Hadoop HBase概念学习系列之HRegion服务器(三)
所有的数据库数据一般是保存在Hadoop分布式系统上面的,用户通过一系列HRegion服务器获取这些数据。一台机器上一般只运行一个HRegion服务器,而且每一分区段的HRegion也只会被一个HRegion服务器维护。
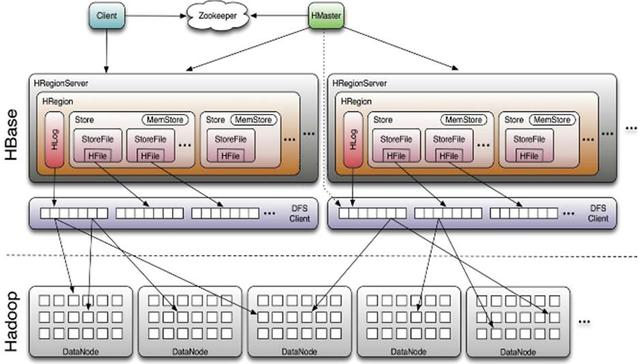
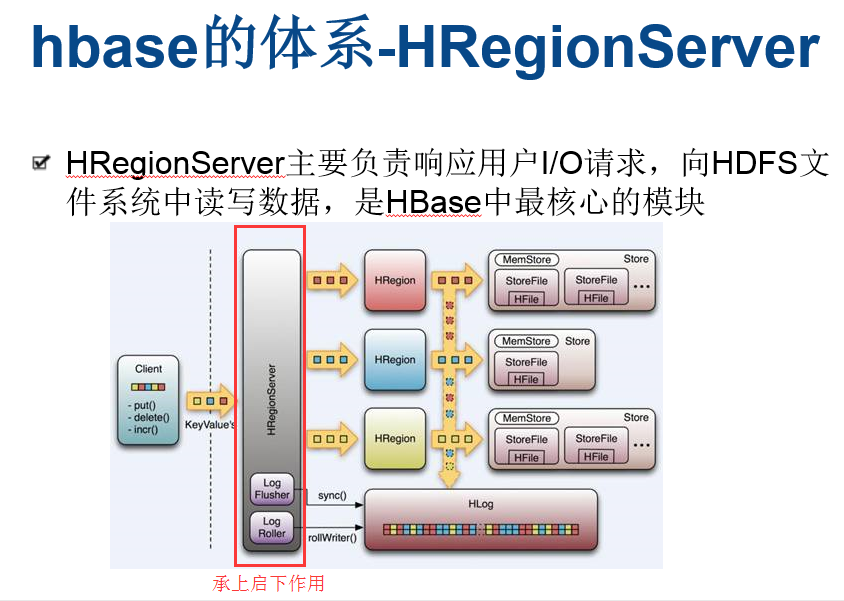
HRegion服务器包含两大部分:HLog部分和HRegion部分。
HRegion服务器在它这里面,又相当于是个小组长。
其中HLog用来存储数据日志,采用的是先写日志的方式。HRegion部分由很多的HRegion组成,存储的是实际的数据。每一个HRegion又由很多的Store组成,每一个Store存储的实际上是一个列簇(ColumnFamily)下的数据。此外,在每一个HStore(又名Store)中有包含一块MemStore。MemStore驻留在内存中,数据到来时首先更新到MemStore中,当到达阔值之后再更新到对应的StoreFile(又名HFile)中。每一个Store包含了多个StoreFile,StoreFile负责的是实际数据存储,为HBase中最小的存储单元。
HBase中不涉及数据的直接删除和更新操作,所有的数据均通过追加的方式进行更新。数据的删除和更新在HBase合并的时候进行。当Store中StoreFile的数量超过设定的阔值时将触发合并操作,该合并操作把多个StoreFile文件合并成一个StoreFile。
当用户需要更新数据的时候,数据会被分配到对应的HRegion服务器上提交修改。数据首先被提交到HLog文件里面,在操作写入HLog之后,commit()调用才会将其返回给客户端。HLog文件用于故障恢复。例如某一台HRegionServer发生故障,那么它所维护的HRegion会被重新分配到新的机器上。这是HLog会按照HRegion进行划分。新的机器在加载HRegion的时候可以通过HLog对数据进行恢复。
