[大牛翻译系列]Hadoop(21)附录D.1 优化后的重分区框架
附录D.1 优化后的重分区框架
Hadoop社区连接包需要将每个键的所有值都读取到内存中。如何才能在reduce端的连接减少内存开销呢?本文提供的优化中,只需要缓存较小的数据集,然后在连接中遍历较大数据集中的数据。这个方法中还包括针对map的输出数据的次排序,那么reducer先接收到较小的数据集,然后接收到较大的数据集。图D.1是这个过程的流程图。

图D.2是实现的类图。类图中包含两个部分,一个通用框架和一些类的实现样例。
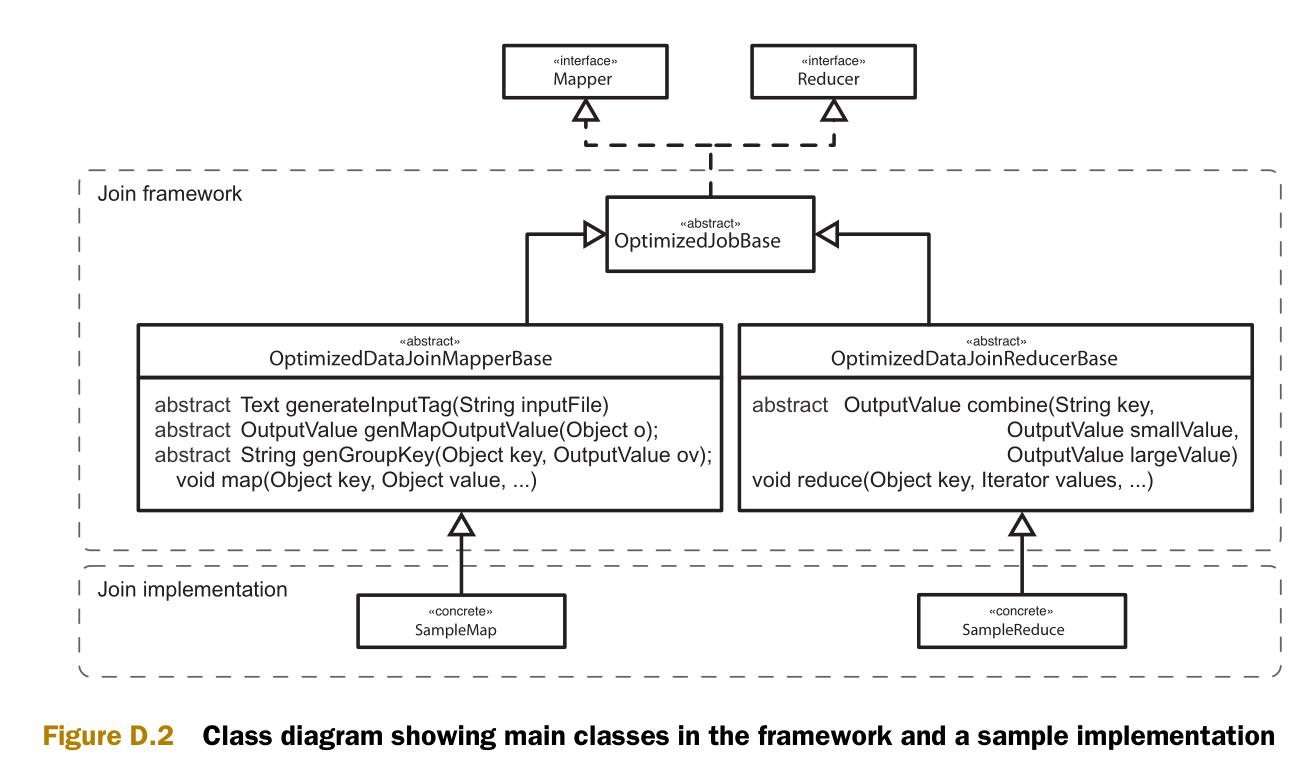
连接框架
我们以和Hadoop社区连接包的近似的风格编写连接的代码。目标是创建可以处理任意数据集的通用重分区机制。为简洁起见,我们重点说明主要部分。
首先是OptimizedDataJoinMapperBase类。这个类的作用是辨认出较小的数据集,并生成输出键和输出值。Configure方法在mapper创建时被调用。Configure方法的作用之一是标识每一个数据集,让reducer可以区分数据的源数据集。另一个作用是辨认当前的输入数据是否是较小的数据集。
protected abstract Text generateInputTag(String inputFile);
protected abstract boolean isInputSmaller(String inputFile);
public void configure(JobConf job) {
this.inputFile = job.get("map.input.file");
this.inputTag = generateInputTag(this.inputFile);
if(isInputSmaller(this.inputFile)) {
smaller = new BooleanWritable(true);
outputKey.setOrder(0);
} else {
smaller = new BooleanWritable(false);
outputKey.setOrder(1);
}
}
Map方法首先调用自定义的方法 (generateTaggedMapOutput) 来生成OutputValue对象。这个对象包含了在连接中需要使用的值(也可能包含了最终输出的值),和一个标识较大或较小数据集的布尔值。如果map方法可以调用自定义的方法 (generateGroupKey) 来得到可以在连接中使用的键,那么这个键就作为map的输出键。
protected abstract OptimizedTaggedMapOutput generateTaggedMapOutput(Object value); protected abstract String generateGroupKey(Object key, OptimizedTaggedMapOutput aRecord); public void map(Object key, Object value, OutputCollector output, Reporter reporter)
throws IOException { OptimizedTaggedMapOutput aRecord = generateTaggedMapOutput(value); if (aRecord == null) {
return;
} aRecord.setSmaller(smaller);
String groupKey = generateGroupKey(aRecord); if (groupKey == null) {
return;
} outputKey.setKey(groupKey);
output.collect(outputKey, aRecord);
}
图D.3 说明了map输出的组合键(composite 可以)和组合值。次排序将会根据连接键(join key)进行分区,并用整个组合键来进行排序。组合键包括一个标识源数据集(较大或较小)的整形值,因此可以根据这个整形值来保证较小源数据集的值先于较大源数据的值被reduce接收。

