Nginx技术研究系列5-动态路由升级版
前几篇文章我们介绍了Nginx的配置、OpenResty安装配置、基于Redis的动态路由以及Nginx的监控。
Nginx技术研究系列1-通过应用场景看Nginx的反向代理
[原创]Nginx监控-Nginx+Telegraf+Influxb+Grafana
在分布式环境下,我们要考虑高可用性和性能:
1. 不能因为Redis宕机影响请求的反向代理
2. 每次请求如果都访问Redis,性能有一定的损耗,同时Redis集群的压力随着流量的激增不断增加。
因此,我们要升级一下动态路由的设计方案。 我们还是先从应用场景出发:
1.提升性能,降低Redis的访问频率
2.Redis宕机不影响Nginx反向代理
实现上述两个应用场景,我们采用本地缓存+Redis缓存的双缓存配合机制。
- 第一次请求时,从Redis中获取路由地址,然后放到本地缓存中,同时设置本地缓存项的有效时间
- 后续请求时,从本地缓存直接获取路由地址,如果本地缓存已经失效,则再次从Redis获取路由地址,再放到本地缓存中。
确定了上述实现方案后,我们回顾一下我们已有的Redis动态路由实现:
upstream redis_cluster {
server 192.0..*:;
server 192.0..*:;
server 192.0..*:;
}
location = /redis {
internal;
set_unescape_uri $key $arg_key;
redis2_query get $key;
redis2_pass redis_cluster;
}
location / {
set $target '';
access_by_lua '
local query_string = ngx.req.get_uri_args()
local sid = query_string["RequestID"]
if sid == nil then
ngx.exit(ngx.HTTP_FORBIDDEN)
end
local key = sid
local res = ngx.location.capture(
"/redis", { args = { key = key } }
)
if res.status ~= then
ngx.log(ngx.ERR, "redis server returned bad status: ",
res.status)
ngx.exit(res.status)
end
if not res.body then
ngx.log(ngx.ERR, "redis returned empty body")
ngx.exit()
end
local parser = require "redis.parser"
local server, typ = parser.parse_reply(res.body)
if typ ~= parser.BULK_REPLY or not server then
ngx.log(ngx.ERR, "bad redis response: ", res.body)
ngx.exit()
end
if server == "" then
server = "default"
end
server = server .. ngx.var.request_uri
ngx.var.target = server
';
resolver 255.255.255.0;
proxy_pass http://$target;
}
我们要在上述代码中增加一层本地缓存实现,因此,我们需要找一个本地缓存的实现Lib。
我们在OpenResty的官网上找了一遍已提供的组件,发现了:lua-resty-lrucache - Lua-land LRU Cache based on LuaJIT FFI
Git Hub的地址:https://github.com/openresty/lua-resty-lrucache
尝试写了一下,发现这个cache实现是worker进程级别的,我们Nginx是Auto的进程数配置,一般有4~8个,这个缓存每个进程都New一个,貌似不符合我们的要求,同时,这个cache是预分配好缓存的大小和数量,启动的时候如果数量太多,分配内存很慢。
测试了一下,果真是这样,因此,我们继续查找新的Cache实现。
ngx.shared.DICT,https://github.com/openresty/lua-nginx-module#ngxshareddict
这个 cache 是 nginx 所有 worker 之间共享的,内部使用的 LRU 算法(最近经常使用)来判断缓存是否在内存占满时被清除。同时提供了如下方法:
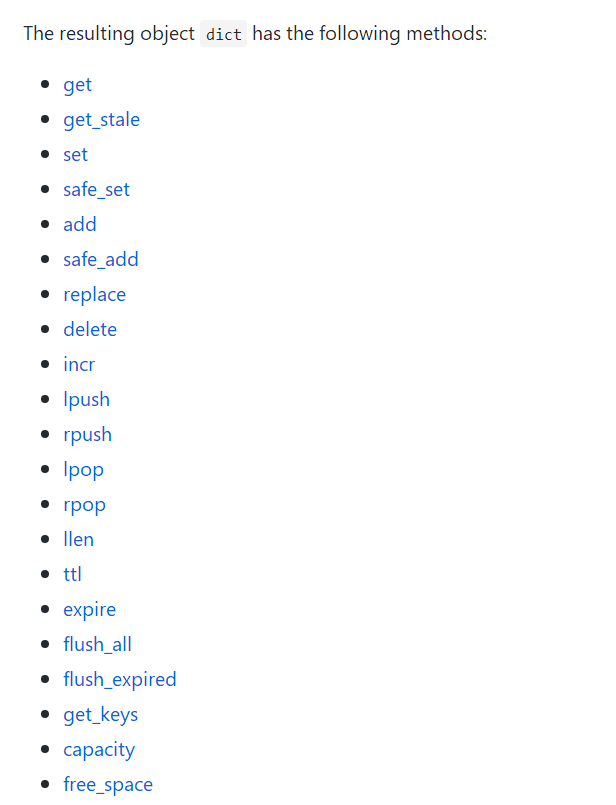
然后,我们基于这个组件实现了我们升级版的Redis动态路由,直接上代码Show:
