hadoop入门手册4:Hadoop【2.7.1】初级入门之命令:文件系统shell1
问题导读
1.Hadoop文件系统shell与Linux shell有哪些相似之处?
2.如何改变文件所属组?
3.如何改变hdfs的文件权限?
4.如何查找hdfs文件,并且不区分大小写?

概述
文件系统 (FS) shell 包括各种类似的命令直接与 Hadoop Distributed File System (HDFS)交互。hadoop也支持其它文件系统,比如 Local FS, HFTP FS, S3 FS, 和 其它的. FS shell被下面调用:
|
1
|
bin/hadoop fs <args> |
所有的FS shell命令带有URIs路径参数。The URI 格式是://authority/path。对 HDFS文件系统,scheme是hdfs。其中scheme和 authority参数都是可选的
如果没有指定,在文件中使用默认scheme.一个hdfs文件或则目录比如 /parent/child,可以是 hdfs://namenodehost/parent/child 或则简化为/parent/child(默认配置设置成指向hdfs://namenodehost).大多数FS shell命令对应 Unix 命令.每个命令都有不同的描述。将错误信息发送到标准错误输出和输出发送到stdout。
appendToFile【添加文件】
用法: hadoop fs -appendToFile <localsrc> ... <dst>添加单个src,或则多个srcs从本地文件系统到目标文件系统。从标准输入读取并追加到目标文件系统。
- hadoop fs -appendToFile localfile /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile1 localfile2 /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile hdfs://nn.example.com/hadoop/hadoopfile
- hadoop fs -appendToFile - hdfs://nn.example.com/hadoop/hadoopfile Reads the input from stdin.
返回代码:
返回 0成功返回 1 错误
cat
用法: hadoop fs -cat URI [URI ...]
将路径指定文件的内容输出到stdout
例子:
- hadoop fs -cat hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -cat file:///file3 /user/hadoop/file4
返回代码:
返回 0成功返回 1 错误
checksum
用法: hadoop fs -checksum URI
返回 checksum 文件信息
例子:
- hadoop fs -checksum hdfs://nn1.example.com/file1
- hadoop fs -checksum file:///etc/hosts
chgrp
用法: hadoop fs -chgrp [-R] GROUP URI [URI ...]
改变文件所属组. 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
- 使用-R 将使改变在目录结构下递归进行
chmod
用法: hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI ...]
更改文件的权限. 使用-R 将使改变在目录结构下递归进行。 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
- 使用-R 将使改变在目录结构下递归进行。
chown
用法: hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
更改文件的所有者. 使用-R 将使改变在目录结构下递归进行。 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
- 使用-R 将使改变在目录结构下递归进行。
copyFromLocal
用法: hadoop fs -copyFromLocal <localsrc> URI
类似put命令, 需要指出的是这个限制是本地文件
选项:
- -f 选项会重写已存在的目标文件
copyToLocal
用法: hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
与get命令类似, 除了限定目标路径是一个本地文件外。
count
用法: hadoop fs -count [-q] [-h] [-v] <paths>统计目录个数,文件和目录下文件的大小。输出列:DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
【目录个数,文件个数,总大小,路径名称】
输出列带有 -count -q 是: QUOTA, REMAINING_QUATA, SPACE_QUOTA, REMAINING_SPACE_QUOTA, DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
【配置,其余指标,空间配额,剩余空间定额,目录个数,文件个数,总大小,路径名称】
The -h 选项,size可读模式.
The -v 选项显示一个标题行。
Example:
- hadoop fs -count hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -count -q hdfs://nn1.example.com/file1
- hadoop fs -count -q -h hdfs://nn1.example.com/file1
- hdfs dfs -count -q -h -v hdfs://nn1.example.com/file1
返回代码:
返回 0成功返回 1 错误
<ignore_js_op>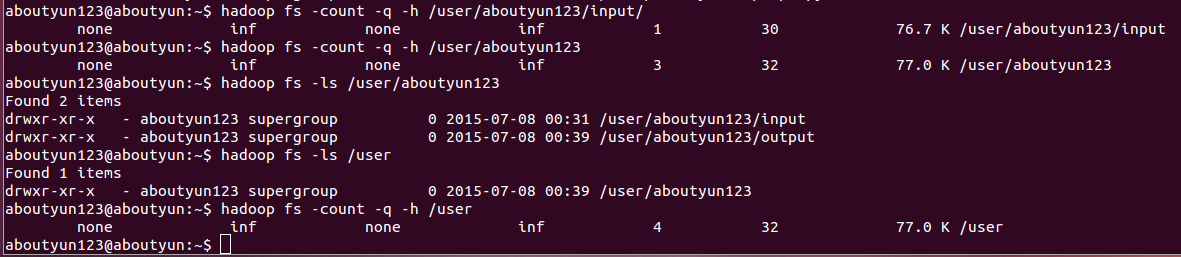
cp
用法: hadoop fs -cp [-f] [-p | -p[topax]] URI [URI ...] <dest>复制文件,这个命令允许复制多个文件到一个目录。
‘raw.*’ 命名空间扩展属性被保留
(1)源文件和目标文件支持他们(仅hdfs)
(2)所有的源文件和目标文件路径在 /.reserved/raw目录结构下。
决定是否使用 raw.*命名空间扩展属性依赖于-P选项
选项:
- -f 选项如果文件已经存在将会被重写.
