源码浅入浅出 Java ConcurrentHashMap
从源码的角度深入地分析了 ConcurrentHashMap 这个线程安全的 HashMap,希望能够给你一些帮助。
老读者就请肆无忌惮地点赞吧,微信搜索【沉默王二】关注这个在九朝古都洛阳苟且偷生的程序员。
本文 GitHub github.com/itwanger 已收录,里面还有我精心为你准备的一线大厂面试题。
HashMap 是 Java 中非常强大的数据结构,使用频率非常高,几乎所有的应用程序都会用到它。但 HashMap 不是线程安全的,不能在多线程环境下使用,该怎么办呢?
1)Hashtable,一个老掉牙的同步哈希表,t 竟然还是小写的,一看就非常不专业:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
public synchronized V put(K key, V value) {}
public synchronized int size() {}
public synchronized V get(Object key) {}
}
里面的方法全部是 synchronized,同步的力度非常大,对不对?这样的话,性能就没法保证了。pass。
2)Collections.synchronizedMap(new HashMap<String, String>()),可以把一个 HashMap 包装成同步的 SynchronizedMap:
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
public int size() {
synchronized (mutex) {return m.size();}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
}
可以看得出,SynchronizedMap 确实比 Hashtable 改进了,synchronized 不再放在方法上,而是放在方法内部,作为同步块出现,但仍然是对象级别的同步锁,读和写操作都需要获取锁,本质上,仍然只允许一个线程访问,其他线程被排斥在外。
3)ConcurrentHashMap,本篇的主角,唯一正确的答案。Concurrent 这个单词就是并发、并行的意思,所以 ConcurrentHashMap 就是一个可以在多线程环境下使用的 HashMap。
ConcurrentHashMap 一直在进化,Java 7 和 Java 8 就有很大的不同。Java 7 版本的 ConcurrentHashMap 是基于分段锁的,就是将内部分成不同的 Segment(段),每个段里面是 HashEntry 数组。
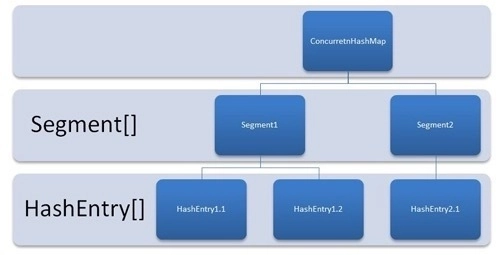
来看一下 Segment:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}
再来看一下 HashEntry:
static final class HashEntry<K,V> {
final K key; // 声明 key 为 final 型
final int hash; // 声明 hash 值为 final 型
volatile V value; // 声明 value 为 volatile 型
final HashEntry<K,V> next; // 声明 next 为 final 型
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
}
和 HashMap 非常相似,唯一的区别就是 value 是 volatile 的,保证 get 时候的可见性。
Segment 继承自 ReentrantLock,所以不会像 Hashtable 那样不管是 put 还是 get 都需要 synchronized,锁的力度变小了,每个线程只锁一个 Segment,对其他线程访问的 Segment 没有影响。
Java 8 和之后的版本在此基础上做了很大的改进,不再采用分段锁的机制了,而是利用 CAS(Compare and Swap,即比较并替换,实现并发算法时常用到的一种技术)和 synchronized 来保证并发,虽然内部仍然定义了 Segment,但仅仅是为了保证序列化时的兼容性,代码注释上就可以看得出来:
/**
* Stripped-down version of helper class used in previous version,
* declared for the sake of serialization compatibility.
