Storm概念学习系列之Tuple元组(数据载体)
不多说,直接上干货!
Tuple元组
Tuple 是 Storm 的主要数据结构,并且是 Storm 中使用的最基本单元、数据模型和元组。
Tuple 描述
Tuple 就是一个值列表, Tuple 中的值可以是任何类型的,动态类型的Tuple的fields可以不用声明;默认情况下,Storm中的Tuple支持私有类型、字符串、字节数组等作为它的字段值,如果使用其他类型,就需要序列化该类型。
Tuple的字段默认类型有 : integer、 float、 double、 long、short、 string、 byte、 binary(byte[])。
Tuple元组,是消息传递的基本单元,是一个命名的值列表,元组中的字段可以是任何类型的对象。Storm使用元组作为其数据模型,元组支持所有的基本类型、字符串和字节数组作为字段值,只要实现类型的序列化接口就可以使用该类型的对象。
元组本来应该是一个key-value的Map,但是由于各个组件间传递的元组的字段名称已经事先定义好,所以只要按序把元组填入各个value即可,所以元组是一个vlue的List。
Tuple是Storm采用的数据表示模型,所有的数据都以Tuple的形式在各个组件之间流动。Tuple是一组字段列表,每个字段由一个字段名和字段值组成,每个Tuple类似于数据库中的一行记录。在默认的情况下,Tuple的字段类型可以是integer、long、short、byte、string、double、float、boolean和byte array。当然,你也可以通过实现序列化器自定义类型。
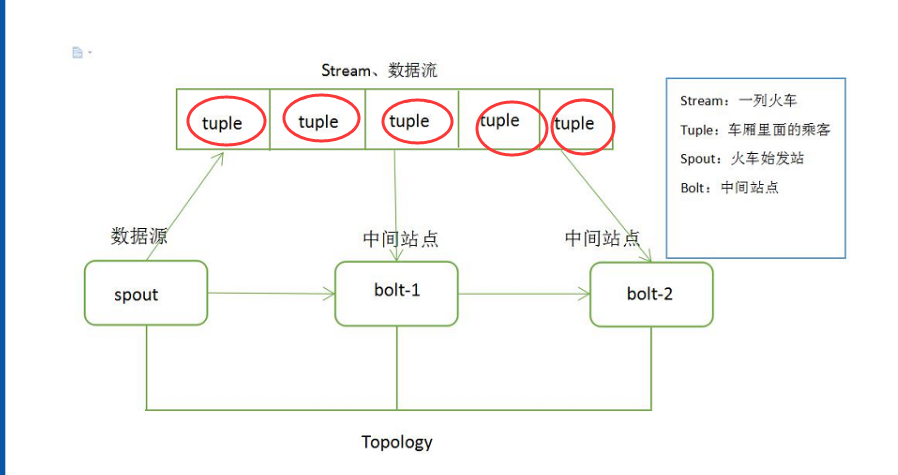
Tuple 数据结构如图 1 所示。

图 1 Tuple 数据结构
Tuple 可以理解成键值对。例如,创建一个Bolt 要发送两个字段(命名为 double 和 triple),其中键就是定义在declareOutputFields 方法中的 Fields 对象,值就是在 emit 方法中发送的 Values 对象。
以下是一个简单例子
public class DoubleAndTripleBolt extends BaseRichBolt {
OutputCollectorBase _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
public void execute(Tuple input) {
int val = input.getInteger();
_collector.emit(input, new Values(val*, val*));
_collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("double", "triple"));
}}
此外,在使用的 Storm Java 包中, backtype.storm.tuple 主要有以下几个类:
Fileds.class
MessageId.class
Tuple.class
TupleImpl.class
Values.class
列出以上内容是为了更好地理解 Tuple,这样能够从本质上理解 Tuple,在使用时更加得心应手。
Tuple 的生命周期
了解一个 Tuple 的生命周期就需要查看源码,如下的 Java 代码展示了 Spout(消息源)接口发出 Tuple(消息)的整个过程。
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
void close();
}
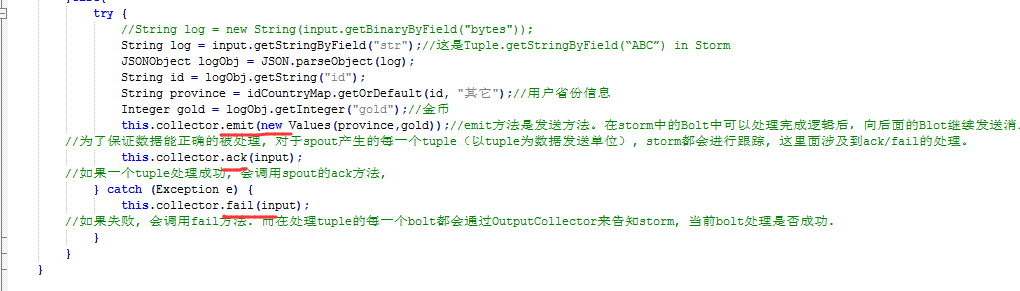
首 先, Storm 调 用 Spout(消息源)的nextTuple 方法来获取下一个Tuple, Spout通过Open 方法的参数提供的SpoutOutputCollector将新Tuple发射到其中一个输出消息流。
注意:发射Tuple 时, Spout提供一个message-id,通过这个ID 来追踪该Tuple。
接下来, Storm跟踪该Tuple的树形结构是否成功创建,并根据 messageid调用Spout中的ack函数,以确认Tuple是否被完全处理。如果Tuple超时,则调用 Spout 的 fail 方法。
由此看出,同一个Tuple不管是acked,还是failed都是由创建它的Spout发出并维护的,所以,即使Spout 在集群环境中同时执行很多的任务,该Tuple 也不会被其他任务调用或生成 acked或 failed 状态。总之, Storm会利用内部的 Acker 机制保证每个Tuple 被可靠地处理。最后,在任务完成后,Spout调用Close方法结束 Tuple 的使命。
比如
Storm概念学习系列之Tuple元组(数据载体)的更多相关文章
- Storm概念学习系列之核心概念(Tuple、Spout、Blot、Stream、Stream Grouping、Worker、Task、Executor、Topology)(博主推荐)
不多说,直接上干货! 以下都是非常重要的storm概念知识. (Tuple元组数据载体 .Spout数据源.Blot消息处理者.Stream消息流 和 Stream Grouping 消息流组.Wor ...