- -p 选项保存文件属性 [topx] (timestamps, ownership, permission, ACL, XAttr). 如果指定 -p没有参数, 保存timestamps, ownership, permission. 如果指定 -pa, 保留权限 因为ACL是一个权限的超级组。确定是否保存raw命名空间属性取决于是否使用-p决定
例子:
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回代码:
返回 0成功返回 1 错误
createSnapshot
查看 HDFS Snapshots Guide.
deleteSnapshot
查看 HDFS Snapshots Guide.
df【查看还剩多少hdfs空间】
用法: hadoop fs -df [-h] URI [URI ...]
显示剩余空间
选项:
- -h 选项会让人更加易读 (比如 64.0m代替 67108864)
Example:
- hadoop dfs -df /user/hadoop/dir1
<ignore_js_op>
du
用法: hadoop fs -du [-s] [-h] URI [URI ...]显示给定目录的文件大小及包含的目录,如果只有文件只显示文件的大小
选项:
- -s 选项汇总文件的长度,而不是现实单个文件.
- -h 选项显示格式更加易读 (例如 64.0m代替67108864)
例子:
- hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://nn.example.com/user/hadoop/dir1
返回代码:
返回 0成功返回 1 错误
<ignore_js_op>
dus
用法: hadoop fs -dus <args>
显示统计文件长度
注意:这个命令已被启用, hadoop fs -du -s即可
expunge
用法: hadoop fs -expunge
清空垃圾回收站. 涉及 HDFS Architecture Guide 更多信息查看回收站特点
find
用法: hadoop fs -find <path> ... <expression> ...查找与指定表达式匹配的所有文件,并将选定的操作应用于它们。如果没有指定路径,则默认查找当前目录。如果没有指定表达式默认-print
下面主要表达式:
- -name 模式
-iname 模式
如果
值为TRUE如果文件基本名匹配模式使用标准的文件系统组合。如果使用-iname匹配不区分大小写。
- -print
-print0Always
值为TRUE. 当前路径被写至标准输出。如果使用 -print0 表达式, ASCII NULL 字符是追加的.
下面操作:
- expression -a expression
expression -and expression
expression expression
and运算符连接两个表达式,如果两个字表达式返回true,则返回true.由两个表达式的并置暗示,所以不需要明确指定。如果第一个失败,则不会应用第二个表达式。
例子:
hadoop fs -find / -name test -print
返回代码:
返回 0成功返回 1 错误
<ignore_js_op>
get
用法: hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>复制文件到本地文件。
复制文件到本地文件系统. 【CRC校验失败的文件复制带有-ignorecrc选项(如翻译有误欢迎指正)】
Files that fail the CRC check may be copied with the -ignorecrc option.
文件CRC可以复制使用CRC选项。
例子:
- hadoop fs -get /user/hadoop/file localfile
- hadoop fs -get hdfs://nn.example.com/user/hadoop/file localfile
返回代码:
返回 0成功返回 1 错误
相关内容
hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
hadoop入门手册2:hadoop【2.7.1】【多节点】集群配置【必知配置知识2】
hadoop入门手册3:Hadoop【2.7.1】初级入门之命令指南
hadoop入门手册4:Hadoop【2.7.1】初级入门之命令:文件系统shell1
hadoop入门手册5:Hadoop【2.7.1】初级入门之命令:文件系统shell2
hadoop2.X使用手册1:通过web端口查看主节点、slave1节点及集群运行状态
http://www.aboutyun.com/thread-7712-1-1.html
hadoop入门手册4:Hadoop【2.7.1】初级入门之命令:文件系统shell1的更多相关文章
- hadoop入门手册5:Hadoop【2.7.1】初级入门之命令:文件系统shell2
问题导读 1.改变hdfs文件的权限,需要修改哪个配置文件?2.获取一个文件的或则目录的权限,哪个命令可以实现?3.哪个命令可以实现设置访问控制列表(ACL)的文件和目录? 接上篇:Hadoop[2. ...
