Python进行数据分析(一)初步学习 对时区进行计数
time_zones[:10]
Out[19]:
[u'America/New_York',
u'America/Denver',
u'America/New_York',
u'America/Sao_Paulo',
u'America/New_York',
u'America/New_York',
u'Europe/Warsaw',
u'',
u'',
u'']
接下来对时区进行计数,这里使用两种方法,一种使用Python标准库,另一个比较简(使用pandas)。
def get_counts(sequence):
counts = {}
for x in sequence:
if x in counts:
counts[x] += 1
else:
counts[x] = 1
return counts get_counts(time_zones[:10])
Out[21]:
{u'': 3,
u'America/Denver': 1,
u'America/New_York': 4,
u'America/Sao_Paulo': 1,
u'Europe/Warsaw': 1}
使用标准款,简洁版
from collections import defaultdict def get_counts2(sequence):
counts = defaultdict(int) # 所有的值均会被初始化为0
for x in sequence:
counts[x] += 1
return counts get_counts2(time_zones[:10])
Out[24]: defaultdict(<type 'int'>, {u'Europe/Warsaw': 1, u'America/Denver': 1, u'America/Sao_Paulo': 1, u'': 3, u'America/New_York': 4})
要它对时区进行处理,传入time_zones传入即可:
counts = get_counts(time_zones) counts['America/New_York']
Out[27]: 1251 len(time_zones)
Out[28]: 3440
得到前10位的时区及计数值:
def top_counts(count_dict, n = 10):
value_key_pairs = [(count,tz) for tz,count in count_dict.items()]
value_key_pairs.sort()
return value_key_pairs[-n:] # 得到倒数第n个数到最后 top_counts(counts)
Out[30]:
[(33, u'America/Sao_Paulo'),
(35, u'Europe/Madrid'),
(36, u'Pacific/Honolulu'),
(37, u'Asia/Tokyo'),
(74, u'Europe/London'),
(191, u'America/Denver'),
(382, u'America/Los_Angeles'),
(400, u'America/Chicago'),
(521, u''),
(1251, u'America/New_York')]
使用collection.Counter类,使这个任务变的简单:
from collections import Counter counts = Counter(time_zones) counts.most_common(10)
Out[33]:
[(u'America/New_York', 1251),
(u'', 521),
(u'America/Chicago', 400),
(u'America/Los_Angeles', 382),
(u'America/Denver', 191),
(u'Europe/London', 74),
(u'Asia/Tokyo', 37),
(u'Pacific/Honolulu', 36),
(u'Europe/Madrid', 35),
(u'America/Sao_Paulo', 33)]
DataFrame是pandas中最重要的数据结构,用于将数据表示为一个表格。从一组数据中创建DataFrame:
from pandas import DataFrame, Series import pandas as pd; import numpy as np frame = DataFrame(records) frame
Out[38]:
frame['tz'][:10]
Out[40]:
0 America/New_York
1 America/Denver
2 America/New_York
3 America/Sao_Paulo
4 America/New_York
5 America/New_York
6 Europe/Warsaw
7
8
9
Name: tz, dtype: object
这里frame的输出形式是摘要视图,主要用于较大的DataFrame对象。frame['tz']所返回的Series对象有一个value_counts方法,改方法可以让我们得到所需的信息:
tz_counts = frame['tz'].value_counts() tz_counts[:10]
Out[42]:
America/New_York 1251
521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
Europe/London 74
Asia/Tokyo 37
Pacific/Honolulu 36
Europe/Madrid 35
America/Sao_Paulo 33
dtype: int64
利用绘图库(matplotlib)为这段数据生成一张的图片。
为此,先给记录中未知或缺失的时区填上一个替代值。fillna函数可以替代缺失值(NA),而未知值(空字符串)则可通过 布尔型数组索引加以替换:
clean_tz = frame['tz'].fillna('Missing') # 替换缺失值(NA)
clean_tz[clean_tz == ''] = 'Unknown' # 未知值通过布尔型数组索引加以替换,注意这里的 clean_tz是 Series对象
tz_counts = clean_tz.value_counts()
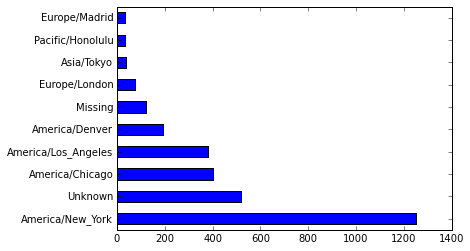
tz_counts[:10]
Out[46]:
America/New_York 1251
