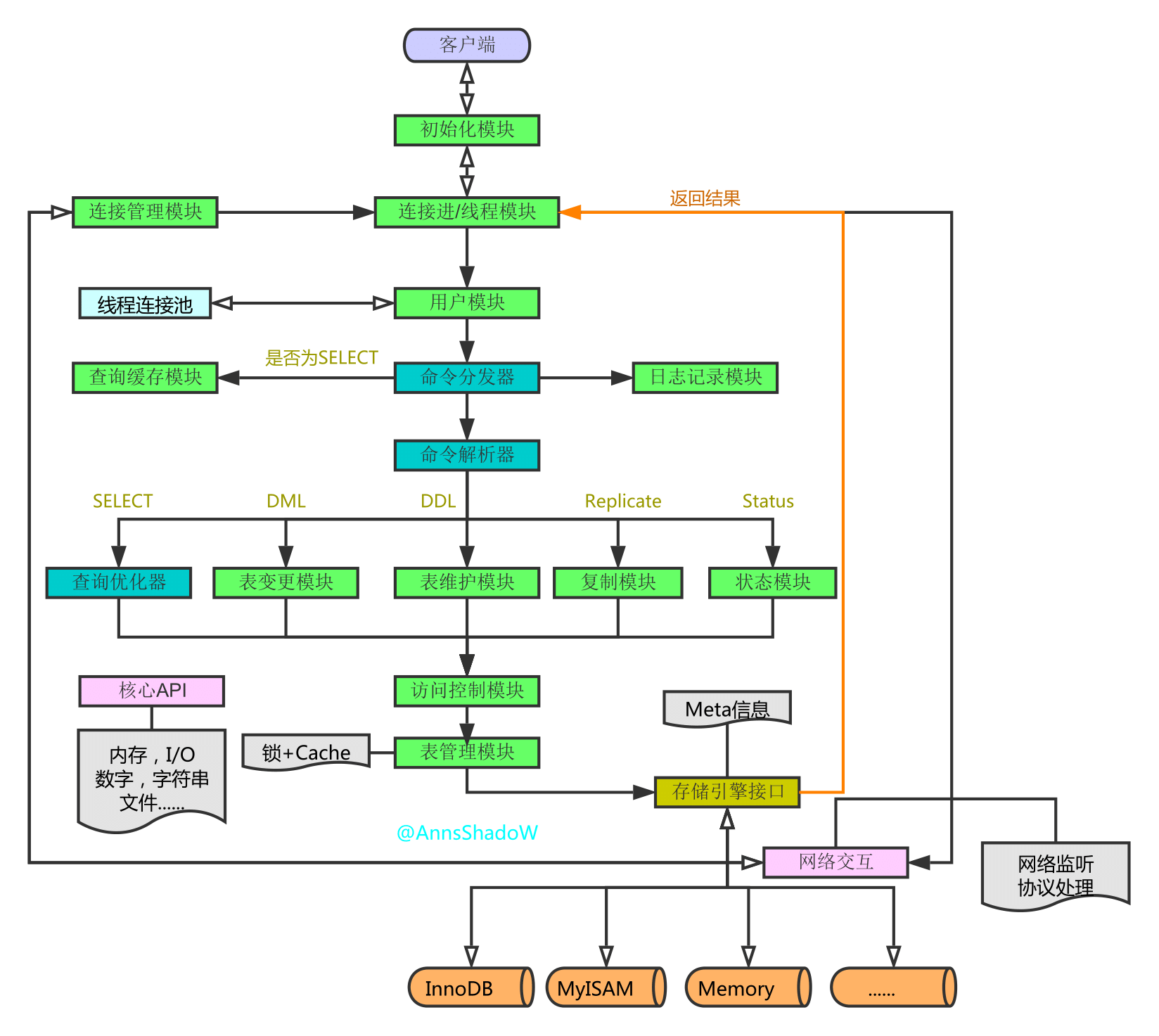
步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT
DISTINCT <select_list>
ORDER BY <order_by_condition>
LIMIT <limit_number>
create database testQuery
CREATE TABLE table1
(
uid VARCHAR(10) NOT NULL,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2
(
oid INT NOT NULL auto_increment,
uid VARCHAR(10),
PRIMARY KEY(oid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
INSERT INTO table1(uid,name) VALUES('aaa','mike'),('bbb','jack'),('ccc','mike'),('ddd','mike');
INSERT INTO table2(uid) VALUES('aaa'),('aaa'),('bbb'),('bbb'),('bbb'),('ccc'),(NULL);
SELECT
a.uid,
count(b.oid) AS total
FROM
table1 AS a
LEFT JOIN table2 AS b ON a.uid = b.uid
WHERE
a. NAME = 'mike'
GROUP BY
a.uid
HAVING
count(b.oid) < 2
ORDER BY
total DESC
LIMIT 1;
mysql> select * from table1,table2;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| bbb | jack | 1 | aaa |
| ccc | mike | 1 | aaa |
| ddd | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 2 | aaa |
| ccc | mike | 2 | aaa |
| ddd | mike | 2 | aaa |
| aaa | mike | 3 | bbb |
| bbb | jack | 3 | bbb |
| ccc | mike | 3 | bbb |
| ddd | mike | 3 | bbb |
| aaa | mike | 4 | bbb |
| bbb | jack | 4 | bbb |
| ccc | mike | 4 | bbb |
| ddd | mike | 4 | bbb |
| aaa | mike | 5 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 5 | bbb |
| ddd | mike | 5 | bbb |
| aaa | mike | 6 | ccc |
| bbb | jack | 6 | ccc |
| ccc | mike | 6 | ccc |
| ddd | mike | 6 | ccc |
| aaa | mike | 7 | NULL |
| bbb | jack | 7 | NULL |
| ccc | mike | 7 | NULL |
| ddd | mike | 7 | NULL |
