Spark 实践——用 Scala 和 Spark 进行数据分析
本文基于《Spark 高级数据分析》第2章 用Scala和Spark进行数据分析。
完整代码见 https://github.com/libaoquan95/aasPractice/tree/master/c2/Into
1.获取数据集
数据集来自加州大学欧文分校机器学习资料库(UC Irvine Machine Learning Repository),这个资料库为研究和教学提供了大量非常好的数据源, 这些数据源非常有意义,并且是免费的。 我们要分析的数据集来源于一项记录关联研究,这项研究是德国一家医院在 2010 年完成的。这个数据集包含数百万对病人记录,每对记录都根据不同标准来匹配,比如病人姓名(名字和姓氏)、地址、生日。每个匹配字段都被赋予一个数值评分,范围为 0.0 到 1.0, 分值根据字符串相似度得出。然后这些数据交由人工处理,标记出哪些代表同一个人哪些代表不同的人。 为了保护病人隐私,创建数据集的每个字段原始值被删除了。病人的 ID、 字段匹配分数、匹配对标示(包括匹配的和不匹配的)等信息是公开的,可用于记录关联研究
下载地址:
- http://bit.ly/1Aoywaq (需翻墙)
- https://github.com/libaoquan95/aasPractice/tree/master/c2/linkage(已解压,block_1.csv 到 block_10.csv)
2.设置Spark运行环境,读取数据
val sc = SparkSession.builder().appName("Into").master("local").getOrCreate()
import sc.implicits._
读取数据集
// 数据地址
val dataDir = "inkage/block_*.csv"
