked'] = 0
df.loc[df['Embarked'] == 'C', 'Embarked'] = 1
df.loc[df['Embarked'] == 'Q', 'Embarked'] = 2 df['FamilySize'] = df['SibSp'] + df['Parch']
df['IsAlone'] = 0
df.loc[df['FamilySize']==0,'IsAlone'] = 1
df.drop('FamilySize',axis = 1)
df.drop('Parch',axis=1)
df.drop('SibSp',axis=1)
return fare_kmeans(df) def fare_kmeans(data_train):
clusters = KMeans(n_clusters=5)
clusters.fit(data_train['Fare'].values.reshape(-1, 1))
predict = clusters.predict(data_train['Fare'].values.reshape(-1, 1))
data_train['NewFare'] = predict
data_train.drop('Fare')
# print(data_train[['NewFare','Survived']].groupby(['NewFare'],as_index=False).mean())
# print(" " + str(clusters.inertia_))
return data_train
这里对与分类特征通过了普通的编码方式进行实现,也可以通过onehot编码使每种分类之间的间隔相等。
3. 特征选择
上述感性的认识了各个特征与存活率之间的关系,其实sklearn库中提供了对每个特征打分的函数,可以很方便的看出各个特征的重要性
predictors = ["Pclass", "Sex", "Age", "NewFare", "Embarked",'IsAlone']
# Perform feature selection
selector = SelectKBest(f_classif, k=5)
selector.fit(data_train[predictors], data_train["Survived"])
# Plot the raw p-values for each feature,and transform from p-values into scores
scores = -np.log10(selector.pvalues_)
# Plot the scores. See how "Pclass","Sex","Title",and "Fare" are the best?
plt.bar(range(len(predictors)),scores)
plt.xticks(range(len(predictors)),predictors, rotation='vertical')
plt.show()
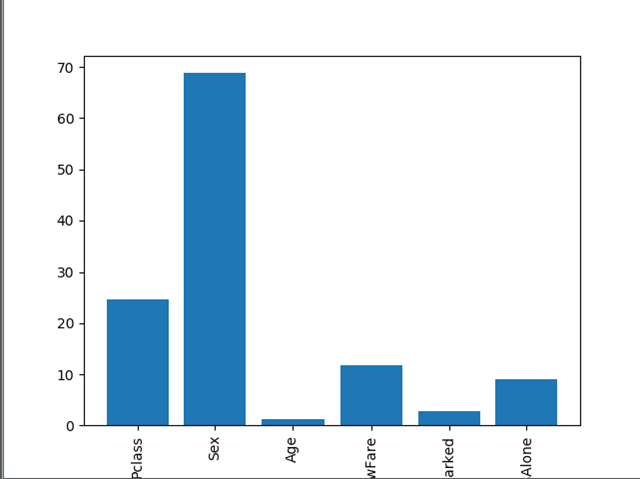
上图可以看到输入的6个特征中那些特征比较重要
4. 线性回归建模
def linearRegression(df):
predictors = ['Pclass', 'Sex', 'Age', 'IsAlone', 'NewFare', 'Embarked']
#predictors = ['Pclass', 'Sex', 'Age', 'IsAlone', 'NewFare', 'EmbarkedS','EmbarkedC','EmbarkedQ'] alg = LinearRegression()
X = df[predictors]
Y = df['Survived']
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2) # 打印 训练集 测试集 样本数量
print (X_train.shape)
print (Y_train.shape)
print (X_test.shape)
print (Y_test.shape) # 进行拟合
alg.fit(X_train, Y_train) print (alg.intercept_)
print (alg.coef_) Y_predict = alg.predict(X_test)
Y_predict[Y_predict >= 0.5 ] = 1
Y_predict[Y_predict < 0.5] = 0
acc = sum(Y_predict==Y_test) / len(Y_predict)
return acc
测试模型预测准确率: 0.79
5. 随机森林建模
选取最有价值的5个特征进行模型训练,并验证模型的效果:
def randomForest(data_train):
# Pick only the four best features.
predictors = ["Pclass", "Sex", "NewFare", "Embarked", 'IsAlone']
X_train, X_test, Y_train, Y_test = train_test_split(data_train[predictors], data_train['Survived'], test_size=0.2)
alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=8, min_samples_leaf=4)
alg.fit(X_train, Y_train)
Y_predict = alg.predict(X_test)
acc = sum(Y_predict == Y_test) / len(Y_predict)
return acc
经过测试该模型的准确率为 0.811
初步原因分析: 选取的5个特征中没有Age,Age可能因为缺失很大部分数据对预测的准确率有一定的影响。
代码已经提交git: https://github.com/lsfzlj/kaggle
欢迎指正交流
参考:
https://blog.csdn.net/han_xiaoyang/article/details/49797143
https://blog.csdn.net/CSDN_Black/article/details/80309542
https://www.kaggle.com/sinakhorami/titanic-best-working-classifier
Kaggle-tiantic数据建模与分析的更多相关文章
- 【Wyn Enterprise BI知识库】 认识多维数据建模与分析 ZT
与业务系统类似,商业智能的基础是数据.但是,因为关注的重点不同,业务系统的数据使用方式和商业智能系统有较大差别.本文主要介绍的就是如何理解商业智能所需的多维数据模型和多维数据分析. 数据立方体 多维数 ...