+-----+------+-----+------+
28 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1,
-> table2
-> WHERE
-> table1.uid = table2.uid
-> ;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
+-----+------+-----+------+
6 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
7 rows in set (0.00 sec)

mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike';
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
4 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
3 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC
-> LIMIT 1;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
+-----+-------+
1 row in set (0.00 sec)

步步深入:MySQL架构总览->查询执行流程->SQL解析顺序的更多相关文章
- MySQL架构总览->查询执行流程->SQL解析顺序
Reference: https://www.cnblogs.com/annsshadow/p/5037667.html 前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后 ...
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序(转)
文章转自 http://www.cnblogs.com/annsshadow/p/5037667.html https://www.cnblogs.com/cuisi/p/7685893.html
- 步步深入MySQL:架构->查询执行流程->SQL解析顺序!
一.前言 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序 ...
- 让MySQL为我们记录执行流程
让MySQL为我们记录执行流程 我们可以开启profiling,让MySQL为我们记录SQL语句的执行流程 查看profiling参数 shell > select @@profilin ...
- mysql join语句的执行流程是怎么样的
mysql join语句的执行流程是怎么样的 join语句是使用十分频繁的sql语句,同样结果的join语句,写法不同会有非常大的性能差距. select * from t1 straight_joi ...
- MySQL深层理解,执行流程
MySQL是一个关系型数据库,关联的数据保存在不同的表中,增加了数据操作的灵活性. 执行流程 MySQL是一个单进程服务,每一个请求用线程来响应, 流程: 1,客户请求,服务器开辟一个线程响应用户. ...
- Spark架构与作业执行流程简介(scala版)
在讲spark之前,不得不详细介绍一下RDD(Resilient Distributed Dataset),打开RDD的源码,一开始的介绍如此: 字面意思就是弹性分布式数据集,是spark中最基本的数 ...