*/
static class Segment<K,V> extends ReentrantLock implements Serializable {
final float loadFactor;
Segment(float lf) { this.loadFactor = lf; }
}
底层结构和 Java 7 也有所不同,更接近 HashMap(数组+双向链表+红黑树):
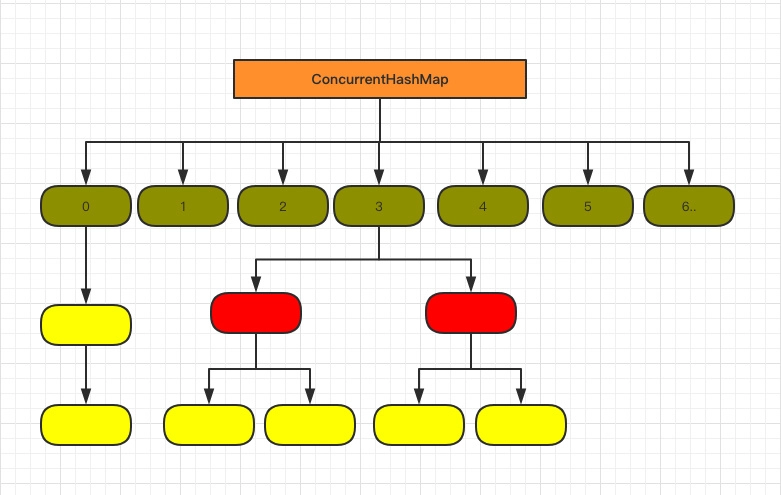
来看一下新版 ConcurrentHashMap 定义的关键字段:
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
transient volatile Node<K,V>[] table;
private transient volatile Node<K,V>[] nextTable;
private transient volatile int sizeCtl;
}
1)table,默认为 null,第一次 put 的时候初始化,默认大小为 16,用来存储 Node 节点,扩容时大小总是 2 的幂次方。
顺带看一下 Node 的定义:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
// …
}
hash 和 key 是 final 的,和 HashMap 的 Node 一样,因为 key 是不会发生变化的。val 和 next 是 volatile 的,保证多线程环境下的可见性。
2)nextTable,默认为 null,扩容时新生成的数组,大小为原数组的两倍。
3)sizeCtl,默认为 0,用来控制 table 的初始化和扩容操作。-1 表示 table 正在初始化;-(1+线程数) 表示正在被多个线程扩容。
Map 最重要的方法就是 put,ConcurrentHashMap 也不例外:
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
...省略部分代码
}
addCount(1L, binCount);
return null;
}
1)spread() 是一个哈希算法,和 HashMap 的 hash() 方法类似:
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
2)如果是第一次 put 的话,会调用 initTable() 对 table 进行初始化。
private final ConcurrentHashMap.Node<K,V>[] initTable() {
ConcurrentHashMap.Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
ConcurrentHashMap.Node<K,V>[] nt = (ConcurrentHashMap.Node<K,V>[])new ConcurrentHashMap.Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
外层用了一个 while 循环,如果发现 sizeCtl 小于 0 的话,就意味着其他线程正在初始化,yield 让出 CPU。
第一次 put 的时候会执行 U.compareAndSetInt(this, SIZECTL, sc, -1),把 sizeCtl 赋值为 -1,表示当前线程正在初始化。
private static final Unsafe U = Unsafe.getUnsafe();
private static final long SIZECTL
= U.objectFieldOffset(ConcurrentHashMap.class, "sizeCtl");
U 是一个 Unsafe(可以提供硬件级别的原子操作,可以获取某个属性在内存中的位置,也可以修改对象的字段值)对象,compareAndSetInt() 是 Unsafe 的一个本地(native)方法,它就负责把 ConcurrentHashMap 的 sizeCtl 修改为指定的值(-1)。
初始化后的 table 大小为 16(DEFAULT_CAPACITY)。
不是第一次 put 的话,会调用 tabAt() 取出 key 位置((n - 1) & hash)上的值(f):
static final <K,V> ConcurrentHashMap.Node<K,V> tabAt(ConcurrentHashMap.Node<K,V>[] tab, int i) {
return (ConcurrentHashMap.Node<K,V>)U.getReferenceAcquire(tab, ((long)i << ASHIFT) + ABASE);
}
U.getReferenceAcquire() 会调用 Unsafe 的 本地方法 getReferenceVolatile() 获取指定内存中的数据,保证每次拿到的数据都是最新的。
如果 f 为 null,说明 table 中这个位置上是第一次 put 元素,调用 casTabAt() 插入 Node。