- 【干货】Kaggle 数据挖掘比赛经验分享(mark 专业的数据建模过程)
简介 Kaggle 于 2010 年创立,专注数据科学,机器学习竞赛的举办,是全球最大的数据科学社区和数据竞赛平台.笔者从 2013 年开始,陆续参加了多场 Kaggle上面举办的比赛,相继获得了 C ...
- BW顾问必需要清楚的:时间相关数据建模场景需求分析
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- NoSQL 数据建模技术(转)
本文转载自:http://coolshell.cn/articles/7270.html ================================================ 全文译自墙外 ...
- 【mysql的设计与优化专题(1)】ER图,数据建模与数据字典
需求分析是做项目中的极为重要的一环,而作为整个项目中的'血液'--数据,更是重中之重.viso,workbench,phpmyadmin等软件可以帮我们更好的处理数据分析问题. ER图 E-R方法是& ...
- NoSQL数据建模技术
原文来自“NoSQL Data Modeling Techniques”,由酷壳网陈皓编译<NoSQL数据建模技术>.这篇文章看完之后,你可能会对NoSQL的数据结构会有些感觉.我的感觉是 ...
- PowerBI 第二篇:数据建模
在分析数据时,不可能总是对单个数据表进行分析,有时需要把多个数据表导入到PowerBI中,通过多个表中的数据及其关系来执行一些复杂的数据分析任务,因此,为准确计算分析的结果,需要在数据建模中,创建数据 ...
- [转] [Elasticsearch] 数据建模 - 处理关联关系(1)
[Elasticsearch] 数据建模 - 处理关联关系(1) 标签: 建模elasticsearch搜索搜索引擎 2015-08-16 23:55 6958人阅读 评论(0) 收藏 举报 分类: ...
- PowerBI开发 第二篇:数据建模
在分析数据时,不可能总是对单个数据表进行分析,有时需要把多个数据表导入到PowerBI中,通过多个表中的数据及其关系来执行一些复杂的数据分析任务,因此,为准确计算分析的结果,需要在数据建模中,创建数据 ...
随机推荐
- python生成器(generator)、迭代器(iterator)、可迭代对象(iterable)区别
三者联系 迭代器(iterator)是一个更抽象的概念,任何对象,如果它的类有next方法(next python3)和__iter__方法返回自己本身,即为迭代器 通常生成器是通过调用一个或多个yi ...
- NoSql 数据库理解
主要分类: 键值(Key-Value)存储数据库 这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据.Key/value模型对于IT系统来说的优势在于简单.易部署.但是 ...
- git 忽略文件不起作用
本人需要提交项目文件,发现总有一些东西不需要提交,然后搜索有”.gitignore”文件可以忽略一些提交,但是发现添加上没有起作用. 要贴的是: /build/ target/ .idea/ *.im ...
- 代码之髓读后感——类&继承
面向对象 语言中的用语并不是共通的,在不同语言中,同一个用语的含义可能会有很大差别. C++的设计者本贾尼·斯特劳斯特卢普对类和继承给予了正面肯定,然而,"面向对象"这个词的发明者 ...
- Fefora 14 源
默认的源不能用,需要用下边的源路径. [fedora] name=Fedora $releasever - $basearch failovermethod=priority #baseurl=htt ...
- 微信浏览器Ajax请求返回值走error
微信浏览器Ajax post请求是返回值走的error $.ajax({ type: "POST", url: "https://XXXX", cache: f ...
- selenium_unittest基本框架
from selenium import webdriver import unittest import time #创建类引入unitest.testcase用例库 class BaiDu_tes ...
- MUI的一些笔记
自定义图标 https://www.iconfont.cn选择图标添加入购物车 进入项目管理下载需要的图标压缩包之后按照自己的需求进行html的操作 事件绑定 mui(dom)on( event , ...
- SpringMCV跨域
不在同服务器访问就会产生跨域(用其他软件编写HTML测试) 后台Controller package edu.nf.ch02.controller; import org.springframewor ...
- ABP框架系列之五十四:(XSRF-CSRF-Protection-跨站请求伪造保护)
Introduction "Cross-Site Request Forgery (CSRF) is a type of attack that occurs when a maliciou ...