Hadoop源码系列(一)FairScheduler申请和分配container的过程
1、如何申请资源
1.1 如何启动AM并申请资源
1.1.1 如何启动AM
val yarnClient = YarnClient.createYarnClient setupCredentials() yarnClient.init(yarnConf) yarnClient.start() // Get a new application from our RM val newApp = yarnClient.createApplication() val newAppResponse = newApp.getNewApplicationResponse() appId = newAppResponse.getApplicationId() // Set up the appropriate contexts to launch our AM val containerContext = createContainerLaunchContext(newAppResponse) val appContext = createApplicationSubmissionContext(newApp, containerContext) // Finally, submit and monitor the application logInfo(s"Submitting application $appId to ResourceManager") yarnClient.submitApplication(appContext)
1.1.2 FairScheduler如何处理AM的ResourceRequest
1、FairScheduler接收到SchedulerEventType.APP_ADDED之后,调用addApplication方法把把RMApp添加到队列里面,结束之后发送RMAppEventType.APP_ACCEPTED给RMApp
2、RMApp启动RMAttempt之后,发送SchedulerEventType.APP_ATTEMPT_ADDED给FairScheduler
LOG.info("Added Application Attempt " + applicationAttemptId + " to scheduler from user: " + user);
3、FairScheduler调用addApplicationAttempt方法,发送RMAppAttemptEventType.ATTEMPT_ADDED事件给RMAppAttempt,RMAppAttempt随后调用Scheduler的allocate方法发送AM的ResourceRequest
4、FairScheduler在allocate方法里面对该请求进行处理,FairScheduler对于AM的资源请求的优先级上并没有特殊的照顾,详细请看章节2 如何分配资源
1.2 AM启动之后如何申请资源
1.2.1、注册AM
amClient = AMRMClient.createAMRMClient() amClient.init(conf) amClient.start() amClient.registerApplicationMaster(Utils.localHostName(), 0, uiAddress)
1.2.2、发送资源请求
// 1.创建资源请求
amClient.addContainerRequest(request)
// 2.发送资源请求
val allocateResponse = amClient.allocate(progressIndicator)
val allocatedContainers = allocateResponse.getAllocatedContainers()
if (allocatedContainers.size > 0) {
// 3.请求返回之后处理Container
handleAllocatedContainers(allocatedContainers.asScala)
}
1.2.3、启动Container
def startContainer(): java.util.Map[String, ByteBuffer] = {
val ctx = Records.newRecord(classOf[ContainerLaunchContext])
.asInstanceOf[ContainerLaunchContext]
val env = prepareEnvironment().asJava
ctx.setLocalResources(localResources.asJava)
ctx.setEnvironment(env)
val credentials = UserGroupInformation.getCurrentUser().getCredentials()
val dob = new DataOutputBuffer()
credentials.writeTokenStorageToStream(dob)
ctx.setTokens(ByteBuffer.wrap(dob.getData()))
val commands = prepareCommand()
ctx.setCommands(commands.asJava)
ctx.setApplicationACLs(YarnSparkHadoopUtil.getApplicationAclsForYarn(securityMgr).asJava)
// If external shuffle service is enabled, register with the Yarn shuffle service already
// started on the NodeManager and, if authentication is enabled, provide it with our secret