static final <K,V> boolean casTabAt(ConcurrentHashMap.Node<K,V>[] tab, int i,
ConcurrentHashMap.Node<K,V> c, ConcurrentHashMap.Node<K,V> v) {
return U.compareAndSetReference(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
如果 CAS 成功,说明 Node 插入成功,执行 addCount() 方法检查是否需要扩容。
如果失败,说明有其他线程提前插入了 Node,进行下一轮 for 循环继续尝试,俗称自旋。
如果 f 的 hash 为 MOVED(-1),意味着有其他线程正在扩容,执行 helpTransfer() 一起扩容。
否则,把 Node 按链表或者红黑树的方式插入到合适的位置,这个过程是通过 synchronized 块实现的。
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
1)插入之前,再次调用 tabAt(tab, i) == f 来判断 f 是否被其他线程修改。
2)如果 fh(f 的哈希值) >= 0,说明 f 是链表的头节点,遍历链表,找到对应的 Node,更新值,否则插入到末尾。
3)如果 f 是红黑树,则按照红黑树的方式插入或者更新节点。
分析完 put() 方法后,再来看 get() 方法:
public V get(Object key) {
ConcurrentHashMap.Node<K,V>[] tab; ConcurrentHashMap.Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
是不是简单很多?
1)如果哈希值相等((eh = e.hash) == h),直接返回 table 数组中的元素。
2)如果是红黑树(eh < 0),按照红黑树的方式 find 返回。
3)如果是链表,进行遍历,然后根据 key 获取 value。
最后,来写一个 ConcurrentHashMap 的应用实例吧!
/**
* @author 沉默王二,一枚有趣的程序员
*/
public class ConcurrentHashMapDemo {
public final static int THREAD_POOL_SIZE = 5;
public static void main(String[] args) throws InterruptedException {
Map<String, String> map = new ConcurrentHashMap<>();
long startTime = System.nanoTime();
ExecutorService crunchifyExServer = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
for (int j = 0; j < THREAD_POOL_SIZE; j++) {
crunchifyExServer.execute(new Runnable() {
@SuppressWarnings("unused")
@Override
public void run() {
for (int i = 0; i < 500000; i++) {
map.put("itwanger"+i, "沉默王二");
}
}
});
}
crunchifyExServer.shutdown();
crunchifyExServer.awaitTermination(Long.MAX_VALUE, TimeUnit.DAYS);
long entTime = System.nanoTime();
long totalTime = (entTime - startTime) / 1000000L;
System.out.println(totalTime + "ms");
}
}
给同学们留一道作业题,感兴趣的话可以尝试下,把 ConcurrentHashMap 换成 SynchronizedMap,比较一下两者性能上的差异,差距还是挺明显的。
我是沉默王二,一枚在九朝古都洛阳苟且偷生的程序员。关注即可提升学习效率,感谢你的三连支持,奥利给。
注:如果文章有任何问题,欢迎毫不留情地指正。
如果你觉得文章对你有些帮助,欢迎微信搜索「沉默王二」第一时间阅读,回复关键字「小白」可以免费获取我肝了 4 万+字的 《Java 小白从入门到放肆》2.0 版;本文 GitHub github.com/itwanger 已收录,欢迎 star。
源码浅入浅出 Java ConcurrentHashMap的更多相关文章
- 浅入深出Java输入输出流主线知识梳理
Java把不同类型的输入.输出,这些输入输出有些是在屏幕上.有些是在电脑文件上, 都抽象为流(Stream) 按流的方向,分为输入流与输出流,注意这里的输出输出是相对于程序而言的,如:如对于一个J ...