Unknown 521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
Missing 120
Europe/London 74
Asia/Tokyo 37
Pacific/Honolulu 36
Europe/Madrid 35
dtype: int64
tz_counts[:10].plot(kind='barh', rot=0)
Out[52]: <matplotlib.axes._subplots.AxesSubplot at 0xf6de430>
results = Series([x.split()[0] for x in frame.a.dropna()]) results[:5]
Out[65]:
0 Mozilla/5.0
1 GoogleMaps/RochesterNY
2 Mozilla/4.0
3 Mozilla/5.0
4 Mozilla/5.0
dtype: object results.value_counts()[:]
Out[66]:
Mozilla/5.0 2594
Mozilla/4.0 601
GoogleMaps/RochesterNY 121
Opera/9.80 34
TEST_INTERNET_AGENT 24
GoogleProducer 21
Mozilla/6.0 5
BlackBerry8520/5.0.0.681 4
dtype: int64
按Windows和非Windows用户对时区统计信息进行分解。
由于有agent缺失值,首先将他们从数据中移除:
cframe = frame[frame.a.notull()]
根据a值计算出各行是否是Windows:
根据时区和新得到的操作系统列表对数据进行分组
通过size对分组结果进行计数(类似上面value_counts()),并用unstack()对计数结果进行重塑:
operating_system = np.where(cframe['a'].str.contains('Windows'),
'Windows', 'Not Windows')
operating_system[:5]
Out[79]:
array(['Windows', 'Not Windows', 'Windows', 'Not Windows', 'Windows'],
dtype='|S11')
by_tz_os = cframe.groupby(['tz', operating_system])
by_tz_os
Out[81]: <pandas.core.groupby.DataFrameGroupBy object at 0x0F9C4D30>
agg_counts = by_tz_os.size().unstack().fillna(0) # 拆分列
agg_counts[:10]
Out[83]:
Not Windows Windows
tz
245 276
Africa/Cairo 0 3
Africa/Casablanca 0 1
Africa/Ceuta 0 2
Africa/Johannesburg 0 1
Africa/Lusaka 0 1
America/Anchorage 4 1
America/Argentina/Buenos_Aires 1 0
America/Argentina/Cordoba 0 1
America/Argentina/Mendoza 0 1
没有拆分列是这种效果(unstack):
Out[87]:
tz
Not Windows 245
Windows 276
Africa/Cairo Windows 3
Africa/Casablanca Windows 1
Africa/Ceuta Windows 2
dtype: int64
# 用于按升序排列
# 行相加(win+nowin之和,排序),返回数值从小到大的索引值
indexer = agg_counts.sum(1).argsort() indexer[:10]
Out[90]:
tz
24
Africa/Cairo 20
Africa/Casablanca 21
Africa/Ceuta 92
Africa/Johannesburg 87
Africa/Lusaka 53
America/Anchorage 54
America/Argentina/Buenos_Aires 57
America/Argentina/Cordoba 26
America/Argentina/Mendoza 55
dtype: int64
通过take,截取了最后10行:(根据索引截取数据)
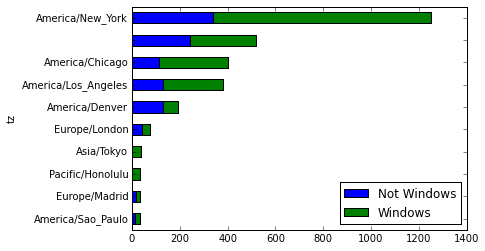
count_subset = agg_counts.take(indexer)[-10:] count_subset
Out[97]:
Not Windows Windows
tz
America/Sao_Paulo 13 20
Europe/Madrid 16 19
Pacific/Honolulu 0 36
Asia/Tokyo 2 35
Europe/London 43 31
America/Denver 132 59
America/Los_Angeles 130 252
America/Chicago 115 285
245 276
America/New_York 339 912
生成一张条形图,使用stacked=True 来生成一张堆积条形图
count_subset.plot(kind='barh', stacked=True)
Out[98]: <matplotlib.axes._subplots.AxesSubplot at 0xfd535f0>
将各行规划化为“总计为1”,并重新绘图
normed_subset = count_subset.div(count_subset.sum(1), axis=0) normed_subset.plot(kind='barh', stacked=True)
Out[100]: <matplotlib.axes._subplots.AxesSubplot at 0xfd53990>

Python进行数据分析(一)初步学习 对时区进行计数的更多相关文章
- 数据分析---《Python for Data Analysis》学习笔记【01】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 初步学习python
自计算机诞生以来,也伴随着计算机语言的诞生,现在,全世界的编程语言有600多种,但流行的编程语言也就20多种. Java和C一直占据着前两名.但是近年来伴随着人工智能的发展,Python发展迅猛,以其 ...
