网络爬虫中Fiddler抓取PC端网页数据包与手机端APP数据包
1 引言
在编写网络爬虫时,第一步(也是极为关键一步)就是对网络的请求(request)和回复(response)进行分析,寻找其中的规律,然后才能通过网络爬虫进行模拟。浏览器大多也自带有调试工具可以进行抓包分析,但是浏览器自带的工具比较轻量,复杂的抓包并不支持。且有时候需要编写手机APP爬虫,这时候就必须需要用到其他的专业抓包工具,例如本篇介绍的Fiddler。
2 Fiddler简介
Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一,它能够记录客户端和服务器之间的所有 HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是web调试的利器。
当然,除了Fiddler之外,抓包工具还有Firebug、Wireshark、Httpwatch等,为什么我们要选择fiddler呢?原因如下:
(1)Firebug虽然可以抓包,但是对于分析http请求的详细信息,不够强大。模拟http请求的功能也不够,且firebug常常是需要“无刷新修改”,如果刷新了页面,所有的修改都不会保存。
(2)Wireshark是通用的抓包工具,但是比较庞大,对于只需要抓取http请求的应用来说,似乎有些大材小用,总有一点杀鸡用牛刀的感觉。
(3)Httpwatch也是比较常用的http抓包工具,但是只支持IE和firefox浏览器(其他浏览器可能会有相应的插件),对于想要调试chrome浏览器的http请求,似乎稍显无力,而Fiddler 是一个使用本地 127.0.0.1:8888 的 HTTP 代理,任何能够设置 HTTP 代理为 127.0.0.1:8888 的浏览器和应用程序都可以使用 Fiddler。
3 Fiddler界面介绍