- Storm概念学习系列之storm流程图
把stream当做一列火车, tuple当做车厢,spout当做始发站,bolt当做是中间站点!!! 见 Storm概念学习系列之Spout数据源 Storm概念学习系列之Topology拓扑 Sto ...
- Storm概念学习系列之Worker、Task、Executor三者之间的关系
不多说,直接上干货! Worker.Task.Executor三者之间的关系 Storm集群中的一个物理节点启动一个或者多个Worker进程,集群的Topology都是通过这些Worker进程运行的. ...
- Storm概念学习系列之storm的雪崩
不多说,直接上干货! Storm的雪崩问题的解决办法1: Storm概念学习系列之并行度与如何提高storm的并行度 Storm的雪崩问题的解决办法2:
- Storm概念学习系列之Topology拓扑
不多说,直接上干货! Hadoop 上运行的是 MapReduce 作业,而在 Storm 上运行的是拓扑 Topology,这两者之间是非常不同的.一个关键的区别是:一个MapReduce 作业 ...
- Storm概念学习系列 之数据流模型、Storm数据流模型
不多说,直接上干货! 数据流模型 数据流模型是由数据流.数据处理任务.数据节点.数据处理任务实例等构成的一种数据模型.本节将介绍的数据流模型如图1所示. 分布式流处理系统由多个数据处理节点(node) ...
- Storm概念学习系列之Blot消息处理者
不多说,直接上干货! Bolt消息处理者 认识了消息源Spout和消息的数据存储元组Tuple,接下来了解消息的处理者Bolt.Bolt是接收Spout发出元组Tuple后处理数据的组件,所有的消息处 ...
- Storm概念学习系列之Spout数据源
不多说,直接上干货! Spout 数据源 消息源Spout是Storm的Topology中的消息生产者(即Tuple的创造者). Spout 介绍 1. Spout 的结构 Spout 是 Storm ...
- Storm概念学习系列之storm的功能和三大应用
不多说,直接上干货! storm的功能 Storm 有许多应用领域:实时分析.在线机器学习.持续计算.分布式 RPC(远过程调用协议,一种通过网络从远程计算机程序上请求服务). ETL(Extract ...
随机推荐
- 四 Synchronized
首先,一个问题:一个boolean成员变量,一个方法赋值,一个方法读值,多线程环境下,需要同步吗? 如果用同步的话,读也要用synchroized修饰,因为可见性的问题 需要同步,或者用volatil ...
- RS-485收发的零延时转换电路
转自:http://www.dzsc.com/data/html/2007-5-28/41097.html RS-485是一种基于差分信号传送的串行通信链路层协议.它解决了RS-232协议传输距离太近 ...
- Tiny4412 LED 硬件服务
1.Android系统中启动框架 2.首先实现驱动程序 #include <linux/kernel.h> #include <linux/module.h> #include ...
- js中的Number方法
1.Number.toExponential(fractionDigits) 把number转换成一个指数形式的字符串.可选参数控制其小数点后的数字位数.它必须在0~20之间. 例如: documen ...
- mysql查询语句in和exists二者的区别和性能影响
mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询.一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的 ...
- 【Java】Java程序员面试宝典(第三版)第5章----Java程序设计基本概念
1.static静态变量,在次级作用域也可以被修改. 2.k++ + k++.第一个自加实际上只有在与计算+k++时补增.详情P36的题目. 3.Java数据类型从低到高分为(byte short c ...
- Java探索之旅(1)——概述与控制台输入
使用的课本: Java语言程序设计(基础篇)----西电 李娜(译) 原著: Introduction to Java Progrmming(Eighth Edition) -----Y.Daniel ...
- CountDownLatch分析
1 什么是CountDownLatch呢? 先看看官网的定义 :一种同步帮助,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成. 现在由我来解释什么是CountDownLatch吧:比如说我 ...
- C++中的友元小结
我们知道,在一个类总可以有公有的(public)成员和私有的(private)成员.在类外可以访问公用成员,只有本类中的函数可以访问本类的私有成员. 现在,我们学习一种新的情况--友元. 在C++中, ...
- 关于 char 和 unsigned char 的区别
首先卖个关子: 为什么网络编程中的字符定义一般都为无符号的字符? char buf[16] = {0}; unsigned char ubuf[16] = { 0 }; 上面两个定义的区别是: ...