- mysql update语句的执行流程是怎样的
update更新语句流程是怎么样的 update更新语句基本流程也会查询select流程一样,都会走一遍. update涉及更新数据,会对行加dml写锁,这个DML读锁是互斥的.其他dml写锁需要等待 ...
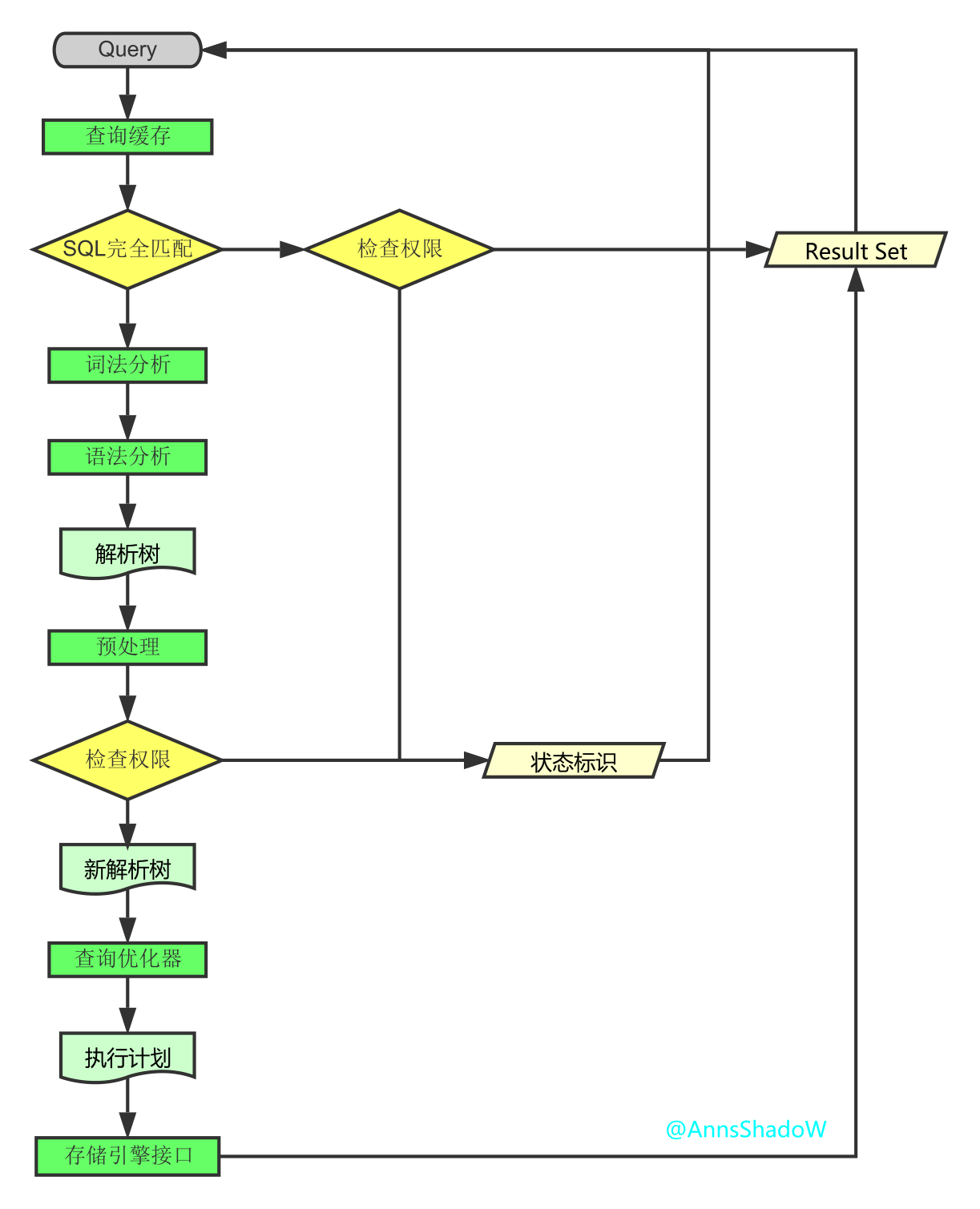
- SQL学习笔记四(补充-1-1)之MySQL单表查询补充部分:SQL逻辑查询语句执行顺序
阅读目录 一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析 一 SELECT语句关键字的定义顺序 SELE ...
随机推荐
- Android开发学习之路-RecyclerView滑动删除和拖动排序
Android开发学习之路-RecyclerView使用初探 Android开发学习之路-RecyclerView的Item自定义动画及DefaultItemAnimator源码分析 Android开 ...
- 根据xml文件名获取xml数据并转化为实体。
1.定义一个xml文件. <?xml version="1.0" encoding="utf-8" ?> <UserManager xmlns ...
- Atitit.每月数据采集与备份 v4
Atitit.每月数据采集与备份 v4 备份检查表 r12 00cate 00item im Inputmethod ok ok Log Log ok cyar Cyar log ... ok c ...
- 解决 SpringBoot 没有主清单属性
问题:SpringBoot打包成jar后运行提示没有主清单属性 解决:补全maven中的bulid信息 <plugin> <groupId>org.springframewor ...
- 聊聊excel生成图片的几种方式
目录 I:需求. II:实现思路. III:实现方式. IV:优缺点分析. V:结论. VI:wps安装与配置. 正文 1.需求:把excel生成等比的图片. ...
- SharePoint 2013 create workflow by SharePoint Designer 2013
这篇文章主要基于上一篇http://www.cnblogs.com/qindy/p/6242714.html的基础上,create a sample workflow by SharePoint De ...
- 虚拟IP(VIP)
高可用性HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性.HA系统是目前企业防止核心计算机系统因故 ...
- ASP.NET Core 中文文档 第四章 MVC(01)ASP.NET Core MVC 概览
原文:Overview of ASP.NET Core MVC 作者:Steve Smith 翻译:张海龙(jiechen) 校对:高嵩 ASP.NET Core MVC 是使用模型-视图-控制器(M ...
- CSS知识总结(五)
CSS常用样式 3.边框样式 1)边框线 border-style : none | hidden | dotted | dashed | solid | double | groove | ridg ...
- 深入理解javascript原生拖放
× 目录 [1]拖放源 [2]拖放目标 [3]dataTransfer对象[4]改变光标 前面的话 拖放(drag-and-drop,DnD)其实是两个动作——拖和放.所以,它涉及到两个元素.一个是被 ...