// 读取有头部标题的CSV文件,并设置空值
val parsed = sc.read .option("header", "true") .option("nullValue", "?") .option("inferSchema", "true") .csv(dataDir)
// 查看表
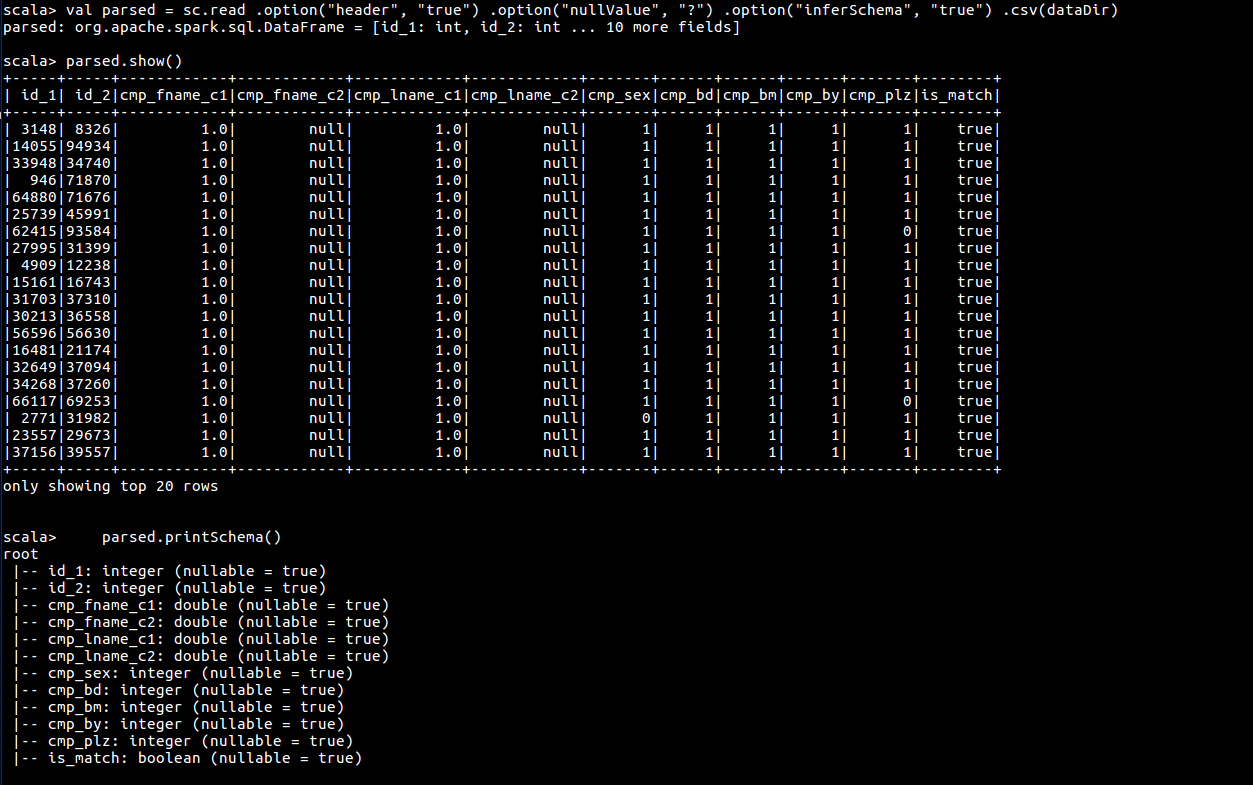
parsed.show()
// 查看表结构
parsed.printSchema()
parsed.cache()
3.处理数据
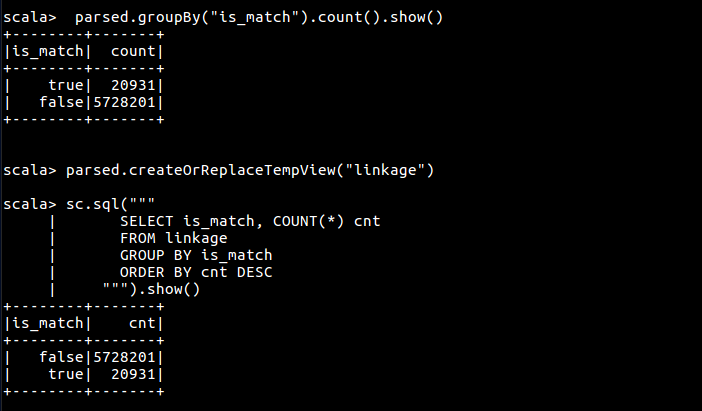
首先按 is_match 字段聚合数据,有两种方式可以进行数据聚合,一是使用 groupby 函数,二是使用 Spark Sql
// 聚合
parsed.groupBy("is_match").count().orderBy($"count".desc).show()
// 先注册为临时表
parsed.createOrReplaceTempView("linkage")
// 使用sql查询,效果同上
sc.sql("""
SELECT is_match, COUNT(*) cnt
FROM linkage
GROUP BY is_match
ORDER BY cnt DESC
""").show()
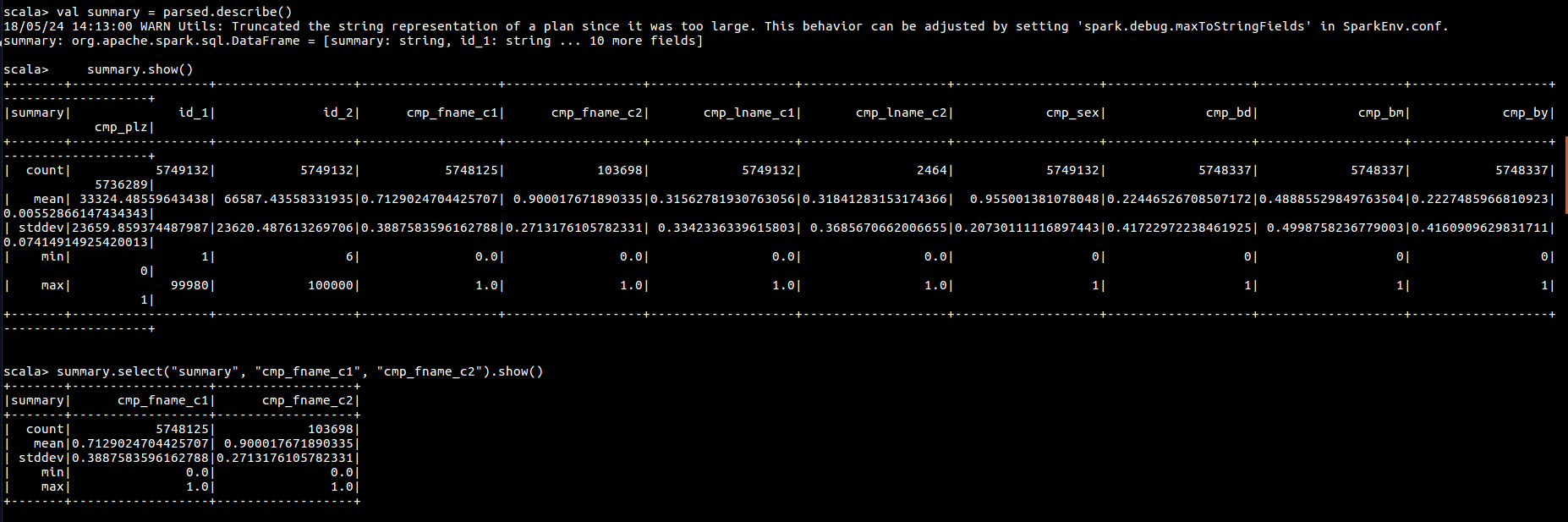
之后使用 describe 函数获取每个字段的最值,均值等信息
// 获取每一列的最值,平均值信息
val summary = parsed.describe()
summary.show()
summary.select("summary", "cmp_fname_c1", "cmp_fname_c2").show()
按此方式获取匹配记录和不匹配记录的 describe
