tf-idf sklearn
第一步:语料转化为词袋向量
step 1. 声明一个向量化工具vectorizer;
本文使用的是CountVectorizer,默认情况下,CountVectorizer仅统计长度超过两个字符的词,但是在短文本中任何一个字都可能十分重要,比如“去/到”等,所以要想让CountVectorizer也支持单字符的词,需要加上参数token_pattern='\\b\\w+\\b'。
step 2. 根据语料集统计词袋(fit);
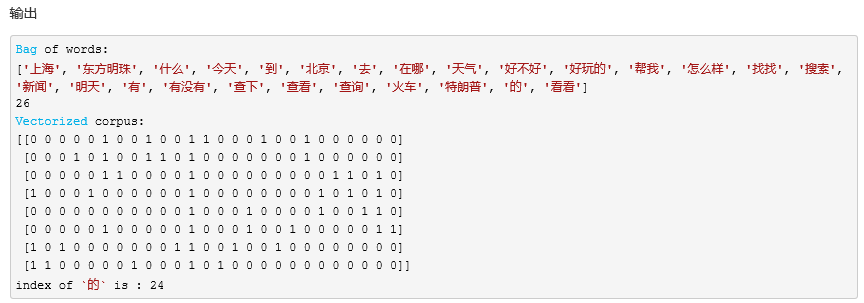
step 3. 打印语料集的词袋信息;
step 4. 将语料集转化为词袋向量(transform);
step 5. 还可以查看每个词在词袋中的索引。
代码:

step 1中: min_df、max_df 表示一个阈值,低于、超过这个阈值的词汇讲被忽略
from sklearn.feature_extraction.text import CountVectorizer
# step 1
vectoerizer = CountVectorizer(min_df=1, max_df=1.0, token_pattern='\\b\\w+\\b')
# step 2
vectoerizer.fit(corpus)
# step 3
bag_of_words = vectoerizer.get_feature_names()
print("Bag of words:")
print(bag_of_words)
print(len(bag_of_words))
# step 4
X = vectoerizer.transform(corpus)
print("Vectorized corpus:")
print(X.toarray())
# step 5
print("index of `的` is : {}".format(vectoerizer.vocabulary_.get('的')))
第二步:根据词袋向量统计TF-IDF
step 1. 声明一个TF-IDF转化器(TfidfTransformer);
step 2. 根据语料集的词袋向量计算TF-IDF(fit);
step 3. 打印TF-IDF信息:比如结合词袋信息,可以查看每个词的TF-IDF值;
step 4. 将语料集的词袋向量表示转换为TF-IDF向量表示;
from sklearn.feature_extraction.text import TfidfTransformer
# step 1
tfidf_transformer = TfidfTransformer()
# step 2
tfidf_transformer.fit(X.toarray())
# step 3
for idx, word in enumerate(vectoerizer.get_feature_names()):
print("{}\t{}".format(word, tfidf_transformer.idf_[idx]))
# step 4
tfidf = tfidf_transformer.transform(X)
print(tfidf.toarray())
输出
上海 1.8109302162163288
东方明珠 2.504077396776274
什么 2.504077396776274
今天 2.504077396776274
到 2.504077396776274
北京 1.587786664902119
去 2.504077396776274
在哪 2.504077396776274
天气 2.09861228866811
好不好 2.504077396776274
好玩的 2.504077396776274
帮我 1.0
怎么样 2.504077396776274
找找 2.504077396776274
搜索 2.504077396776274
新闻 2.09861228866811
明天 2.504077396776274
有 2.504077396776274
有没有 2.504077396776274
查下 2.09861228866811
查看 2.09861228866811
查询 2.504077396776274
火车 2.09861228866811
特朗普 2.504077396776274
的 1.587786664902119
看看 2.504077396776274
[[0. 0. 0. 0. 0. 0.3183848
0. 0. 0.42081614 0. 0. 0.20052115
0.50212047 0. 0. 0. 0.50212047 0.
0. 0.42081614 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0.50212047 0. 0.3183848
0. 0. 0.42081614 0.50212047 0. 0.20052115
0. 0. 0. 0. 0. 0.
0. 0.42081614 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.33116919
0.52228256 0. 0. 0. 0. 0.20857285
0. 0. 0. 0. 0. 0.
0. 0. 0. 0.52228256 0.43771355 0.