Fiddler界面如下:
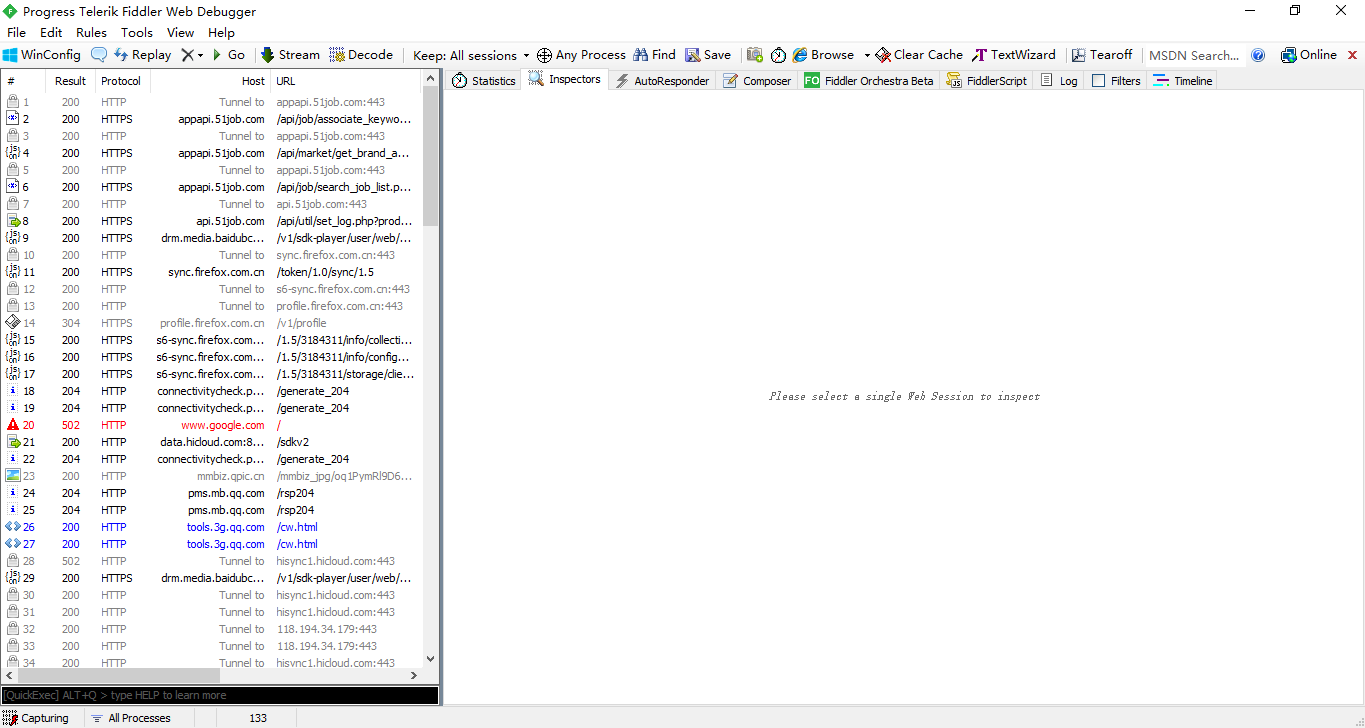
Fiddler界面左侧的小窗口列表展示的是所有Fiddler抓取的包,各个包每个字段还有图标的含义如下表所示:
|
名称 |
含义 |
|
# |
抓取HTTP Request的顺序,从1开始,以此递增 |
|
Result |
HTTP状态码 |
|
Protocol |
请求使用的协议,如HTTP/HTTPS/FTP等 |
|
Host |
请求地址的主机名 |
|
URL |
请求资源的位置 |
|
Body |
该请求的大小 |
|
Caching |
请求的缓存过期时间或者缓存控制值 |
|
Content-Type |
请求响应的类型 |
|
Process |
发送此请求的进程:进程ID |
|
Comments |
允许用户为此回话添加备注 |
|
Custom |
允许用户设置自定义值 |
数据包属性第一列的图标含义如下表所示:
|
图标 |
含义 |
 |
请求已经发往服务器 |
 |
已从服务器下载响应结果 |
 |
请求从断点处暂停 |
 |
响应从断点处暂停 |
 |
请求使用 HTTP 的 HEAD 方法,即响应没有内容(Body) |
 |
请求使用 HTTP 的 POST 方法 |
 |
请求使用 HTTP 的 CONNECT 方法,使用 HTTPS 协议建立连接隧道 |
 |
响应是 HTML 格式 |
 |
响应是一张图片 |
 |
响应是脚本格式 |
 |
响应是 CSS 格式 |
 |
响应是 XML 格式 |
 |
响应是 JSON 格式 |
 |
响应是一个音频文件 |
 |
响应是一个视频文件 |
 |
响应是一个 SilverLight |
 |
响应是一个 FLASH |
 |
响应是一个字体 |
 |
普通响应成功 |
 |