当一个HRegion变得太过巨大,超过了设定的阔值时,HRegion服务器会调用HRegion.closeAndSplit(),将此HRegion拆分为两个,并且报告给主服务器让它决定由哪台HRegion服务器来存放新的HRegion。这个拆分过程十分迅速,因为两个新的HRegion最初只是保留原来HRegionFile文件的引用。这时旧的HRegion会处于停止服务的状态,当新的HRegion拆分完成并且把引用删除了以后,旧的HRegion才会删除。另外,HRegion可以通过调用HRegion.clodeAndMerge()合并成一个新的HRegion,当前版本下进行此操作需要两台HRegion服务器都停机。
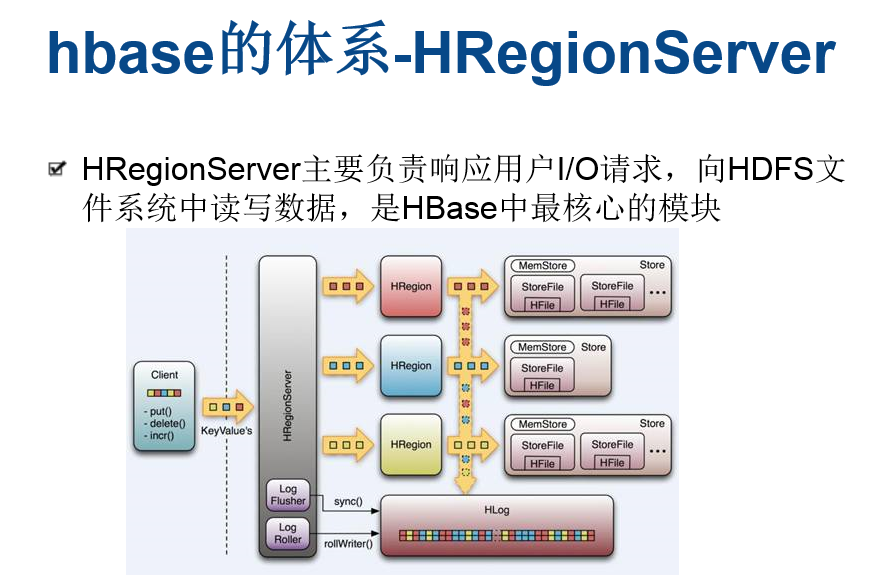

Hadoop HBase概念学习系列之HRegion服务器(三)的更多相关文章
- Hadoop HBase概念学习系列之HMaster服务器(四)
每台HRegion服务器都会和HMaster服务器通信,HMaster的主要任务就是告诉每个HRegion服务器它要维护哪些HRegion. 当一台新的HRegion服务器登录到HMaster服务器时 ...
- Hadoop HBase概念学习系列之HBase里的HRegion(五)
首先,要区分,HRegion服务器包含两大部分:HLog部分和HRegion部分 HBase里的HRegion服务器 HBase里的HRegion 当表的大小超过设置值的时候,HBase会自动将表划 ...
- Hadoop HBase概念学习系列之META表和ROOT表(六)
在 HBase里的HRegion 里,谈过,HRegion是按照表名+开始/结束主键,即表名+主键范围来区分的.由于主键范围是连续的,所以一般用开始主键就可以表示相应的HRegion了. 不过,因为我 ...
- Hadoop HBase概念学习系列之HLog(二)
首先,明确,HRegion服务器包含两大部分:HLog和HRegion. HLog用来存储数据日志,采用的是先写日志的方式. 当用户需要更新数据的时候,数据会被分配到对应的HRegion服务器上提交修 ...
- Hadoop HBase概念学习系列之HBase里的4维坐标系统(第一步定位行键 -> 第二步定位列簇 -> 第三步定位列修饰符 -> 第四步定位时间戳)(十八)
HBase里的4维坐标系统(第一步定位行键 -> 第二步定位列簇 -> 第三步定位列修饰符 -> 第四步定位时间戳) HBase里的4维坐标系统(第一步定位行键 ...