// key for fetching shuffle files later
if (sparkConf.get(SHUFFLE_SERVICE_ENABLED)) {
val secretString = securityMgr.getSecretKey()
val secretBytes =
if (secretString != null) {
// This conversion must match how the YarnShuffleService decodes our secret
JavaUtils.stringToBytes(secretString)
} else {
// Authentication is not enabled, so just provide dummy metadata
ByteBuffer.allocate(0)
}
ctx.setServiceData(Collections.singletonMap("spark_shuffle", secretBytes))
}
// Send the start request to the ContainerManager
try {
nmClient.startContainer(container.get, ctx)
} catch {
case ex: Exception =>
throw new SparkException(s"Exception while starting container ${container.get.getId}" +
s" on host $hostname", ex)
}
}
2、如何分配资源
2.1 接受资源请求步骤
在FairScheduler的allocate方法里面仅仅是记录ResourceRequest,并不会真正的立马分配。
流程如下:
1、检查该APP是否注册过
2、检查资源的请求是否超过最大内存和最大CPU的限制
3、记录资源请求的时间,最后container分配的延迟会体现在队列metrics的appAttemptFirstContainerAllocationDelay当中
4、释放AM发过来的已经不需要的资源,主要逻辑在FSAppAttempt的containerCompleted方法里
5、更新资源请求,所有资源请求都是记录在AppSchedulingInfo当中的requests(注意:只有是ANY的资源请求才会被立马更新到QueueMetrics的PendingResources里)
6、找出该APP被标记为抢占的container ID列表preemptionContainerIds
7、更新APP的黑名单列表,该信息被记录在AppSchedulingInfo当中
8、从FSAppAttempt的newlyAllocatedContainers当中获取最新被分配的container
9、返回preemptionContainerIds、HeadRoom、ContainerList、NMTokenList。(注:Headroom = Math.min(Math.min(queueFairShare - queueUsage, 0), maxAvailableResource)
2.2 请求和分配的关系
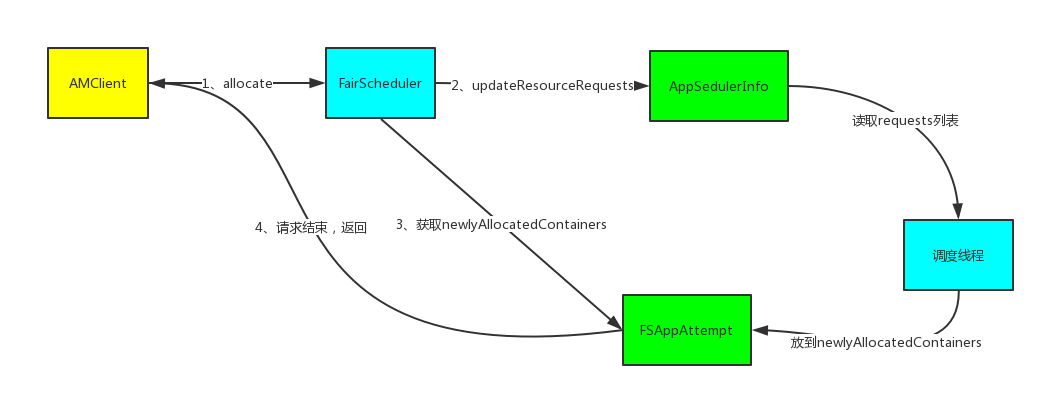
请求和分配的过程是异步的,关系如上图,每次调用allocate获得的container,其实是之前的请求被分配的结果
2.3 如何分配
2.3.1 分配方式
分配有两种方式:
1、接收到NodeManager的心跳的时候进行分配
NodeManager每隔一秒(yarn.resourcemanager.nodemanagers.heartbeat-interval-ms)给ResourceManager发送一个心跳事件NODE_UPDATE,接收到心跳事件之后,在FairScheduler的nodeUpdate方法里进行处理。
NodeManager会汇报新启动的Container列表newlyLaunchedContainers和已经结束的Container列表completedContainers。然后在attemptScheduling方法里面进行分配。
2、持续调度方式
它有一个单独的线程,线程名称是FairSchedulerContinuousScheduling,每5毫秒对所有节点的资源进行排序,然后遍历所有节点,调用attemptScheduling方法进行分配。
开启持续调度模式之后,在接收到心跳事件NODE_UPDATE的时候,只有在completedContainers不为空的情况下,才会进行调度
attemptScheduling首先会检查是否有资源预留,如果有预留,则直接为预留的APP分配container
没有预留的分配过程如下:
1、最大可分配资源为这台机器的可用资源的一半,从root队列开始自上而下进行分配Resource assignment = queueMgr.getRootQueue().assignContainer(node);
2、分配到一个Container之后,判断是否要连续分配多个,最大支持连续分配多少个?
以下是涉及到的各个参数以及参数的默认值:
yarn.scheduler.fair.assignmultiple false (建议设置为true)
yarn.scheduler.fair.dynamic.max.assign true (hadoop2.7之后就没有这个参数了)
yarn.scheduler.fair.max.assign -1 (建议设置为2~3,不要设置得太多,否则会有调度倾斜的问题)
2.3.2 如何从队列当中选出APP进行资源分配
入口在queueMgr.getRootQueue().assignContainer(node);
1、检查当前队列的使用量是否小于最大资源量
2、首先对子队列进行排序,优先顺序请参照章节 2.3.4 如何确定优先顺序
3、排序完再调用子队列的assignContainer方法分配container
4、一直递归到叶子队列
叶子队列如何进行分配?