- 浅入深出之Java集合框架(中)
Java中的集合框架(中) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- 浅入深出之Java集合框架(下)
Java中的集合框架(下) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,哈哈这篇其实也还是基础,惊不惊喜意不意外 ̄▽ ̄ 写文真的好累,懒得写了.. ...
- 浅入深出之Java集合框架(上)
Java中的集合框架(上) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- 浅入浅出 1.7和1.8的 HashMap
前言 HashMap 是我们最最最常用的东西了,它就是我们在大学中学习数据结构的时候,学到的哈希表这种数据结构.面试中,HashMap 的问题也是常客,现在卷到必须答出来了,是必须会的知识. 我在学习 ...
- Flink 反压 浅入浅出
前言 微信搜[Java3y]关注这个朴实无华的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创 ...
- 浅入深出Vue:环境搭建
浅入深出Vue:环境搭建 工欲善其事必先利其器,该搭建我们的环境了. 安装NPM 所有工具的下载地址都可以在导航篇中找到,这里我们下载的是最新版本的NodeJS Windows安装程序 下载下来后,直 ...
- 浅入深出Vue:工具准备之WebStorm安装配置
浅入深出Vue之工具准备(一):WebStorm安装配置 工欲善其事必先利其器,让我们先做好准备工作吧 导航篇 WebStorm安装配置 所有工具的下载地址都可以在导航篇中找到,这里我们下载的是最新版 ...
- 浅入深出Vue:代码整洁之封装
深入浅出vue系列文章已经更新过半了,在入门篇中我们实践了一个小小的项目. <代码整洁之道>一书中提到过一句话: 神在细节中 这句话来自20世纪中期注明现代建筑大师 路德维希·密斯·范·德 ...
- Spring浅入浅出——不吹牛逼不装逼
Spring浅入浅出——不吹牛逼不装逼 前言: 今天决定要开始总结框架了,虽然以前总结过两篇,但是思维是变化的,而且也没有什么规定说总结过的东西就不能再总结了,是吧.这次总结我命名为浅入浅出,主要在于 ...
随机推荐
- Java8的@sun.misc.Contended注解
@sun.misc.Contended 介绍 @sun.misc.Contended 是 Java 8 新增的一个注解,对某字段加上该注解则表示该字段会单独占用一个缓存行(Cache Line). 这 ...
- 使用DEBUG 读取主引导记录
实验环境:win7 64位(虚拟机) 由于此版本不能直接在命令行使用DOS,需要下载相关软件,参考https://www.cnblogs.com/caishunzhe/p/12823201.html ...
- markdown公式指导手册
#Cmd Markdown 公式指导手册 标签: Tutorial 转载于https://www.zybuluo.com/codeep/note/163962#1%E5%A6%82%E4%BD%95% ...
- NoisyStudent:
- 某大型企业ospf面试题分析(含路由策略和路由过滤,及双点双向重发布)
面试问题背景 本面试题来自国内最大通信技术公司之一,央企,有很多金融网项目. 了解行业的同学,一定知道事哪个企业. 上面试问题(取自百哥收集整理的面试总结大全,关注百哥CSDN或知乎,不定期分享名企面 ...
- C#LeetCode刷题之#11-盛最多水的容器(Container With Most Water)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3615 访问. 给定 n 个非负整数 a1,a2,...,an,每 ...
- C#LeetCode刷题-记忆化
记忆化篇 # 题名 刷题 通过率 难度 329 矩阵中的最长递增路径 31.0% 困难
- C#LeetCode刷题之#14-最长公共前缀(Longest Common Prefix)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3921 访问. 编写一个函数来查找字符串数组中的最长公共前缀. 如 ...
- JavaScript 手写 setTimeout 及 同步调用和异步调用
demo let timeout = (sec, num) => { const now = new Date().getTime() // 获取进入方法时的时间 let flag = true ...
- Vue 使用mixin抽取共通方法
引入原因: 当一段逻辑在不同的地方使用时 step-1: 定义mixin文件,methods里有一个handleToLink方法 /** * this mixin file will be used ...