// 获取匹配和不匹配的信息
val matches = parsed.where("is_match = true")
val misses = parsed.filter($"is_match" === false)
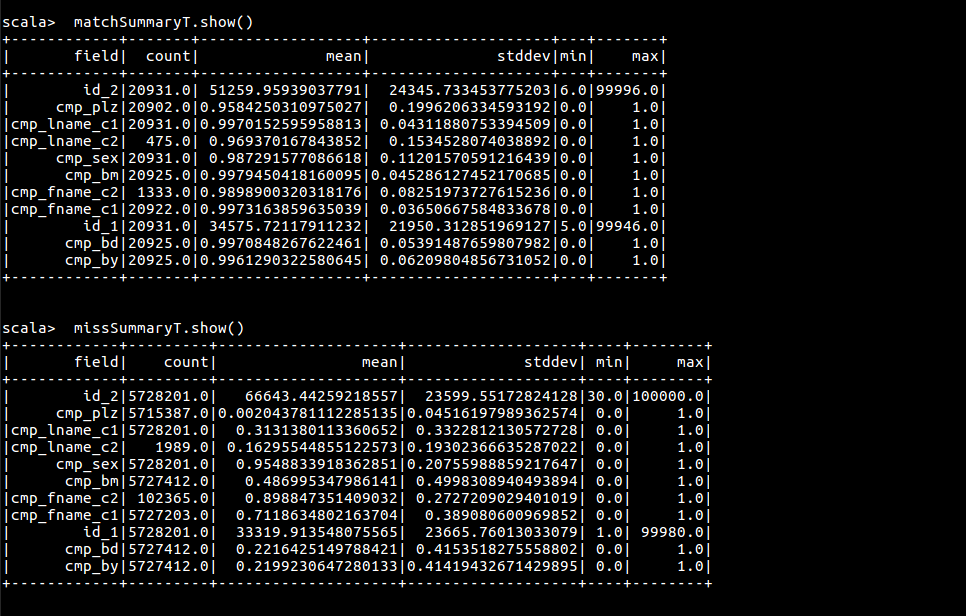
val matchSummary = matches.describe()
val missSummary = misses.describe()
matchSummary .show()
missSummary .show()
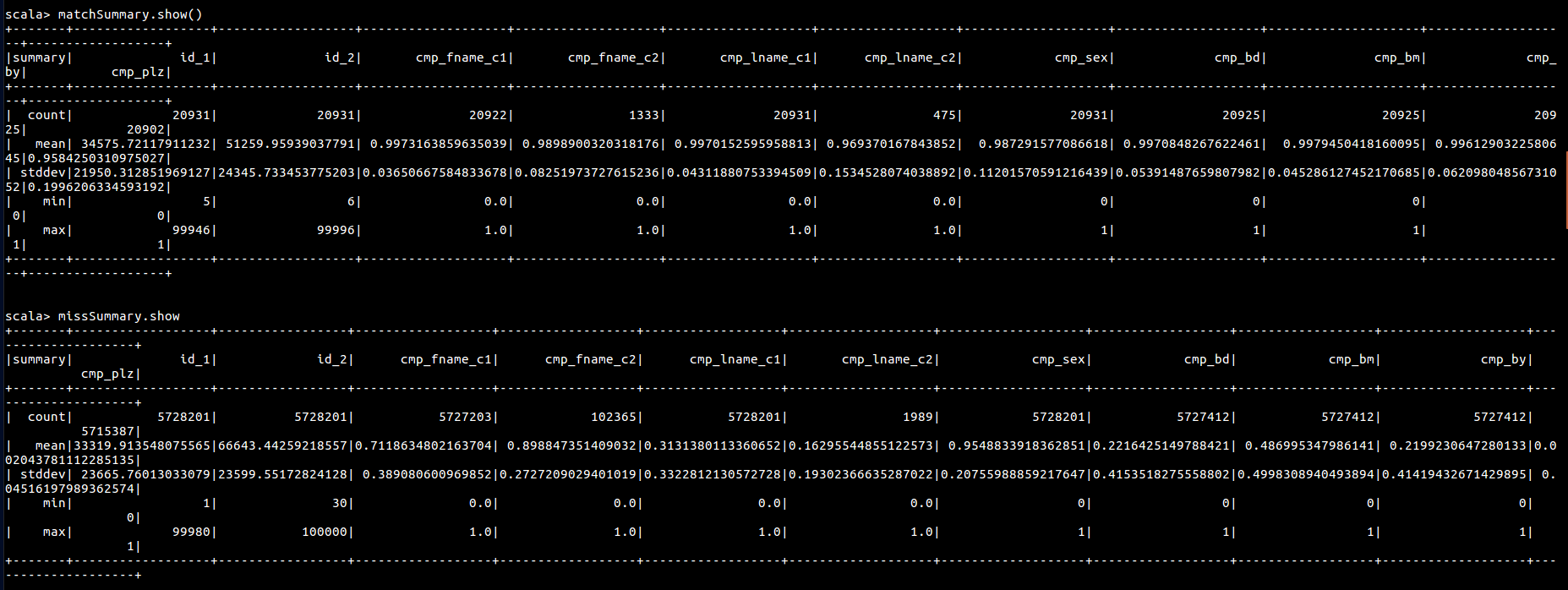
可以看到这个数据不方便进行操作,可以考虑将其转置,方便使用sql对数据进行分析
def longForm(desc: DataFrame): DataFrame = {
import desc.sparkSession.implicits._ // For toDF RDD -> DataFrame conversion
val schema = desc.schema
desc.flatMap(row => {
val metric = row.getString(0)
(1 until row.size).map(i => (metric, schema(i).name, row.getString(i).toDouble))
})
.toDF("metric", "field", "value")
}
def pivotSummary(desc: DataFrame): DataFrame = {
val lf = longForm(desc)
lf.groupBy("field").
pivot("metric", Seq("count", "mean", "stddev", "min", "max")).
