Hadoop(初始Hadoop)
Hadoop核心组件
1、Hadoop生态系统

Hadoop具有以下特性:
方便:Hadoop运行在由一般商用机器构成的大型集群上,或者云计算服务上
健壮:Hadoop致力于在一般商用硬件上运行,其架构假设硬件会频繁失效,Hadoop可以从容地处理大多数此类故障。
可扩展:Hadoop通过增加集群节点,可以线性地扩展以处理更大的数据集。
目前应用Hadoop最多的领域有:
1) 搜索引擎,Doug Cutting设计Hadoop的初衷,就是为了针对大规模的网页快速建立索引。
2) 大数据存储,利用Hadoop的分布式存储能力,例如数据备份、数据仓库等。
3) 大数据处理,利用Hadoop的分布式处理能力,例如数据挖掘、数据分析等
2、Hadoop主要的三大组件(HDFS,MapReduce,YARN)
Hadoop的三大框架也被誉为三驾马车。源头主要是来源于Goole公司的的三篇论文中的GFS、MapReduce和BigTable,而这三个组件是用C来编写的。而Hadoop中的HDFS,MapReduce,Yarn是用Java来编写的。
1. HDFS分布式文件存储
用途:存储海量数据(分布式)
是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。

Client:切分文件;访问HDFS分布式文件系统;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。(与DataNode交互时采用就近原则)
NameNode:Master主节点,主要用途是管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。(存的是整个系统的元数据如:文件名,文件目录结构,文件属性<生成时间,副本数(默认为3),文件权限>以及每个文件的块列表和块所在的DataNode等) ## NameNode把数据分2部分进行存储。1.存放在内存中。2. NameNode服务重启后会在本地生成fsimage和fsedits文件,当内存中的数据丢失时就会自动到这2个文件中读取数据。
DataNode:Slave从节点,存储实际的数据,汇报存储信息给NameNode。(在本地文件系统存储文件数据块及块数据的校验和)
Secondary NameNode:辅助NameNode,分担其工作量,每隔一段时间获取HDFS元数据快照;定期合并fsimage和fsedits文件,推送给NameNode;紧急情况下,可辅助恢复NameNode。但Secondary NameNode并非NameNode的热备。
2. MapReduce编程模型