0.33116919 0. ]
[0.38715525 0. 0. 0. 0.53534183 0.
0. 0. 0. 0. 0. 0.21378805
0. 0. 0. 0. 0. 0.
0. 0. 0.44865824 0. 0.44865824 0.
0.33944982 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.23187059
0. 0. 0. 0.48660646 0. 0.
0. 0. 0.48660646 0. 0. 0.5806219
0.36816103 0. ]
[0. 0. 0. 0. 0. 0.33116919
0. 0. 0. 0. 0. 0.20857285
0. 0. 0. 0.43771355 0. 0.
0.52228256 0. 0. 0. 0. 0.
0.33116919 0.52228256]
[0.33420711 0. 0.4621274 0. 0. 0.
0. 0. 0. 0. 0.4621274 0.18454996
0. 0. 0.4621274 0. 0. 0.4621274
0. 0. 0. 0. 0. 0.
0. 0. ]
[0.37686288 0.52110999 0. 0. 0. 0.
0. 0.52110999 0. 0. 0. 0.20810458
0. 0.52110999 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]]
出处: http://www.cnblogs.com/CheeseZH/
上面的sklearn 的函数介绍:
CountVectorizer 实例介绍:

tf-idf sklearn的更多相关文章
- tf idf公式及sklearn中TfidfVectorizer
在文本挖掘预处理之向量化与Hash Trick中我们讲到在文本挖掘的预处理中,向量化之后一般都伴随着TF-IDF的处理,那么什么是TF-IDF,为什么一般我们要加这一步预处理呢?这里就对TF-IDF的 ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 使用solr的函数查询,并获取tf*idf值
1. 使用函数df(field,keyword) 和idf(field,keyword). http://118.85.207.11:11100/solr/mobile/select?q={!func ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
随机推荐
- java算法 第七届 蓝桥杯B组(题+答案) 9.取球博弈
9.取球博弈 (程序设计) 两个人玩取球的游戏.一共有N个球,每人轮流取球,每次可取集合{n1,n2,n3}中的任何一个数目.如果无法继续取球,则游戏结束.此时,持有奇数个球的一方获胜.如果两人都是 ...
- C#使用NPOI导出excel设置单元格背景颜色
ICellStyle cellStyle = workbook.CreateCellStyle(); cellStyle.FillPattern = FillPattern.SolidForegrou ...
- solr的简单部署:在tomcat中启动slor
1,首先要下载solr 途径1: 官网网址: http://lucene.apache.org/ 与Lucene的官网是一个 途径2: 下载历史版本的网址: http://archive.apache ...
- 【codevs3160】 LCS 【后缀自动机】
题意 给出两个字符串,求它们的最长公共子串. 分析 后缀自动机的基础应用. 比如两个字符串s1和s2,我们把s1建为SAM,然后根据s2跑,找出s2每个前缀的最长公共后缀. 我们可以理解为,当向尾部增 ...
- Appium+python自动化-Remote远程控制
前言 在第三篇启动app的时候有这样一行代码driver = webdriver.Remote('http://192.168.1.1:4723/wd/hub', desired_caps),很多小伙 ...
- ubuntu mysql导出数据库及数据
mysqldump -u root -p mask_rcnn_realsense > /home/luo/mask_rcnn_realsense1.sql
- 75-扩展GCD-时间复杂度
扩展gcd-时间复杂性 题目内容: 计算循环语句的执行频次 for(i=A; i!=B ; i+=C) x+=1; 其中A,B,C,i都是k位无符号整数. 输入描述 A B C k, 其中0<k ...
- Linux hostname主机名配置文件与文件 /etc/hosts解析(copy来的,原作者看到了别打我)
1.关于/etc/host,主机名和IP配置文件 Hosts - The static table lookup for host name(主机名查询静态表) hosts文件是Linux系统中一个负 ...
- [Jenkins] 执行SoapUI的task,里面包含多个Project,发出的报告也要求包含多个Project,设置邮件内容为HTML+CSS
执行SoapUI的task,里面包含多个Project,发出的报告也要求包含多个Project,设置邮件内容为HTML+CSS 如何保证样式在邮件内容中不丢失 <link title=" ...
- [SoapUI] SoapUI可以做到些什么?功能有多强大?
SoapUI. The Swiss-Army Knife of Testing. Whether you’re a tester, developer, business analyst, or ma ...