upstream redis_cluster {
server 192.0..*:;
server 192.0..*:;
server 192.0..*:;
}
lua_shared_dict localcache 10m;——
location = /redis {
internal;
set_unescape_uri $key $arg_key;
redis2_query get $key;
redis2_pass redis_cluster;
}
location / {
set $target '';
access_by_lua '
local query_string = ngx.req.get_uri_args()
local sid = query_string["RequestID"]
if sid == nil then
ngx.exit(ngx.HTTP_FORBIDDEN)
end
local key = sid
local cache = ngx.shared.localcache
local server = cache:get(key)
if server == nil then
local res = ngx.location.capture(
"/redis", { args = { key = key } }
)
if res.status ~= then
ngx.log(ngx.ERR, "redis server returned bad status: ",
res.status)
ngx.exit(res.status)
end
if not res.body then
ngx.log(ngx.ERR, "redis returned empty body")
ngx.exit()
end
local parser = require "redis.parser"
local serveradr, typ = parser.parse_reply(res.body)
if typ ~= parser.BULK_REPLY or not serveradr then
ngx.log(ngx.ERR, "bad redis response: ", res.body)
ngx.exit()
end
server = serveradr
cache:set(key, server,3)
end
if server == "" then
server = "default"
end
server = server .. ngx.var.request_uri
ngx.var.target = server
';
resolver 255.255.255.0;
proxy_pass http://$target;
}
}
重点说一下上面的代码:
首先,定义了一个本地缓存:
lua_shared_dict localcache 10m;
然后,从本地缓存中获取路由地址
local cache = ngx.shared.localcache
local server = cache:get(key)
如果本地缓存中没有,从Redis中获取,从Redis中获取到之后,加入到本地缓存中,缓存有效时间3600s:
server = serveradr
cache:set(key, server, )
升级后的Redis+本地缓存的动态路由方案,压测性能提升1.4倍,同时解决了Redis宕机的问题。
以上这个方案和实现都分享给大家。
周国庆
2017/11/13
Nginx技术研究系列5-动态路由升级版的更多相关文章
- Nginx技术研究系列2-基于Redis实现动态路由
上篇博文我们写了个引子: Ngnix技术研究系列1-通过应用场景看Nginx的反向代理 发现了新大陆,OpenResty OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台 ...
- Nginx技术研究系列3-OpenResty安装配置
上两篇中介绍了: Ngnix技术研究系列1-通过应用场景看Nginx的反向代理 Ngnix技术研究系列2-基于Redis实现动态路由 发现,应该加一篇OpenResty的安装部署说明,方便大家按图索骥 ...
- Nginx技术研究系列6-配置详解
前两篇文章介绍了Nginx反向代理和动态路由: Ngnix技术研究系列1-通过应用场景看Nginx的反向代理 Ngnix技术研究系列2-基于Redis实现动态路由 随着研究的深入,很重要的一点就是了解 ...
- Nginx技术研究系列1-通过应用场景看Nginx的反向代理
随着我们业务规模的不断增长,整个系统规模由两年前的几十台服务器,井喷到现在2个数据中心,接近400台服务器,上百个WebApi站点,上百个域名. 这么多的WebApi站点这么多的域名,管理和维护成本很 ...