agg(first("value"))
}
// 转置,重塑数据
val matchSummaryT = pivotSummary(matchSummary)
val missSummaryT = pivotSummary(missSummary)
matchSummaryT.createOrReplaceTempView("match_desc")
missSummaryT.createOrReplaceTempView("miss_desc")
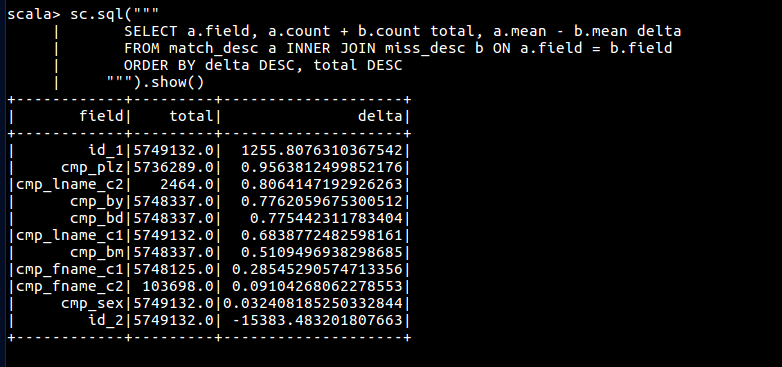
sc.sql("""
SELECT a.field, a.count + b.count total, a.mean - b.mean delta
FROM match_desc a INNER JOIN miss_desc b ON a.field = b.field
ORDER BY delta DESC, total DESC
""").show()
Spark 实践——用 Scala 和 Spark 进行数据分析的更多相关文章
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- Spark实践的阶段性总结
写这篇小总结是因为前段时间是自己业余时间对Spark相关进行了些探索,接下来可能有别的同事一起加入,且会去借用一些别的服务器资源,希望可以借此理下思路. 实践Spark的原因 在之前Spark简介及安 ...
- Spark 实践——基于 Spark Streaming 的实时日志分析系统
本文基于<Spark 最佳实践>第6章 Spark 流式计算. 我们知道网站用户访问流量是不间断的,基于网站的访问日志,即 Web log 分析是典型的流式实时计算应用场景.比如百度统计, ...
