Kylin Flink Cube 引擎的前世今生
Apache Kylin™ 是一个开源的、分布式的分析型数据仓库,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的表。
Kylin 的核心思想是”预计算“,将数据按照指定的维度和指标,预先计算出所有可能的查询结果,利用空间换时间来加速模式固定的 OLAP 查询。
Kylin 的理论基础是 Cube 理论,每一种维度组合称之为 Cuboid,所有 Cuboid 的集合称之为 Cube。如下图,整个立方体称为 1 个 Cube,立方体中每个网格点称为 1 个 Cuboid,图中 (A, B, C, D) 和 (A, D) 都是 Cuboid,其中 (A, B, C, D) 称为 Base Cuboid。
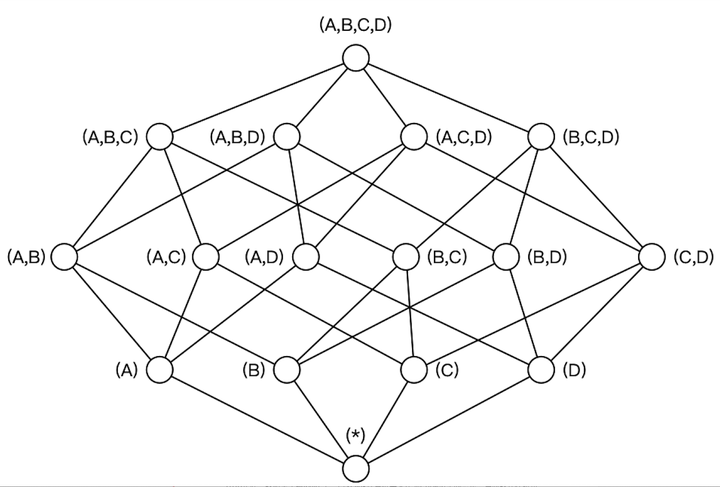
基于预计算的思想,Cuboid 需要提前算好并存储起来。由于 Kylin 的场景是面向海量规模的大数据分析,所以 Cube 的构建利用了大数据的计算框架,我们常将计算框架构建 Cube 的实现称之为“Cube 引擎“。在过去的很长一段时间,构建 Cube 时所能选择的引擎只能是 Spark 或者 Hadoop 的 MapReduce 框架。但随着 Kylin 3.1 版本的发布,我们将看到另一个 Cube 引擎正式加入到 Kylin 生态中:Kylin Flink Cube 引擎。在下文中,我们就来对 Flink 的 Cube 引擎做一个全面的介绍。
Flink Cube 引擎简介
2018 年底,我萌生了给 Kylin 写一个以 Flink 计算框架来作为 Cube 引擎的想法,当时我还在腾讯,主要从事 Flink 框架的研发。Flink 框架在当时已经不是大数据领域的一颗新星了,它基于 Google 的 DataFlow 模型以及 Streaming First 的设计理念要比 Spark 在流处理领域拥有先天的优势,而且已经被国内外众多公司所广泛使用。在释放计算能力方面,Spark 和 Flink 提供了相似的功能,都是大数据领域支持流和批的通用型计算引擎。既然 Spark 能作为 Kylin 的 Cube 引擎,那么 Flink 理论上没有理由不可以。
想要实现 Flink 的 Cube 引擎有两个初衷:
- 扩大 Flink 的生态;
- 满足腾讯内部统一流批计算引擎的需求(因为 Flink 是当时腾讯内部主推的流计算平台)。
当我跟 Kylin PMC 史少锋交流并提出这一想法后,他对此表示非常欢迎,这里我们必须要称赞一下 Kylin 社区对于接受新技术所持有的积极、开放的心态。
Flink Cube 引擎的开发就从 2019 年 1 月开始了,对我而言这是一个跨领域的过程,我需要从头了解 Kylin 以及 OLAP 领域的一些核心思想和概念(毕竟之前一直在做计算框架)以及 Kylin 和 Spark Cube 引擎的一些关键设计。
前后加起来差不多利用了数月的业余时间实现完成了整个实现。其中经历了数次调优,这里需要特别感谢 Kyligence 多位童鞋耐心、仔细地进行对比测试(尤其是 Kylin PMC 倪春恩和 Kyligence 的张亚倩童鞋),终于这个引擎的性能到了能够跟 Spark 相提并论的地步。
随后,我们在 6,7 月份开始在腾讯内部试点该引擎来构建 Cube,以支持 QQ 音乐、广点通等业务的分析需求。经过内部的试运行,我们观察到整体上它的性能表现要优于 Spark 的实现。然后,在 19 年 9 月的 Kylin 深圳 Meetup 上,我跟前同事程广旭共同分享了一个 Talk 介绍了 Kylin 在腾讯的落地实践以及 Flink Cube 引擎。[2]
跟 Kylin 的很多其他 Feature 一样,Flink Engine 最初也是在一个独立的分支上开发的,这个分支就是 engine-flink,2019 年底 Kylin 社区经过测试将该分支合并到了 master 分支。Flink Engine 最初使用的 Flink 版本是 1.7.2,后面升级到了 1.9.0。整个 Cube 引擎在 Jira 上有一个 Umbrella issue,编号是 KYLIN-3758[3],所有的子任务都在这个 issue 下面。
Flink Cube 引擎基于 Kylin 原先的插件化的架构,继承 IBatchCubingEngine 接口实现了 FlinkBatchCubingEngine2,是一个相对独立的模块,跟 Kylin 其他部件没有产生太多的耦合。它整体上延续了 Spark Cube 引擎的设计与实现,由于 Spark 跟 Flink 的 DataSet API 存在着一定程度的差异,所以在开发时需要进行一些适配工作。这里我们先介绍一下 Spark Cube 引擎的核心:”By layer“ 算法。Kylin 官方曾经出了一篇博客介绍 Spark Cube 引擎以及该算法的实现[1],以下是这篇博客里的一段文字摘录:
The “by-layer” Cubing divides a big task into a couple steps, and each step bases on the previous step’s output, so it can reuse the previous calculation and also avoid calculating from very beginning when there is a failure in between. These makes it as a reliable algorithm. When moving to Spark, we decide to keep this algorithm, that’s why we call this feature as “By layer Spark Cubing”.