响应是 HTTP/300、301、302、303 或 307 重定向 |
 |
响应是 HTTP/304(无变更):使用缓存文件 |
 |
响应需要客户端证书验证 |
 |
服务端错误 |
 |
会话被客户端、Fiddler 或者服务端终止 |
Fiddler界面右侧是用来显示选中数据报的详细信息,上半部分显示的是数据报的请求信息,下半部分显示的是回复信息:

4 PC端网页会话数据包捕获
4.1 HTTP会话数据包捕获
Fiddler打开后,会自动将浏览器代理设置为“127.0.0.1:8888”,关闭时自动修改为原来的代理,这一点上Fiddler还是比较方便的。当然你也可以手动设置浏览器代理。开始抓包是必须确保猜到了file下的Capture Traffic是勾选上的,当然也可以通过下方的Capturing按钮开启或关闭。
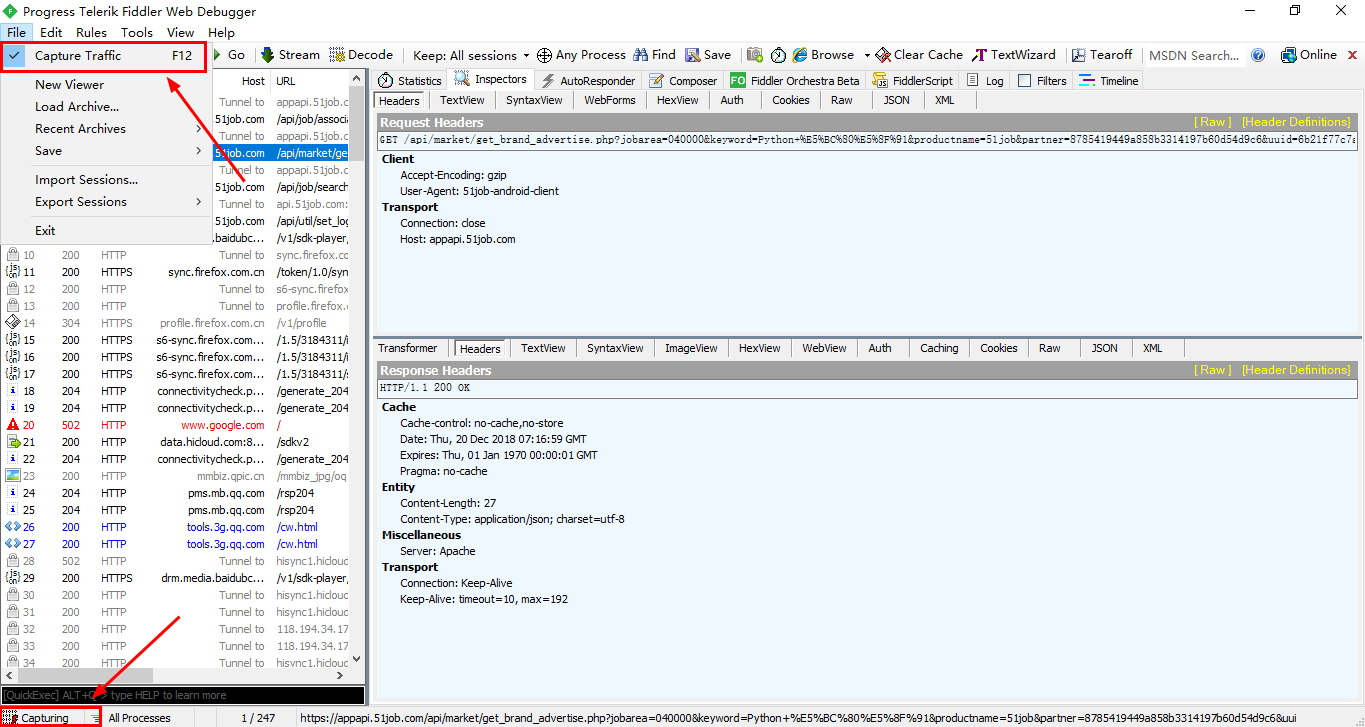
打开后,Fiddler会自动捕获所有HTTP会话信息。
4.2 HTTPS会话数据包捕获
完成上述设置之后可以捕获HTTP协议下的会话信息,但现在的很多网站都采用HTTPS协议,用Fiddler不会就会出问题。百度首页采用的就是HTTPS协议,如下图所示,当我们尝试使用Fiddler不会访问百度首页时,出现捕获失败: 
所以,若是要捕获HTTPS协议会话信息,要进行进一步的配置。配置过程如下:
第一步:打开Tools – Options,然后将弹出窗口内HTTPS选项下的所有可选项都勾选上。
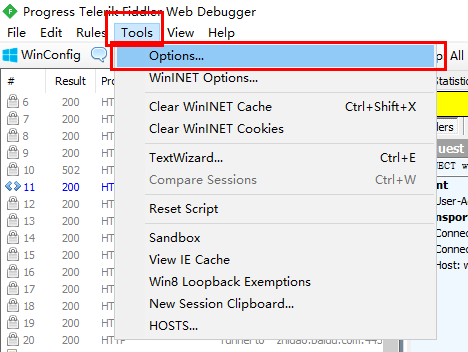
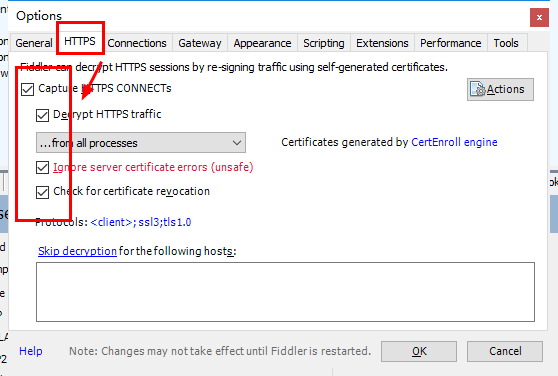
有的网上教程说到此点击OK就可以了,但事实证明,如果就设置到这一步,打开HTTPS网页会失败,出现警告“您的连接并不安全”,如下图所示。所以还要进行第二步操作。

