webkit技术内幕读书笔记 (四)
资源缓存
资源缓存的目的是为了提高资源使用的效率,其基本思想是建立一个资源的缓存池,当需要请求资源的时候先去资源池查找是否有相应的资源,如果没有则向服务器发送请求,webkit收到资源后将其设置到该资源类的对象中去,以便于缓存后下次使用,webkit从资源池中查找资源的关键字是URL,URL标记了资源的唯一性。
以上说明一个问题,如果ulr不同,就算内容相同也会被重新请求。
资源加载
鉴于从网络获取资源时一个非常耗时的过程,通常一些资源的加载是异步执行的,也就是说资源的获取和加载不会阻碍 当前 WebKit的渲染过程,例如图片、CSS文件。当然,网页也存在某些特别的资源会阻碍主线程的渲染过程,例如 JavaScript 代码文件。这会严重影响 WebKit 下载资源的效率,因为后面可能还有许多需要下载的资源,WebKit会怎么做?因为主线程被阻碍了,后面的解析工作没办法继续往下进行,所以对于 HTML 网页中后面使用的资源也没有办法知道并发送下载请求。当遇到这种情况的时候,WebKit的做法是这样的:当前的主线程被阻碍时。WebKit会启动另外一个线程去遍历后面的HTML页面,收集需要的资源URL,然后发送请求,这样就可以避免被阻碍。与此同时,WebKit 能够并发下载这些资源,甚至并发下载 JavaScript 代码资源。
为了验证以上是否正确,在本地搭了个服务器测试,其中有一个index.html页面,和一个服务器脚本,服务器脚本用来延迟加载js。
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<h2>h2</h2>
<script src="http://localhost:8081/index.js"></script>
<h3>h3</h3>
<img src="test/images/0.png" alt="">
<img src="test/images/1.png" alt="">
<img src="test/images/2.png" alt="">
<script src="index.js"></script>
<script>
console.log("ok");
</script>
</body>
</html>
nodejs脚本 index.js
var http = require("http");
http.createServer(function(req,res){
}).listen(8081);
index.html请求了8081端口的一个js脚本,但是我始终不给它响应。

可以看到加载js的那一块始终是一个pending状态,但是在js后面的资源还是被下载了,也就是说webkit确实是开了多个线程去下载资源的,但你也可以看到,它虽然是开了多个线程去下载资源,但是并没有去执行后面的代码,如下图
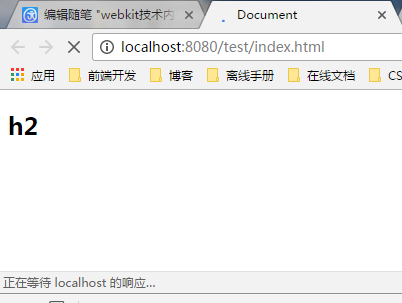
从另外一个方面也可以看出它没有去执行后面的代码,我在index.html中写了这么一段代码<script src="index.js"></script>假如说它执行了,那么应该报错才对,因为这段代码的内容就是那个nodejs中的,如果我返回内容,效果就是下面这样

也就是说,虽然资源webkit可能开多个线程去下载,但是执行代码,始终用的是一个线程,对于执行javascript代码使用一个线程执行,还算好理解,因为某些js文件可能依赖于其他的js文件,如果说使用多线程,这必然是一个比较麻烦的问题,另外如果某些js文件必须早于其他文件执行,那么多线程依然还是个问题,对于图片和dom大概也是同样的道理吧,如果说下载下来的图片,马上就去显示,那如果说我在前面的js中给body加了一个display:none;那么你说是这个图片是显示呢还是不显示呢?不能因为前面的js堵塞了后面的代码执行,你就乱显示吧,这也是多线程了一些烦恼吧。
资源的生命周期
