【论文阅读】Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification
转载请注明出处:https://www.cnblogs.com/White-xzx/
原文地址:https://arxiv.org/abs/1702.05891
Caffe-code:https://github.com/zhufengx/SRN_multilabel
如有不准确或错误的地方,欢迎交流~
空间正则化网络(Spatial Regularization Network, SRN),学习所有标签间的注意力图(attention maps),并通过可学习卷积挖掘标签间的潜在关系,结合正则化分类结果和 ResNet-101 网络的分类结果,以提高图像分类表现。
【SRN的优势】
(1)挖掘图像多标签之间的语义和空间关联性,较大地提高精度;
(2)当网络模型对具有空间相关标签的图片训练后,注意力机制自适应地关注图像的相关区域
(3)图像级标注,端到端训练

【SRN网络结构】
(1)Main Net:ResNet-101,针对各标签分别学习得到独立的分类器。“Res-2048” 表示具有2048输出的 ResNet 网络模块;
(2)SRN 采用ResNet-101的视觉特征作为输入,利用注意力机制学习得到标签间的正则空间关系;
(3)结合主网络和SRN的分类结果得到最终的分类置信度;
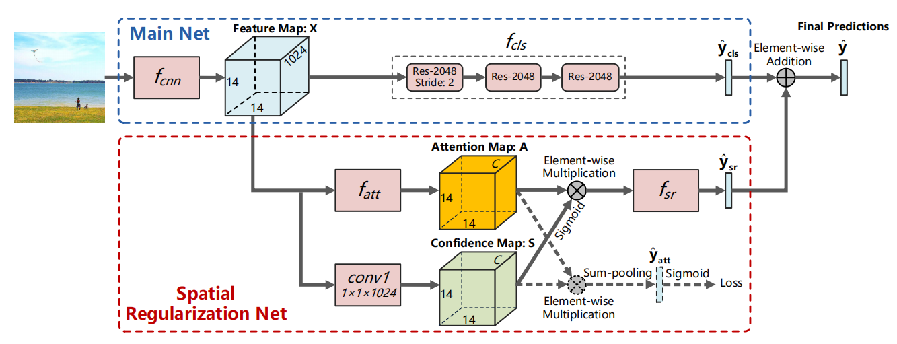
【Main Net】
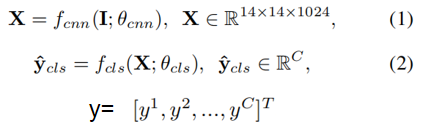


【SRN:注意力机制 fatt(·)】
当图像存在某个标签时,更多的注意力应该放在相关的区域,标签注意力图编码了标签对应的丰富空间信息。l被标记则l相关区域的注意力值应该更高
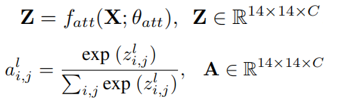

注意力图能用于产生更鲁棒的空间正则信息,但每个标签的注意力图总是和为1,可能会突出错误位置,造成错误的空间正则信息,论文提出使用加权注意力图U,U解码了标签局部和全局的置信分数(confidence)。

【SRN:fsr(·)结构】
conv2、conv3多通道,512输出,捕捉多标签的语义关系;
conv4单通道,2048输出,4个kernel为一组缠绕1个相同的特征通道,不同kernel捕捉语义关联标签间的不同空间关系。

【Multiple Steps 分步训练】
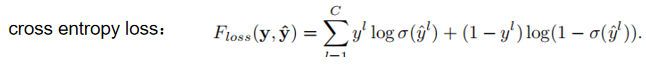
分四个阶段: ①只训练主网络, 基于 ResNet,pretrained on ImageNet,fcnn 和 fcls;
②固定 fcnn 和 fcls, 训练 fatt;
③固定 fcnn, fcls和 fatt,训练 fsr;
④联合训练整个网络。
图像增强策略: ①resize为256×256
②裁剪4个角和中心区域,长宽在{256,224,192,168,128}中随机选取
③resize为224×224
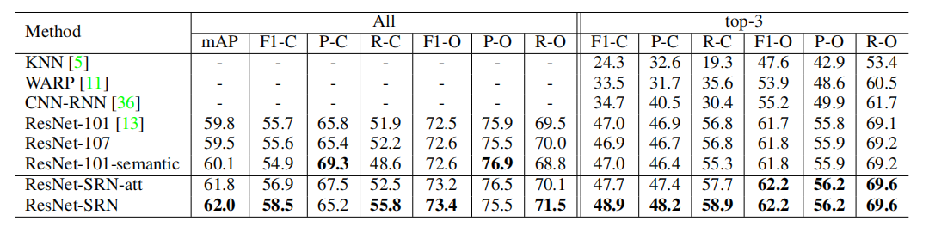
【实验结果】


【论文阅读】Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification的更多相关文章
- Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification
- 论文阅读笔记(十七)【ICCV2017】:Dynamic Label Graph Matching for Unsupervised Video Re-Identification
Introduction 文章主要提出了 Dynamic Graph Matching(DGM)方法,以非监督的方式对多个相机的行人视频中识别出正确匹配.错误匹配的结果.本文主要思想如下图: 具体而言 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
随机推荐
- TCP 协议连接与关闭的握手
原文链接 http://blog.csdn.net/oney139/article/details/8103223 TCP头部: 其中 ACK SYN 序号 这三个部分在以下会用到,它们 ...
- Steady Cow Assignment POJ - 3189 (最大流+匹配)
Farmer John's N (1 <= N <= 1000) cows each reside in one of B (1 <= B <= 20) barns which ...
- MT【99】2005联赛二试题我的一行解法
为表示尊敬先展示参考答案:参考答案其实很好的体现了当年出题人陶平生的想法,就是利用已知形式联想到三角里的射影定理,从而写出余弦定理形式,利用三角解题,如下: 这里展示以下几年前做这题时我的解法: $\ ...
- 【BZOJ3232】圈地游戏(分数规划,网络流)
[BZOJ3232]圈地游戏(分数规划,网络流) 题面 BZOJ 题解 很神仙的一道题. 首先看到最大化的比值很容易想到分数规划.现在考虑分数规划之后怎么计算贡献. 首先每条边的贡献就变成了\(mid ...
- BZOJ 2480 && 3239 && 2995 高次不定方程(高次同余方程)
链接 BZOJ 2480 虽然是个三倍经验题(2333),但是只有上面这道(BZOJ2480)有 p = 1 的加强数据,推荐大家做这道. 题解 这是一道BSGS(Baby Step Giant St ...
- SoapUI使用笔记备忘
1.安装好SoapUI后,新建一个REST项目 注意新建REST项目时,需要输入测试站点的地址,即IP+端口 之后点击OK就建立好了项目,但是新项目会默认自带一个根路径访问请求,可以删除(一般没用) ...
- dynamic
dynamic的特性很多,好像和反射也有关,不过这里先介绍一个特性,关于反射的再补充. 我们来看一个方法: public virtual ActionResult Insert(T info) 有一个 ...
- 搜索引擎:Elasticsearch与Solr
搜索引擎选型调研文档 Elasticsearch简介* Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助你用前所未有的速度去处理大规模数据. 它可以用于全文搜索,结构化搜索以及分 ...
- RabbitMQ入门介绍
1.关于AMQP协议 AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设 ...
- windows命令快捷启动应用-----window小技巧
前言 装逼的道路总是这么漫长 而又充满激情.对于崇尚技术的男儿,了解计算机的世界,是我一辈子都是在追寻的.看着各种黑客电影,有那个大牛还需要鼠标的辅助,想想都是那么的令人兴奋 为了有那么一天的到来,我 ...