用途:处理海量数据 TB级别(主要用于对数据进行分布式计算)
(1)Map () : 把大的数据集拆分成若干个小的数据集。并对于每个数据集来进行逻辑业务处理。
(2)Reduce () :把每个小数据集中的处理结果合并起来。(Reduce可以不只1个)
Mapreduce处理流程,以wordCount为例:
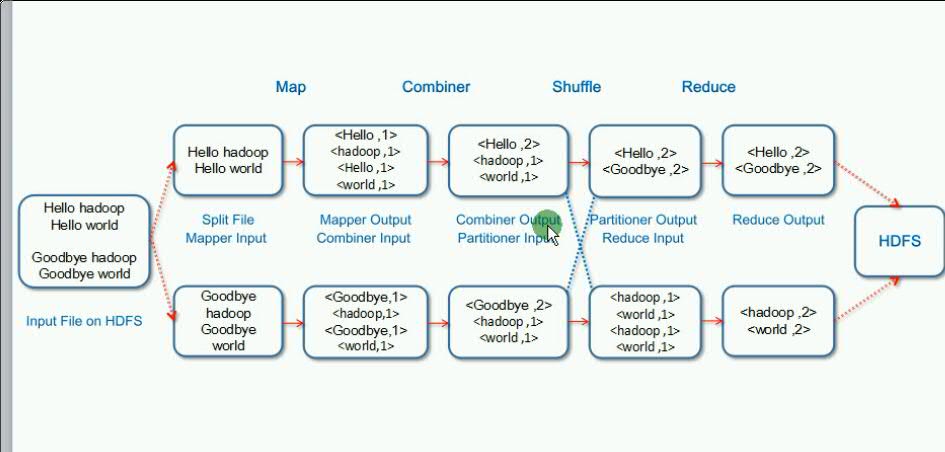
MapReduce也叫离线计算框架。流程可参考上图。下面是我个人理解的计算流程
input --> Map() --> shuffle -->Reduce () --> Output
(1) input阶段把数据进行拆分传给map任务,进行处理
(2) Map 接受数据并行处理数据
(3)Shuffle连接Map跟Reduce两个阶段
Maptask将数据写入磁盘
Reduce通过网络从每个map上读取一份数据
(4) Reduce最终对Map的处理结果作一个汇总
详细博客请参考:
http://www.cnblogs.com/hadoop-dev/p/5894911.html
3. YARN
用途:分布式资源管理框架
(1)管理整个集群中的资源
(2)分配调度集群中的资源
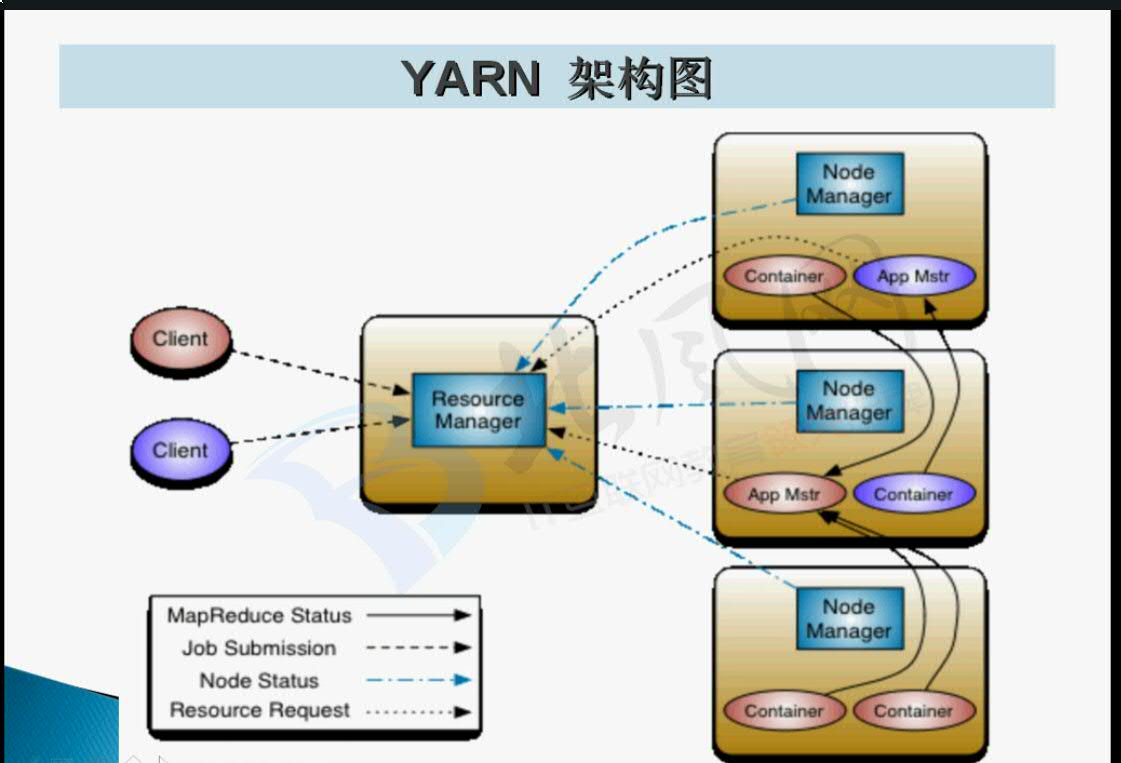
ResourceManager:整个集群中的资源管理及调度由ResourceManager来负责
NodeManager:每一台机器上资源的管理由NodeManager来负责
YARN的流程描述:
Client (提交任务)--》 ResourceManager (给每个任务分配一个应用管理者) --》 ApplicationMaster(分析每个Map任务分配需要的资源,划分任务并向ResourceManager进行申请) --》 ResourceManager (分配申请的资源后给每个节点的NodeManager,已容器的形式) --》NodeManager中的Container (每个Map,reduce任务都是在各个机器中的Container中运行的)--》汇总给ApplicationMaster --》最终汇报给ResourceManager
ApplicationMaster主要负责向ResourceManager上申请资源,分配资源(向Nodemanager),调度以及监控各个NodeManager上的Container处理Map,Reduce的状态及容错
Container主要是负责各自map,reduce的资源分配调度管理,并把结果汇报给applicationManager最终反馈给ResourceManager.