1、先对runnableApps进行排序,排序完成之后,for循环遍历一下
2、先检查该Node是否在APP的黑名单当中
3、检查该队列是否可以运行该APP的AM,主要是检查是否超过了maxAMShare(根据amRunning字段判断是否已经启动了AM了)
检查逻辑的伪代码如下:
maxResource = getFairShare()
if (maxResource == 0) {
// 最大资源是队列的MaxShare和集群总资源取一个小的值
maxResource = Math.min(getRootQueue().AvailableResource(), getMaxShare());
}
maxAMResource = maxResource * maxAMShare
if (amResourceUsage + amResource) > maxAMResource) {
// 可以运行
return true
} else {
// 不可以运行
return false
}
4、给该APP分配container
下面以一个例子来说明分配的过程是如何选择队列的:
假设队列的结构是这样子的
root
---->BU_1
-------->A
-------->B
---->BU_2
-------->C
-------->D
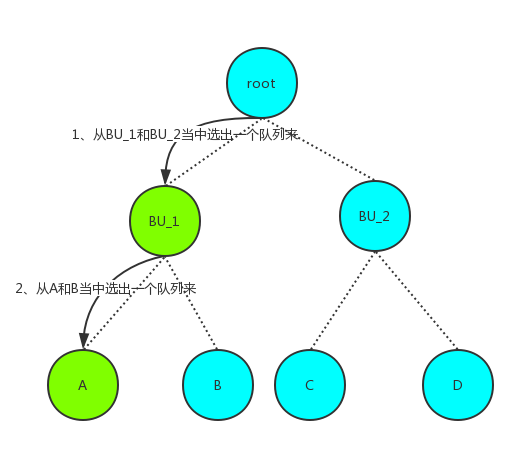
2.3.3 任务分配Container的本地性
任务分配Container的时候会考虑请求的本地性,对于调度器来说,它的本地性分为三种:NODE_LOCAL, RACK_LOCAL, OFF_SWITCH
具体方法位于FSAppAttempt的assignContainer方法
遍历优先级
给该优先级的调度机会+1
获取RackLocal和NodeLocal的任务
计算允许分配的本地性级别allowedLocality,默认是NODE_LOCAL
1、心跳分配方式
计算调度机会,如果该优先级的任务的调度机会超过了(节点数 * NODE_LOCAL阈值),降级为RACK_LOCAL,如果该优先级的任务的调度机会超过了(节点数 * RACK_LOCAL阈值),降级为OFF_SWITCH
2、连续分配方式
计算等待时间waitTime -= lastScheduledContainer.get(priority);
如果waitTime超过了NODE_LOCAL允许的delay时间,就降级为RACK_LOCAL,再超过RACK_LOCAL允许的delay的时间,就降级为OFF_SWITCH
分配NODE_LOCAL的container
允许分配的本地性级别>=RACK_LOCAL,分配RACK_LOCAL的container
允许分配的本地性级别=OFF_SWITCH,分配OFF_SWITCH的container
都分不到,等待下一次机会
相关参数:
默认值全是-1,则允许的本地性级别是OFF_SWITCH
yarn.scheduler.fair.locality-delay-node-ms -1
yarn.scheduler.fair.locality-delay-rack-ms -1
yarn.scheduler.fair.locality.threshold.node -1
yarn.scheduler.fair.locality.threshold.rack -1
2.3.4 Container分配
1、检查该节点的资源是否足够,如果资源充足
2、如果当前的allowedLocality比实际分配的本地性低,则重置allowedLocality
3、把新分配的Container加到newlyAllocatedContainers和liveContainers列表中
4、把分配的container信息同步到appSchedulingInfo当中
5、发送RMContainerEventType.START事件
6、更新FSSchedulerNode记录的container信息
7、如果被分配的是AM,则设置amRunning为true
如果资源不够,则检查是否可以预留资源
条件:
1)Container的资源请求必须小于Scheduler的增量分配内存 * 倍数(默认应该是2g)
2)如果已经存在的预留数 < 本地性对应的可用节点 * 预留比例
3)一个节点只允许同时为一个APP预留资源
相关参数:
yarn.scheduler.increment-allocation-mb 1024
yarn.scheduler.increment-allocation-vcores 1
yarn.scheduler.reservation-threshold.increment-multiple 2
yarn.scheduler.fair.reservable-nodes 0.05
2.3.4 如何确定优先顺序
该比较规则同时适用于队列和APP,详细代码位于FairSharePolicy当中
MinShare = Math.min(getMinShare(), getDemand())
1、(当前资源使用量 / MinShare)的比值越小,优先级越高
2、如果双方资源使用量都超过MinShare,则(当前资源使用量 / 权重)的比值越小,优先级越高
3、启动时间越早,优先级越高
4、最后实在比不出来,就比名字...
从上面分配的规则当中能看出来MinShare是非常重要的一个指标,当资源使用量没有超过MinShare之前,队列在分配的时候就会比较优先,切记一定要设置啊!