同CachedResourceLoader对象一样,资源池也属于HTML文档对象,由于资源池不能无限大,因此要用相应的机制来替换其中的资源,从而加入新的资源,这种机制采用的算法为LRU(最近最少使用)算法。对于打开网页刷新当前页面的场景,对于某些资源,webkit需要直接重新发送请求,要求服务器端将内容重新发送过来,但对于大多数资源,Webkit则可以利用HTTP协议减少网络负载,在HTTP协议中对此有规定,游览器可以发送消息确认是否需要更新,如果有则游览器重新获取该资源,否则就需要利用该资源。
webkit的做法如下,首先判断资源是否在资源池中,如果在则发送一个HTTP请求给服务器,说明该资源在本地的一些信息,例如修改时间等,服务器根据该信息进行判断,如果没有更新则返回状态码304表示不需要更新,直接利用资源池中的资源,否则webkit申请下载最新的资源内容。
DNS预取和TCP预连接
一次DNS查询的平均时间大概在60~120ms之间或者更长,而TCP的三次握手时间大概也是几十毫秒或者更长,看似是一个很短的时间,但是相对于网页的渲染来说,这是一个相当长的时间,如何有效的缩短这段时间,Chromium给出了自己的解决方案—DNS预取和TCP预连接。
首先讲一下DNS预取,他的主要思想就是利用现有的DNS机制,提前解析网页中可能的网络连接。具体来说,就是当用户正在浏览当前网页的时候,Chromium提取网页中的超链接,将域名抽取出来,利用比较少的CPU和网络带宽来解析这部分域名或IP地址,这样一来,用户根本感觉不到这一过程。但是当用户单击这些链接的时候,由于已经提前做好了DNS解析,可以节省不少时间,特别是对于域名解析比较慢的时候,效果尤其明显。(DNS预取技术针对多个域名采取并行处理的方式,每个域名的解析均是由新开启的一个线程来处理的,结束后此线程即退出)
当然,我们也可以显式指定预取哪些域名来让Chromium解析,这非常直接了当。特别是对于那些需要重定向的域名,具体做法如下:
<link rel="dns-prefetch" href="http://this-is-a-dns-prefetch-example.com">。DNS预取技术不仅应用于网页中的超链接,当我们在地址栏中输入地址后,候选项同输入的地址很匹配的时候,在我们敲下回车键获取该网页之前,Chromium已经开始使用DNS预取技术解析该域名了。
接下来是TCP预连接,Chromium使用追踪技术来获取用户从什么网页跳转到另外一个网页,可以利用这些数据,一些启发式的规则和其他暗示来预测用户下面回单击什么超链接,当有足够的把握的时候,他便会DNS预取,更进一步,还可以预先简历TCP连接。听起来是不是特别6?不错,Chromium就是这么6!同DNS预取技术一样,追踪技术不仅应用于网页中的超链接,当用户在地址栏中输入地址的时候,也同样适用!
webkit技术内幕读书笔记 (四)的更多相关文章
- webkit技术内幕读书笔记 (一)
本文部分摘录自互联网. Chromeium与Chrome Chromium是Google为发展自家的浏览器Google Chrome而打开的项目,所以Chromium相当于Google Chrome的 ...
- webkit技术内幕读书笔记 (二、三)
可视区和网页 通常网页比屏幕的可视区面积要大,因此当网页内容在可视区中放不下时,一般浏览器会提供滚动条. 从URL到构建完DOM树的过程 当用户输入网页URL的时候,WebKit调用其资源加载器加载该 ...
- 深入理解linux网络技术内幕读书笔记(四)--通知链
Table of Contents 1 概述 2 定义链 3 链注册 4 链上的通知事件 5 网络子系统的通知链 5.1 包裹函数 5.2 范例 6 测试实例 概述 [注意] 通知链只在内核子系统之间 ...
- Struts2技术内幕 读书笔记三 表示层的困惑
表示层能有什么疑惑?很简单,我们暂时忘记所有的框架,就写一个注册的servlet来看看. index.jsp <form id="form1" name="form ...