- Nginx技术研究系列7-Azure环境中Nginx高可用性和部署架构设计
前几篇文章介绍了Nginx的应用.动态路由.配置.在实际生产环境部署时,我们需要同时考虑Nginx的高可用性和部署架构. Nginx自身不支持集群以保证自身的高可用性,商业版本的Nginx+推荐: T ...
- Nginx技术研究系列4-Nginx监控-Nginx+Telegraf+Influxb+Grafana
搭建了Nginx集群后,需要继续深入研究的就是日常Nginx监控. Nginx如何监控?相信百度就可以找到:nginx-status 通过Nginx-status,实时获取到Nginx监控数据后,如何 ...
- Ngnix技术研究系列2-基于Redis实现动态路由
上篇博文我们写了个引子: Ngnix技术研究系列1-通过应用场景看Nginx的反向代理 发现了新大陆,OpenResty OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台 ...
- Azure IoT 技术研究系列2-起步示例之设备注册到Azure IoT Hub
上篇博文中,我们主要介绍了Azure IoT Hub的基本概念.架构.特性: Azure IoT 技术研究系列1-入门篇 本文中,我们继续深入研究,做一个起步示例程序:模拟设备注册到Azure IoT ...
- Azure IoT 技术研究系列3-设备到云、云到设备通信
上篇博文中我们将模拟设备注册到Azure IoT Hub中:我们得到了设备的唯一标识. Azure IoT 技术研究系列2-设备注册到Azure IoT Hub 本文中我们继续深入研究,设备到云.云到 ...
随机推荐
- Web重温系列(三):OracleDependency实现监听数据库变化
有个小项目(后来由另一个小组以Java开发了),内容是监控一个Oracle数据库.如果其中一个表A有数据变动,则需要将相关内容重组后通过接口发送给B. 通常的解决办法是定时查询,时间间隔可以小一点,还 ...
- R par yaxp xaxp 显示x轴和y轴的刻度线
R语言会自动根据数据的范围,在X轴和Y轴上标记合适的刻度 > options(scipen = ) > plot(sample(:, )) 生成的图片如下 通过par("yaxp ...
- thinkphp3.2在nginx下的配置
最近一直没用nginx 昨天将tp3.2的项目部署到Ubuntu下的nginx下,发现忘记怎么配置的了 特将配置方式记录下来,以方便日后查找 服务器nignx 配置文件 server { listen ...
- redis实战 -- python知识散记
-- time.time() -- row.to_dict() -- json.dumps(row.to_dict()) #!/usr/bin/env python import time def s ...
- ELK日志收集
目前日志的痛点 运维要经常登陆到服务器上拿日志给开发.测试 每次都是出问题后才去看日志,不能提前通过日志预判问题 如果是集群服务,日志将要从多台机器取 开发人员搞出来的日志不规范,没有标准.日志目录不 ...
- vue2.0 在微信端如何使用本地IP访问项目
我们会遇到这样的需求,在PC端开发vue脚手架项目,希望在微信端随时浏览页面(如果打包再发布到服务器又太麻烦),怎么办? 思路很简单:保证手机和电脑在同一个IP下,用同一个IP访问项目,这样就可以了: ...
- 【IEEE会议论文】格式规范问题
- Text area: The height of the text should not be much smaller than 23.5 cm and the width should no ...
- ssl证书类型
SSL证书依据功能和品牌不同分类有所不同,但SSL证书作为国际通用的产品,最为重要的便是产品兼容性(即证书根预埋技术),因为他解决了网民登录网站的信任问题,网民可以通过SSL证书轻松识别网站的真实身份 ...
- unicode 与 utf-8 编码概念及区别
unicode 是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案.每个字符都对应一个编号,编号的范围是0-0x10FFFF来.Unicode 是为了解决传统的字符编码方案的局限而产生的,它为 ...
- DCL并非单例模式专用
我相信大家都很熟悉DCL,对于缺少实践经验的程序开发人员来说,DCL的学习基本限制在单例模式,但我发现在高并发场景中会经常遇到需要用到DCL的场景,但并非用做单例模式,其实DCL的核心思想和CopyO ...