注:getMinShare()是FairScheduler当中队列的minResources
<minResources>6887116 mb,4491 vcores</minResources>
Hadoop源码系列(一)FairScheduler申请和分配container的过程的更多相关文章
- [Hadoop源码系列] FairScheduler分配申请和分配container的过程
1.如何申请资源 1.1 如何启动AM并申请资源 1.1.1 如何启动AM val yarnClient = YarnClient.createYarnClient setupCredentials( ...
- Hadoop源码解读系列目录
Hadoop源码解读系列 1.hadoop源码|common模块-configuration详解2.hadoop源码|core模块-序列化与压缩详解3.hadoop源码|core模块-远程调用与NIO ...
- 安装Hadoop系列 — 导入Hadoop源码项目
将Hadoop源码导入Eclipse有个最大好处就是通过 "ctrl + shift + r" 可以快速打开Hadoop源码文件. 第一步:在Eclipse新建一个Java项目,h ...
- 9 hbase源码系列(九)StoreFile存储格式
hbase源码系列(九)StoreFile存储格式 从这一章开始要讲Region Server这块的了,但是在讲Region Server这块之前得讲一下StoreFile,否则后面的不好讲下去 ...
- HBase源码系列之HFile
本文讨论0.98版本的hbase里v2版本.其实对于HFile能有一个大体的较深入理解是在我去查看"到底是不是一条记录不能垮block"的时候突然意识到的. 首先说一个对HFile ...
- Hadoop源码编译过程
一. 为什么要编译Hadoop源码 Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Libraries)的概念,通 ...
- [导入]Eclipse 导入/编译 Hadoop 源码
http://www.cnblogs.com/errorx/p/3779578.html 1.准备工作 jdk: eclipse: Maven: libprotoc :https://develope ...
- 基于Eclipse搭建Hadoop源码环境
Hadoop使用ant+ivy组织工程,无法直接导入Eclipse中.本文将介绍如何基于Eclipse搭建Hadoop源码环境. 准备工作 本文使用的操作系统为CentOS.需要的软件版本:hadoo ...
- Eclipse 导入 Hadoop 源码
1.准备工作 jdk: eclipse: Maven: libprotoc :https://developers.google.com/protocol-buffers/ hadoop:http:/ ...
随机推荐
- Centos中安装perl
1.安装gcc,在虚拟机命令窗口中输入:yum install -y gcc 2.下载perl安装包输入命令:wget http://www.cpan.org/src/5.0/perl-5.16.1. ...
- [PA2014]Lustra
[PA2014]Lustra 题目大意: 有n个工厂参加竞标.每个工厂能生产长度在\([a_i,b_i]\)之间,宽度在\([c_i,d_i]\)之间的镜子,镜子不可以旋转. 问是否有某个工厂能生产出 ...
- C++学习笔记46:模板与群体数据
函数模板 创建一个通用功能的函数,支持多种不同的形参:简化重载函数的函数体设计: 语法形式 template <模板参数表> 函数定义:模板参数表的内容:类型参数:class(或typen ...
- Yii2 baisic版gii的使用和分页
一.Gii 的使用 1.配置 gii 的位置: 在 config/web.php 里面: if (YII_ENV_DEV) { $config['bootstrap'][] = 'gii'; $con ...
- C盘清理(安装Visual Studio 或者Office后)
安装过Office,可能会存在一个C:\\MSOCache的隐藏目录,如果在D盘安装,这个文件夹可能会在D盘根目录下.该目录为Offices安装组件的目录,理解为安装包即可,如果日后不再修改OFFIC ...
- GMA Round 1 奇怪的数列
传送门 奇怪的数列 已知数列{$a_n$},$a_1=1$,$a_{n+1}=a_n+\frac{1}{a_n}$,现在需要你估计$a_{233333}$的值,求出它的整数部分即可. 将原等式两边平方 ...
- JAVA自学笔记11
JAVA自学笔记11 1:Eclipse的安装 2:用Eclipse写一个HelloWorld案例,最终在控制台输出你的名字 A:创建项目 B:在src目录下创建包.cn.itcast C:在cn.i ...
- Aizu2224 Save your cats(最大生成树)
https://vjudge.net/problem/Aizu-2224 场景嵌入得很好,如果不是再最小生成树专题里,我可能就想不到解法了. 对所有的边(栅栏)求最大生成树,剩下来的长度即解(也就是需 ...
- Java身份证归属地目录树
数据库结构: web管理界面: 目录树: 视频: 应用场景:
- 打开KVM Console的一些注意事项
今天早上跟思科CIMC里的KVM console较劲了很久,终于成功的打开了KVM console. 总结了下面的一些注意事项.如果你也遇到了KVM console打不开,那么可以尝试一下. 我不想花 ...