下一步是深入reduce。此前已经可以保证较小源数据集的值将会先于较大源数据集的值被接收。这里就可以将所有的较小源数据集的值放到缓存中。在开始接收较大源数据集的值的时候,就开始和缓存中的值做连接操作。
public void reduce(Object key, Iterator values, OutputCollector output, Reporter reporter)
throws IOException { CompositeKey k = (CompositeKey) key;
List<OptimizedTaggedMapOutput> smaller = new ArrayList<OptimizedTaggedMapOutput>(); while (values.hasNext()) {
Object value = values.next();
OptimizedTaggedMapOutput cloned =((OptimizedTaggedMapOutput) value).clone(job); if (cloned.isSmaller().get()) {
smaller.add(cloned);
} else {
joinAndCollect(k, smaller, cloned, output, reporter);
}
}
}
方法joinAndCollect包含了两个数据集的值,并输出它们。
protected abstract OptimizedTaggedMapOutput combine(
String key,
OptimizedTaggedMapOutput value1,
OptimizedTaggedMapOutput value2); private void joinAndCollect(CompositeKey key,
List<OptimizedTaggedMapOutput> smaller,
OptimizedTaggedMapOutput value,
OutputCollector output,
Reporter reporter)
throws IOException { if (smaller.size() < 1) {
OptimizedTaggedMapOutput combined = combine(key.getKey(), null, value);
collect(key, combined, output, reporter);
} else {
for (OptimizedTaggedMapOutput small : smaller) {
OptimizedTaggedMapOutput combined = combine(key.getKey(), small, value);
collect(key, combined, output, reporter);
}
}
}
这些就是这个框架的主要内容。第4章介绍能如何使用这个框架。
[大牛翻译系列]Hadoop(21)附录D.1 优化后的重分区框架的更多相关文章
- [大牛翻译系列]Hadoop 翻译文章索引
原书章节 原书章节题目 翻译文章序号 翻译文章题目 链接 4.1 Joining Hadoop(1) MapReduce 连接:重分区连接(Repartition join) http://www.c ...
- [大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)
4.1 连接(Join) 连接是关系运算,可以用于合并关系(relation).对于数据库中的表连接操作,可能已经广为人知了.在MapReduce中,连接可以用于合并两个或多个数据集.例如,用户基本信 ...
- [大牛翻译系列]Hadoop(5)MapReduce 排序:次排序(Secondary sort)
4.2 排序(SORT) 在MapReduce中,排序的目的有两个: MapReduce可以通过排序将Map输出的键分组.然后每组键调用一次reduce. 在某些需要排序的特定场景中,用户可以将作业( ...