第二步:还是在第一步中打开的弹出窗口内,点击action,然后选择第二项,将证书到处到桌面。

第三步:打开firefox浏览器,选项-隐私与安全,在最下面找到证书设置项,点击“查看证书”,导入在第二步中到处到桌面的证书,勾选两个信任之后确认退出。
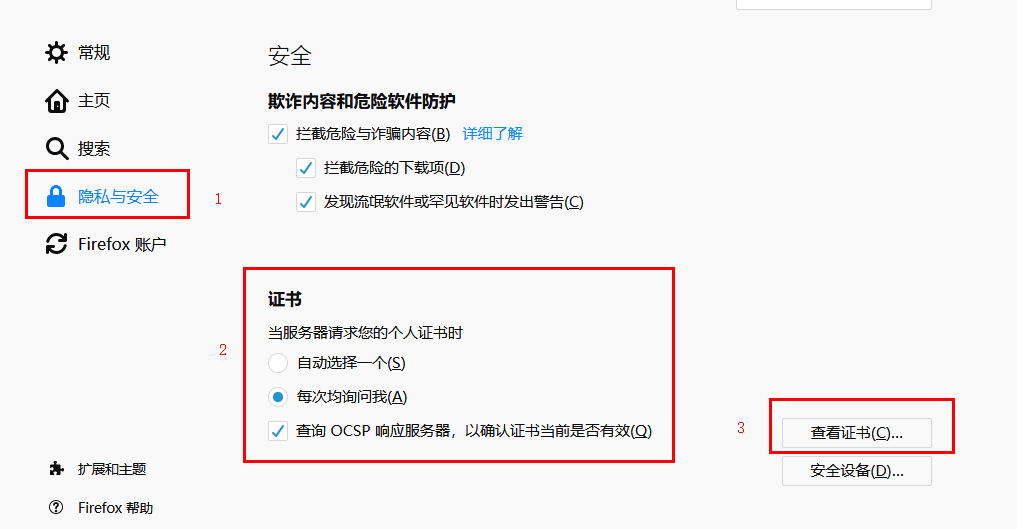
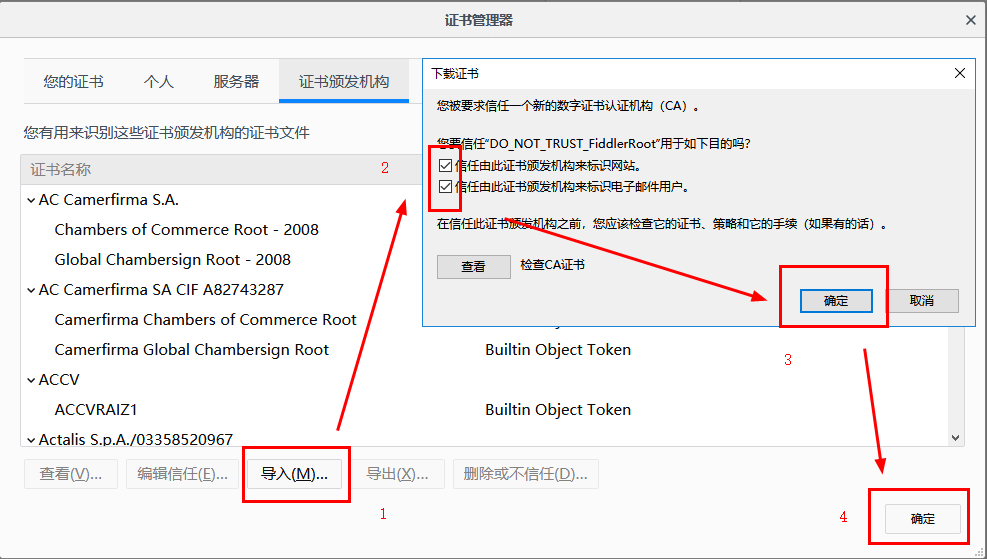
此时,再次打开百度首页,查看Fiddler捕获的信息,发现可以正常访问百度,且Fiddler没有报警报信息,且成功捕获如下所示: 
5 手机端APP会话信息采集
除了采集电脑浏览器的网页会话外,Fiddler还能采集手机APP的会话信息。当然,这还是需要经过一番设置才行。步骤如下:
第一步:用电脑开启一个无线网(360WiFi、猎豹wifi等都可以实现),然后让手机通过电脑开启的无线网上网。
第二步:依次点击打开Tools-Options-Connections,然后勾选第二项“Allow remote compute to connect”。
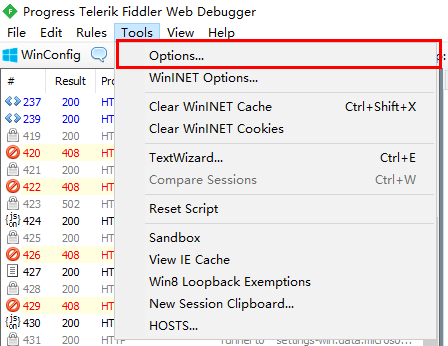

第三步:到手机中将手机的网络代理改为电脑的fiddler。首先查看电脑的ip地址,然后在手机中一次打开“设置-无线和网络-wlan”,连接上电脑上刚创建的无线网,然后长按该无线网,依次点击“修改网络-显示高级设置-代理-手动”,将服务器主机名设置为电脑的ip地址,端口设置为8888。如下图所示:


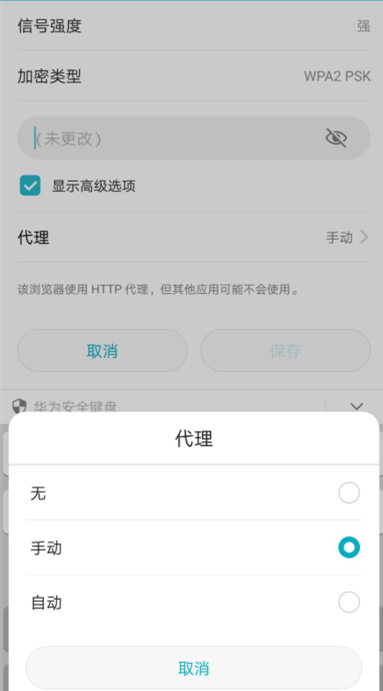
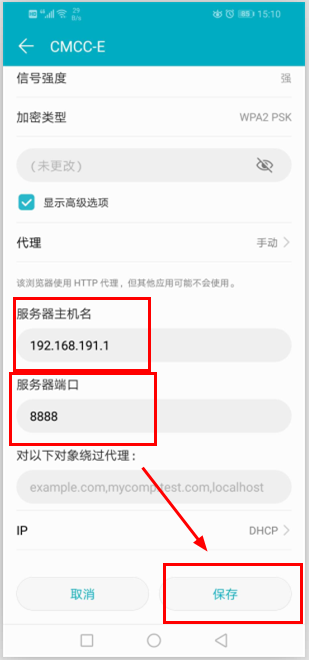
设置好后,我们Fiddler就可以成功捕获手机APP的会话信息了。