- PYTHON学习(三)之利用python进行数据分析(1)---准备工作
学习一门语言就是不断实践,python是目前用于数据分析最流行的语言,我最近买了本书<利用python进行数据分析>(Wes McKinney著),还去图书馆借了本<Python数据 ...
- 利用python进行数据分析——(一)库的学习
总结一下自己对python常用包:Numpy,Pandas,Matplotlib,Scipy,Scikit-learn 一. Numpy: 标准安装的Python中用列表(list)保存一组值,可以用 ...
- $《利用Python进行数据分析》学习笔记系列——IPython
本文主要介绍IPython这样一个交互工具的基本用法. 1. 简介 IPython是<利用Python进行数据分析>一书中主要用到的Python开发环境,简单来说是对原生python交互环 ...
- "利用python进行数据分析"学习记录01
"利用python进行数据分析"学习记录 --day01 08/02 与书相关的资料在 http://github.com/wesm/pydata-book pandas 的2名字 ...
- 数据分析---《Python for Data Analysis》学习笔记【04】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 数据分析---《Python for Data Analysis》学习笔记【03】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
- 数据分析---《Python for Data Analysis》学习笔记【02】
<Python for Data Analysis>一书由Wes Mckinney所著,中文译名是<利用Python进行数据分析>.这里记录一下学习过程,其中有些方法和书中不同 ...
随机推荐
- 团队计划会议(二)——WBS
一.会议及WBS 因为是第一次开发android应用,所以我们对这次开发心里也没底,最后我们商量暂时先实现主要的几个骨架功能,之后再慢慢完善. 会议期间,我们根据自己的能力大致先估算了完成这些功能需要 ...
- c# 捕获一般获取不到的异常
1.主函数入口加异常事件,代码例如: /// <summary> /// 应用程序的主入口点. /// </summary> [STAThread] static void M ...
- [CF] Sasha and One More Name
题目大意 就是给一个回文串,然后进行k次分割,产生k+1个字符子串,通过重新组合这k+1个字符字串,是否会出现新的不同的回文串,且最少需要分割几段.无法产生新的回文串则输出"Impossib ...
- 软工实践-Alpha 冲刺 (10/10)
队名:起床一起肝活队 组长博客:博客链接 作业博客:班级博客本次作业的链接 组员情况 组员1(队长):白晨曦 过去两天完成了哪些任务 描述: 完成所有界面的链接,整理与测试 展示GitHub当日代码/ ...
- 使用git提交代码的一些小心得
1.不进行push不能运行的代码,如果需要提交,可以先注释,保证其他人pull时,可以得到能够正常使用的代码 2.每做完一件事,写一条描述,一次提交.不要等写了一堆代码,然后写一堆描述,这样如果需要查 ...
- java第九周笔记
- CentOS安装crontab及使用方法(转)
CentOS安装crontab及使用方法(转) 安装crontab:[root@CentOS ~]# yum install vixie-cron[root@CentOS ~]# yum ins ...
- Android手机Fiddler真机抓包
Fiddler是最强大最好用的Web调试工具之一,它能记录所有客户端和服务器的http和https请求,允许用户监视,设置断点,甚至修改输入输出数据,Fiddler包含了一个强大的基于事件脚本的子系统 ...
- vdbench测试过程中遇到的小问题
1.报Slave hd2-0 prematurely terminated 错误 首先根据提示查看hd2-0.stdout.html文件获取更多的错误信息,这个问题一般是未安装vdbench或者路径不 ...
- http2.0可行性研究
一.http2比http1有了更多新特性 1.使用了多路复用的技术,并发量支持比http1大几个数量级: 2.二进制分帧,改善网络延迟情况,提高传输速率: 3.支持header的数据压缩,数据体积变 ...