- Struts2技术内幕 读书笔记一 框架的本质
本读书笔记系列,主要针对陆舟所著<<Struts2技术内幕 深入解析Strtus2架构设计与实现原理>>一书.笔记中所用的图片若无特殊说明,就都取自书中,特此声明. 什么是框架 ...
- 深入理解linux网络技术内幕读书笔记(三)--用户空间与内核的接口
Table of Contents 1 概论 1.1 procfs (/proc 文件系统) 1.1.1 编程接口 1.2 sysctl (/proc/sys目录) 1.2.1 编程接口 1.3 sy ...
- Kafka技术内幕 读书笔记之(四) 新消费者——消费者提交偏移量
消费组发生再平衡时分区会被分配给新的消费者,为了保证新消费者能够从分区的上一次消费位置继续拉取并处理消息,每个消费者需要将分区的消费进度,定时地同步给消费组对应的协调者节点 .新AP I为客户端提供了 ...
- Kafka技术内幕 读书笔记之(四) 新消费者——心跳任务
消费者拉取数据是在拉取器中完成的,发送心跳是在消费者的协调者上完成的,但并不是说拉取器和消费者的协调者就没有关联关系 . “消费者的协调者”的作用是确保客户端的消费者和服务端的协调者之间的正常通信,如 ...
- Kafka技术内幕 读书笔记之(四) 新消费者——新消费者客户端(二)
消费者拉取消息 消费者创建拉取请求的准备工作,和生产者创建生产请求的准备工作类似,它们都必须和分区的主副本交互.一个生产者写入的分区和消费者分配的分区都可能有多个,同时多个分区的主副本有可能在同一个节 ...
随机推荐
- mui框架如何实现页面间传值
mui框架如何实现页面间传值 我的传值 listDetail = '<li class="mui-table-view-cell mui-media>">< ...
- All Start Here.
缘由 本博客是为天大软院 2016 级研一课程"现代软件工程"的课程设计而开设.同时借此机会和同学们进行技术交流与分享. 我们小组共有四位成员: 陈岩岩 2016218020 刘莞 ...
- VS2010与VS2013中的多字节编码与Unicode编码问题
1. 多字节字符与单字节字符 char与wchar_t 我们知道C++基本数据类型中表示字符的有两种:char.wchar_t. char叫多字节字符,一个char占一个字节,之所以叫多字节字符是因 ...
- 1.Django入门
MVC 大部分开发语言中都有MVC框架 MVC框架的核心思想是:解耦 降低各功能模块之间的耦合性,方便变更,更容易重构代码,最大程度上实现代码的重用 m表示model,主要用于对数据库层的封装 v表示 ...
- nginx实现unigui群集
nginx实现unigui群集 在笔者写此文的时候,UNIGUI1.50.x的版本已经发布,其提供的HyperServer已经支持群集. 有网友还专门为此做了群集方面的测试: 从上图可以看出:群集总共 ...
- 微赞微擎V0.8以上版本:【数据库读写分离】实战教程 [复制链接]
http://www.efwww.com/forum.php?mod=viewthread&tid=4870 马上注册,下载更多源码,让你轻松玩转微信公众平台. 您需要 登录 才可以下载或查看 ...
- Delphi XE 新功能试用:多种皮肤样式静、动态设置方法
静态方式:1.新建VCL Forms Application:2.打开菜单Project - Application - Appearance:3.在Custom Styles中可选择所有默认带的皮肤 ...
- ASP.NET Core 2.1 源码学习之 Options[3]:IOptionsMonitor
前面我们讲到 IOptions 和 IOptionsSnapshot,他们两个最大的区别便是前者注册的是单例模式,后者注册的是 Scope 模式.而 IOptionsMonitor 则要求配置源必须是 ...
- c# file 上传EXCEL文件,以流的形式读取数据
1.引入 Aspose.Cells public void test() { HttpFileCollection filelist = HttpContext.Current.Request.Fi ...
- ASP.NET MVC高亮显示当前页面菜单
1.创建MvcHtmlExtension扩展类 public static class MvcHtmlExtension { public static MvcHtmlString MenuLink( ...