6 会话过滤功能
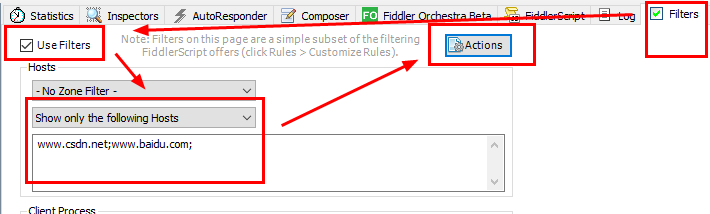
当我们打开Fiddler进行会话捕获时,在默认情况下,Fiddler会不会所有的会话,这样就造成不会的会话过多,不利于我们分析,这时候我们可以用到Filters功能进行会话过滤。Filters三种过滤模式供选择:
- No Host Filter:不设置域名过滤;
- Hide the following Hosts:设置的这些域名相关会话将在左侧会话列表中被隐藏;
- Show only the following Hosts:只在会话列表中显示与设置的这些域名相关的会话;
- Flag the following Hosts:与设置的域名相关会话将在左侧会话列表中高亮想显示。
如果要设置多个域名,域名之间用分号分开。切记,选好后要点击Actions按钮,然后点击Runfiltersets now让设置生效。如果我们只想显示百度和CSDN的会话信息,设置过程如下图所示:
7 总结
Fiddler是一个功能强大的网络抓包工具,本文对如何用Fiddler抓取HTTP、HTTPS、手机APP会话数据报介绍了,另外还补充介绍了数据包过滤的功能。当然,Fiddler的功能远不止这些,不过本文介绍的操作用于一般的网络爬虫数据包分析足以。
网络爬虫中Fiddler抓取PC端网页数据包与手机端APP数据包的更多相关文章
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
- 『言善信』Fiddler工具 — 16、使用Fiddler抓取移动端App请求
目录 1.抓取Android移动端App请求 2.抓取IOS移动端App请求 3.总结: 1.抓取Android移动端App请求 前提: 因为Fiddler抓包的原理就是通过代理,所以确保被测终端要和 ...