- Spark简单介绍,Windows下安装Scala+Hadoop+Spark运行环境,集成到IDEA中
一.前言 近几年大数据是异常的火爆,今天小编以java开发的身份来会会大数据,提高一下自己的层面! 大数据技术也是有很多: Hadoop Spark Flink 小编也只知道这些了,由于Hadoop, ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- 使用scala开发spark入门总结
使用scala开发spark入门总结 一.spark简单介绍 关于spark的介绍网上有很多,可以自行百度和google,这里只做简单介绍.推荐简单介绍连接:http://blog.jobbole.c ...
- idea中使用scala运行spark出现Exception in thread "main" java.lang.NoClassDefFoundError: scala/collection/GenTraversableOnce$class
idea中使用scala运行spark出现: Exception in thread "main" java.lang.NoClassDefFoundError: scala/co ...
- 个推 Spark实践教你绕过开发那些“坑”
Spark作为一个开源数据处理框架,它在数据计算过程中把中间数据直接缓存到内存里,能大大提高处理速度,特别是复杂的迭代计算.Spark主要包括SparkSQL,SparkStreaming,Spark ...
- Spark集群搭建【Spark+Hadoop+Scala+Zookeeper】
1.安装Linux 需要:3台CentOS7虚拟机 IP:192.168.245.130,192.168.245.131,192.168.245.132(类似,尽量保持连续,方便记忆) 注意: 3台虚 ...
随机推荐
- NOIP模拟赛-2018.11.5
NOIP模拟赛 好像最近每天都会有模拟赛了.今天从高二逃考试跑到高一机房,然而高一也要考试,这回好像没有拒绝的理由了. 今天的模拟赛好像很有技术含量的感觉. T1:xgy断句. 好诡异的题目,首先给出 ...
- BZOJ2095:[POI2010]Bridges(最大流,欧拉图)
Description YYD为了减肥,他来到了瘦海,这是一个巨大的海,海中有n个小岛,小岛之间有m座桥连接,两个小岛之间不会有两座桥,并且从一个小岛可以到另外任意一个小岛.现在YYD想骑单车从小岛1 ...
- 宿主在Windows Service中的WCF(创建,安装,调用) (host到exe,非IIS)
1. 创建WCF服务 在vs2010中创建WCF服务应用程序,会自动生成一个接口和一个实现类:(IService1和Service1) IService1接口如下: using System.Ru ...
- 【题解】[HNOI2008]神奇的国度—BZOJ1006。
之前说顺着打BZOJ结果又被自己给鸽了qwq. ------------------------------------ 言归正传这道题应该怎么做. 先给大家普及一下弦图(连接环上俩个不相邻节点的边称 ...
- <数据结构与算法分析>读书笔记--函数对象
关于函数对象,百度百科对它是这样定义的: 重载函数调用操作符的类,其对象常称为函数对象(function object),即它们是行为类似函数的对象.又称仿函数. 听起来确实很难懂,通过搜索我找到一篇 ...
- Android开发-各种各样好看漂亮的进度条,指示器,加载提示汇总
导读:之前项目中用到一些进度条,找了不少,打算写个demo自己总结一下,留着以后用, 有些是自己写的,有些是github上找的别人的库,如果大家觉得好看可以用,直接下载复制代码到项目里就可以用,ok ...
- Docker学习4-Containers - 容器
用Docker方式构建应用程序,从这个应用程序层次结构的底层容器开始.高于此级别的是一项服务,它定义了容器在生产中的行为方式.在顶层是堆栈,它定义了所有服务的交互. Stack 堆栈 Service ...
- Android 将拼接好并加上边框的图片保存到内存卡中
通过前两篇文章,问们学会了怎样拼接图片.给拼接好的图片加上边框样式,但这还不够,忙活了大半天 终于拼接好并给图片美化了,但是程序一旦推出,之前做的工作都白费了.这时我们会想,能不能把拼接好的图片保存起 ...
- AI1.1-人工智能史
来自:http://zh.wikipedia.org/wiki/人工智能史#CITEREFBerlinski2000 这篇是来自维基百科上面的人工智能史,将其大部分保留(真的是大部分,所以差不多没有原 ...
- 例子:照片的OCR识别
来自ng的ml-003中 18_XVIII._Application_Example-_Photo_OCR 这是ng2013年在coursera上最后的一课了.这一系列的几个视频还是相比前面有些难懂, ...