详细信息请参考下面博客:
http://blog.csdn.net/liuwenbo0920/article/details/43304243
3、Hadoop生态系统回顾

1. 元数据
数据库 --》通过Sqoop框架把数据存储到HDFS上
日志文件 --》通过Flume框架把数据存储到HDFS上
2. HDFS
YARN
MapReduce -->Hive :可以把数据跑在YARN上。但是因为MapReduce不是很好编写,因此通过基于SQL语句的Hive框架来对数据进行并行处理。Pig也是一种并行处理数据的框架。
Spark --》同样也是对map,reduce任务进行并行处理。因为Spark是把数据存放到内存中因此效率会更高。但是内存中的数据容易丢失同样风险性也高。
HBase (对上亿级别的数据查询,可以达到秒级别处理)
HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
数据模型:Schema-->Table-->Column Family-->Column-->RowKey-->TimeStamp-->Value
3. Oozie
Oozie是管理Hadoop作业的工作流调度系统。Oozie定义了控制流节点和动作节点。Oozie实现的功能:
(1)Workflow:顺序执行流程节点;
(2)Coordinator:定时触发workflow;
(3)Bundle Job:绑定多个Coordinator。
更加详细内容请参照:http://www.cnblogs.com/ilinuxer/p/6804339.html
4. ClouderManager
集群大了对数据可以很好的进行一个集中的部署,管理,分析,同步的作用。
5. zookeeper
对于分布式的组件,有些配置需要配。以及HA高可用性也需要部署,就通过Zookeeper框架来完成
6. Hue
对于以上的框架每个都由自己的管理页面。为了更方便我们的管理,可以通过Hue框架集中管理各个框架中的页面。
Hadoop(初始Hadoop)的更多相关文章
- Hadoop学习------Hadoop安装方式之(二):伪分布部署
要想发挥Hadoop分布式.并行处理的优势,还须以分布式模式来部署运行Hadoop.单机模式是指Hadoop在单个节点上以单个进程的方式运行,伪分布模式是指在单个节点上运行NameNode.DataN ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- Hadoop: Hadoop Cluster配置文件
Hadoop配置文件 Hadoop的配置文件: 只读的默认配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml 和 mapred-defa ...
- [Linux][Hadoop] 将hadoop跑起来
前面安装过程待补充,安装完成hadoop安装之后,开始执行相关命令,让hadoop跑起来 使用命令启动所有服务: hadoop@ubuntu:/usr/local/gz/hadoop-$ ./sb ...
- Hadoop:搭建hadoop集群
操作系统环境准备: 准备几台服务器(我这里是三台虚拟机): linux ubuntu 14.04 server x64(下载地址:http://releases.ubuntu.com/14.04.2/ ...
- [Hadoop 周边] Hadoop资料收集【转】
原文网址: http://www.iteblog.com/archives/851 最直接的学习参考网站当然是官网啦: http://hadoop.apache.org/ Hadoop http:// ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
随机推荐
- <Android 基础(七)> DrawerLayout and NavigationView
介绍 DrawerLayout是Support Library包中实现了侧滑菜单效果的控件 android.support.v4.widget.DrawerLayout NavigationView是 ...
- 从刷票了解如何获得客户端IP
我的个人博客,源地址:http://www.woniubi.cn/get_client_ip/ 前两个星期帮一个朋友的亲戚的孩子刷票,谁让咱们是程序员呢.这当中也遇到过重装系统,除灰尘,淘宝购物,盗Q ...
- CAD出现向程序发送命令时出现问题提示解决方法分享
大家有没有遇到在使用cad打开图纸的时候提示向程序发送命令时出现错误的情况呢,如果你在使用cad的时候出现了这个提示,是由于软件的兼容性出现了问题,那么该怎么办呢,下面小编就给大家带来cad打开图纸提 ...
- Tensorflow ValueError: Protocol message RewriterConfig has no "layout_optimizer" field
I changed models/research/object_detection/exporter.py line 71/72 from: rewrite_options = rewriter_c ...
- 在你的andorid设备上运行netcore (Linux Deploy)
最近注意到.net core 的新版本已经开始支持ARM 平台的CPU, 特意去Linux Deploy 中尝试了一下,真的可以运行 Welcome to Ubuntu 16.04 LTS (GNU/ ...
- iOS 有些库只能在真机上运行,不能在模拟器上运行的解决方式
在开发中,多少肯定会用到第三方的东西,或许大家也和我一样遇到到这样的情况,有些库正好适合自己的需求,但是这个库却只支持真机上运行,在模拟器上编译却不通过, 一般情况下,.a静态包,你刚刚导入的时候,不 ...
- python 3+djanjo 2.0.7简单学习(一)
1.安装django pip install django 我这里已经安装过了 整个目录结构如下: votes : migrations : __init__.py : admin.py : apps ...
- 关于IDataReader.GetSchemaTable的一些事情
http://stackoverflow.com/questions/1574492/how-does-getschematable-work The implementation of IDataR ...
- 关于Linux部分版本无法安装Chrome的问题
在想要yum安装Chrome浏览器后发现安装没有相应的包,在查询后得知Chrome已经对Redhat和Centos等部分版本停止支持, 所以这些新版的系统中直接安装就显得有些困难了,那么从网上找到了一 ...
- 【Java-POJO-设计模式】JavaEE中的POJO与设计模式中多态继承的冲突
最近看<重构>谈到利用OO的多态来优化 if else 和 switch 分支语句,但是我发现OO语法中的多态在使用框架的JavaEE中是无法实践的.对此,我感到十分的疑惑,加之之前项目中 ...