- 爬虫之Fiddler抓取HTTPS设置
Fiddler抓取HTTPS设置 启动Fiddler,打开菜单栏中的 Tools > Telerik Fiddler Options,打开“Fiddler Options”对话框. 对Fiddl ...
- 有了 Docker,用 JavaScript 框架开发的 Web 站点也能很好地支持网络爬虫的内容抓取
点这里 阅读目录 用 AngularJS(以及其它 JavaScript 框架)开发的 Web 站点不支持爬虫的抓取 解决方案 为什么公开我们的解决方案 实现 AngularJS 服务 结论 Pr ...
- 网络爬虫Java实现抓取网页内容
package 抓取网页; import java.io.FileOutputStream;import java.io.IOException;import java.io.InputStream; ...
- Fiddler 抓取 ios 端数据包
前提条件: 1. Fiddler 工具安装完成,并授权成功,可以完成网页的http 协议拦截. 2. iphone X 一部 ☺ 3. 360wifi 一个[同一局域网内,任何wifi都可以设置,其他 ...
- 读书笔记--用Python写网络爬虫02--数据抓取
抓取(scraping)---爬虫从网页中抽取一些数据用以实现某些用途. 三种抽取网页数据的方法:正则表达式.Beautiful Soup和lxml. 2.1 分析网页 通过浏览器自带选项,查看网页源 ...
- Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据. 我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕.所以这次我们的 ...
随机推荐
- 【codevs1006】等差数列
题目大意:给定一个 N(N <= 100) 个数字组成的集合,从中取出若干数字组成的等差数列最长是多少. 题解:由于这道题数据范围较小,可以直接依据每个数字进行枚举.首先,这道题给出的是一个集合 ...
- linux中awk工具的使用(转载)
awk是一个非常好用的数据处理工具.相较于sed常常一整行处理,awk则比较倾向于一行当中分成数个“字段”处理,awk处理方式如下: $ awk '条件类型1{动作1} 条件类型2{动作2} ...' ...
- debian8.4 系统莫名没有声音
[http://www.linuxdiyf.com/viewarticle.php?id=437020 Debian8, 桌面环境是xfce4, 安装完成后发现前面板音频输出插孔正常,后面板的没声音. ...
- gdb调试2—单步执行和跟踪函数
int add_range(int low, int high); int main(int argc, char *argv[]) { int result[100]; result[0] = ad ...
- 【CSS】定义元素的位置
CSS定义元素的位置html元素的position属性,有4个属性值,分别是static.relative.fixed.absolute static: 1.默认值,一般不显式设置为static 2. ...
- CString的头文件
CString的头文件:#include <atlstr.h>
- 卸载并安装指定版本Angular CLI
1.卸载之前的版本 npm uninstall -g @angular/cli 2.清除缓存,确保卸载干净 npm cache clean 3.检查是否卸载干净 输入命令 ng -v 若显示comma ...
- ssh-copy-id 复制公钥到远程server
ssh-copy-id -i ~/.ssh/mykey.pub user@host 复制完成后可以测试: ssh -i ~/.ssh/mykey user@host
- lucene删除索引——(五)
增加在入门程序创建索引中,增删改用IndexWriter. 1.获取IndexWriter的代码 // public IndexWriter getIndexWriter() throws Excep ...
- SQL008存储过程总结
1.如何调用存储过程 DECLARE @Id INT --输入参数 DECLARE @OutPutID INT --输出参数 EXEC [dbo].Order_SellPR @Id,@OutPutID ...