- [大牛翻译系列]Hadoop(3)MapReduce 连接:半连接(Semi-join)
4.1.3 半连接(Semi-join) 假设一个场景,需要连接两个很大的数据集,例如,用户日志和OLTP的用户数据.任何一个数据集都不是足够小到可以缓存在map作业的内存中.这样看来,似乎就不能使用 ...
- [大牛翻译系列]Hadoop(2)MapReduce 连接:复制连接(Replication join)
4.1.2 复制连接(Replication join) 复制连接是map端的连接.复制连接得名于它的具体实现:连接中最小的数据集将会被复制到所有的map主机节点.复制连接有一个假设前提:在被连接的数 ...
- [大牛翻译系列]Hadoop(22)附录D.2 复制连接框架
附录D.2 复制连接框架 复制连接是map端连接,得名于它的具体实现:连接中最小的数据集将会被复制到所有的map主机节点.复制连接的实现非常直接明了.更具体的内容可以参考Chunk Lam的<H ...
- [大牛翻译系列]Hadoop(20)附录A.10 压缩格式LZOP编译安装配置
附录A.10 LZOP LZOP是一种压缩解码器,在MapReduce中可以支持可分块的压缩.第5章中有一节介绍了如何应用LZOP.在这一节中,将介绍如何编译LZOP,在集群做相应配置. A.10.1 ...
- [大牛翻译系列]Hadoop(19)MapReduce 文件处理:基于压缩的高效存储(二)
5.2 基于压缩的高效存储(续) (仅包括技术27) 技术27 在MapReduce,Hive和Pig中使用可分块的LZOP 如果一个文本文件即使经过压缩后仍然比HDFS的块的大小要大,就需要考虑选择 ...
- [大牛翻译系列]Hadoop(18)MapReduce 文件处理:基于压缩的高效存储(一)
5.2 基于压缩的高效存储 (仅包括技术25,和技术26) 数据压缩可以减小数据的大小,节约空间,提高数据传输的效率.在处理文件中,压缩很重要.在处理Hadoop的文件时,更是如此.为了让Hadoop ...
随机推荐
- “ArcGIS数据应用和地图打印输出
中国科学院计算技术研究所教育中心 关于开展“ArcGIS数据应用和地图打印输出” 培训班的通知 各相关单位: 随着信息化.网络化.数字化向纵深发展,互联网与空间地理信息系统相互交织,数字地球.“智慧地 ...
- 【Java/Android性能优化1】Android性能调优
本文参考:http://www.trinea.cn/android/android-performance-demo/ 本文主要分享自己在appstore项目中的性能调优点,包括同步改异步.缓存.La ...
- 使用MRUnit,Mockito和PowerMock进行Hadoop MapReduce作业的单元测试
0.preliminary 环境搭建 Setup development environment Download the latest version of MRUnit jar from Apac ...
- Javascript函数(定义、传值、重载)
Javascript 函数的定义的方式有不止一种. 第一种方式: function fn1(){ alert(typeof fn1); alert(“fn1”); } 在调用的时候直接就可以fu1() ...
- sql语句大全~·留着有用
一.基础 1.说明:创建数据库CREATE DATABASE database-name 2.说明:删除数据库drop database dbname3.说明:备份sql server--- 创建 备 ...
- javascript中Math ceil(),floor(),round()三个函数的对比
Math.ceil()执行的是向上舍入 Math.floor()执行向下舍入 Math.round()执行标准舍入 一下是一些补充: ceil():将小数部分一律向整数部分进位. 如: Math.ce ...
- 剑指Offer30 从1到n整数出现1的个数
/************************************************************************* > File Name: 30_NumerO ...
- hdu-5587 Array(回溯)
题目链接: Array Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others) P ...
- Matplotlib之无GUI时的解决办法
需添加: import matplotlib as mpl mpl.use('Agg') 而且必须添加在import matplotlib.pyplot之前,否则无效
- 锋利的jQuery第2版学习笔记8~11章
第8章,用jQuery打造个性网站 网站结构 文件结构 images文件夹用于存放将要用到的图片 styles文件夹用于存放CSS样式表,个人更倾向于使用CSS文件夹 scripts文件夹用于存放jQ ...