- Hadoop HBase概念学习系列之HBase里的客户端和HBase集群建立连接(详细)(十四)
需要遵循以下步骤: 1.客户端和Zookeeper集群建立连接.在这之前客户端需要获得一些信息(可以从HBase配置文件中读取或是直接指定).客户端从Zookeeper集群中读取-ROOT-表的位置信 ...
- Hadoop HBase概念学习系列之HBase里的宽表设计概念(表设计)(二十七)
在下面这篇博文里,我给各位博客们,分享了创建HBase表,但这远不止打好基础. HBase编程 API入门系列之create(管理端而言)(8) 在关系型数据库里,表的高表和宽表是不存在的.在如HBa ...
- Hadoop HBase概念学习系列之优秀行键设计(十六)
我们通过行键访问HBase.尽管使用扫描过滤器可以一次性指明大量的键,但是HBase仅仅能够根据行键识别出一行. 优秀的行键设计可以保证良好的HBase性能. 1.行键存在于HBase中的每一个单元格 ...
- Hadoop HBase概念学习系列之HBase里的高表设计概念(表设计)(二十八)
在下面这篇博文里,我给各位博客们,分享了创建HBase表,但这远不止打好基础. HBase编程 API入门系列之create(管理端而言)(8) 在关系型数据库里,表的高表和宽表是不存在的.在如HBa ...
随机推荐
- Maven的默认中央仓库
当构建一个Maven项目时,首先检查pom.xml文件以确定依赖包的下载位置,执行顺序如下: 1.从本地资源库中查找并获得依赖包,如果没有,执行第2步. 2.从Maven默认中央仓库中查找并获得依赖包 ...
- python3.X出现关于模块(i18n)的不能使用的解决方法
今天在看python编程从入门到实践的时候,遇到了 如下问题 ModuleNotFoundError: No module named 'pygal.i18n' 然后查找文献找到一个网友 的解决 ...
- Java Web 项目简单配置 Spring MVC进行访问
所需要的 jar 包下载地址: https://download.csdn.net/download/qq_35318576/10275163 配置一: 新建 springmvc.xml 并编辑如下内 ...
- js实现四叉树算法
最近在看canvas动画方面教程,里面提到了采用四叉树检测碰撞.之前也看到过四叉树这个名词,但是一直不是很懂.于是就又找了一些四叉树方面的资料看了看,做个笔记,就算日后忘了,也可以回来看看. Quad ...
- HDU 3613 Best Reward(KMP算法求解一个串的前、后缀回文串标记数组)
题目链接: https://cn.vjudge.net/problem/HDU-3613 After an uphill battle, General Li won a great victory. ...
- 从零开始学JAVA(09)-使用SpringMVC4 + Mybatis + MySql 例子(注解方式开发)
项目需要,继续学习springmvc,这里加入Mybatis对数据库的访问,并写下一个简单的例子便于以后学习,希望对看的人有帮助.上一篇被移出博客主页,这一篇努力排版整齐,更原创,希望不要再被移出主页 ...
- JS DOM操作(三) Window.docunment对象——操作属性
属性:是对象的性质与对象之间关系的统称.HTML中标签可以拥有属性,属性为 HTML 元素提供附加信. 属性总是以名称/值对的形式出现,比如:name="value". 属性值始终 ...
- [android] 手机卫士号码归属地查询
使用小米号码归属地数据库,有两张表data1和data2 先查询data1表,把手机号码截取前7位 select outkey from data1 where id=”前七位手机号” 再查询data ...
- SQL Server 如何添加删除外键、主键,以及更新自增属性
1.添加删除主键和外键 例如: -----删除主键约束DECLARE @NAME SYSNAMEDECLARE @TB_NAME SYSNAMESET @TB_NAME = 'Date'SELECT ...
- python3爬虫(find_all用法等)
#read1.html文件 # <html><head><title>The Dormouse's story</title></head> ...