- hadoop入门手册3:Hadoop【2.7.1】初级入门之命令指南
问题导读1.hadoop daemonlog管理员命令的作用是什么?2.hadoop如何运行一个类,如何运行一个jar包?3.hadoop archive的作用是什么? 概述 hadoop命令被bin ...
- hadoop入门手册2:hadoop【2.7.1】【多节点】集群配置【必知配置知识2】
问题导读 1.如何实现检测NodeManagers健康?2.配置ssh互信的作用是什么?3.启动.停止hdfs有哪些方式? 上篇: hadoop[2.7.1][多节点]集群配置[必知配置知识1]htt ...
- hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
问题导读 1.说说你对集群配置的认识?2.集群配置的配置项你了解多少?3.下面内容让你对集群的配置有了什么新的认识? 目的 目的1:这个文档描述了如何安装配置hadoop集群,从几个节点到上千节点.为 ...
- Spark入门——什么是Hadoop,为什么是Spark?
#Spark入门#这个系列课程,是综合于我从2017年3月分到今年7月份为止学习并使用Spark的使用心得感悟,暂定于每周更新,以后可能会上传讲课视频和PPT,目前先在博客园把稿子打好.注意:这只是一 ...
- 大数据入门第五天——离线计算之hadoop(下)hadoop-shell与HDFS的JavaAPI入门
一.Hadoop Shell命令 既然有官方文档,那当然先找到官方文档的参考:http://hadoop.apache.org/docs/current/hadoop-project-dist/had ...
- Hadoop概念学习系列之Hadoop新手学习指导之入门需知(二十)
不多说,直接上干货! 零基础学习hadoop,没有想象的那么困难,也没有想象的那么容易.从一开始什么都不懂,到能够搭建集群,开发.整个过程,只要有Linux基础,虚拟机化和java基础,其实hadoo ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- Hadoop学习笔记—6.Hadoop Eclipse插件的使用
开篇:Hadoop是一个强大的并行软件开发框架,它可以让任务在分布式集群上并行处理,从而提高执行效率.但是,它也有一些缺点,如编码.调试Hadoop程序的难度较大,这样的缺点直接导致开发人员入门门槛高 ...
随机推荐
- centos7 VNC安装
root用户: yum install tigervnc-server .service vim /etc/systemd/system/vncserver@:.service .service vn ...
- 安装webpack命令环境
1.通过cnpm安装webpack命令环境,如图 2.安装完后查看webpack的版本,如图
- 三、nginx 编译参数
命令 --prefix=/usr/share/nginx # nginx 帮助目录 --sbin-path=/usr/sbin/nginx # nginx 执行命令 --modules-path=/u ...
- mysql 查看表信息
desc 表名; 查看表结构信息 show create table 表名; 查询建表详细信息 select COLUMN_NAME,COLUMN_TYPE,COLUMN_COMMENT from i ...
- Request库使用response.text返回乱码问题
我们日常使用Request库获取response.text,这种调用方式返回的text通常会有乱码显示: import requests res = requests.get("https: ...
- LR简单解析
- 一个不错的JavaScript解析浏览器路径方法
JavaScript中有时需要用到当前的请求路径等涉及到url的情况,正常情况下我们可以使用location对象来获取我们需要的信息,本文从另外一个途径来解决这个问题,而且更加巧妙 方法如下: fun ...
- 收集的几个好用的maven mirror
<mirrors> <mirror> <id>jboss-public-repository-group</id> <mirrorOf>ce ...
- lvs+keepalived+vsftp配置FTP服务器负载均衡
LVS+Keepalive 实现服务器的负载均衡高可用一.安装两台机器的安装是一样的,这里只记录一遍.1. 下载LVS+Keepalive 所需安装包http://www.keepalived.org ...
- TLS就是SSL的升级版+网络安全——一图看懂HTTPS建立过程——本质上就是引入第三方监管,web服务器需要先生成公钥和私钥,去CA申请,https通信时候浏览器会去CA校验CA证书的有效性
起初是因为HTTP在传输数据时使用的是明文(虽然说POST提交的数据时放在报体里看不到的,但是还是可以通过抓包工具窃取到)是不安全的,为了解决这一隐患网景公司推出了SSL安全套接字协议层,SSL是基于 ...