简而言之,"By layer" 算法的核心思想是逐层计算 Cube ,首先计算 Base Cuboid,然后计算维度数依次减少,逐层向下计算每层的 Cuboid。
在实现时,Cube 的构建流程,包含若干个步骤。选择特定的构建引擎通常会使用相应的计算框架提供的 API 去实现这些步骤。由于这些步骤都是一个个独立的 YARN application,所以,也并不是一个 segment 构建任务里所有的子任务都一定要由同一个构建引擎的 API 来实现
接下来,介绍一下我们如何选择 Flink Cube 引擎来构建。我们在 Kylin 的 Web UI 上提供了 Flink Cube Engine 的选项,当用户编辑一个 Cube 信息时,可以在第五步 (Advanced Setting) 中的 Cube Engine 下拉选项中选择 “Flink”。
Cube 构建的若干步骤中,当属 ”Cuboid build“ 步骤最为耗时也最为关键。下面我们就来介绍一下,Flink Cube 引擎在对 ”Cuboid build" 步骤调优时有哪些考虑。
Flink Cube 引擎调优
其实,在最初进行对比测试时,Flink 引擎要比 Spark 引擎慢不少。我们发现性能问题后首先对 Flink 框架的参数进行了调优。这里除了内存外,有三个核心参数,分别是并行度、单个 TM Slot 的数目、TM Container 的数目。他们之间的关系是:TM Container 的数目 = 并行度 / 单个 TM Slot 的数目。我们基于控制变量法(固定住并行度以及 Job 总内存不变)尝试调整出一个 Container 数与单 TM Slot 数性能最好的配比。结果得出的结论是,单个 TM 的 Slot 数目减少(当然单个 TM 的内存也会降低),拉起更多的 Container 数目的这种摊平的方式性能会更好。除此之外,在 Flink 批处理模块,它有几个优化配置项,包括对象复用,内存预分配等,通过对比测试,所起到的效果并不明显。当然,仅仅对 Flink 框架的参数进行调优,并没有使得 Flink Cube 引擎的性能赶上 Spark Cube 引擎。接下来的一步优化也很关键:那就是合并/批量计算。通过分析 Flink Job 执行后的 ArchivedExecutionGraph,发现每一步都比较慢,且随着 Layer 的变化没有发生性能急剧下降的情况,基本维持了线性关系。于是,我认为问题应该还是在代码实现上,并不能完全照着 Spark 的方式来。所以,通过对整个 DAG 的重新分析,最终确认了性能瓶颈在于用于聚合 Cuboid 的 Reduce 算子以及对 Cuboid 进行 Encode 的 Map 算子上。
对于这两个算子,Flink 提供了相应的分组、分区的批量处理模式来提升整体处理的吞吐量,它们分别是 mapPartition/reduceGroup。它们会对上游的数据进行聚集,直到某分区的输入全部被接收,然后才会调用具体的 UDF 对数据进行迭代处理。当然,这两个算子也有它危险的地方,那就是它们很占用内存,数据量太大会存在内存耗尽从而导致 OOM 的风险。这一点,Flink 彻底的内存管理以及自定义类型系统的做法会有一些优势,它能够容纳更多的数据在内存中,并且有效地减少 GC 的频次,但仍然可能存在风险。所以,这一块的改进建议是引入一个场景化的开关:如果内存资源充足那么我们就可以尽量用这两个算子来降低构建时间,如果内存资源有限,那么我们可以选择更稳定的方式来构建。
Flink Cube & Spark Cube 引擎对比测试
- 对比步骤:两个计算引擎分别构建 Cuboid 数据;
- YARN 集群资源:4 个物理节点,每个物理节点 32 Core,125G 内存;
- 数据源:基于 SSB 数据集,事实表包含 6 千万记录。
结果如下:
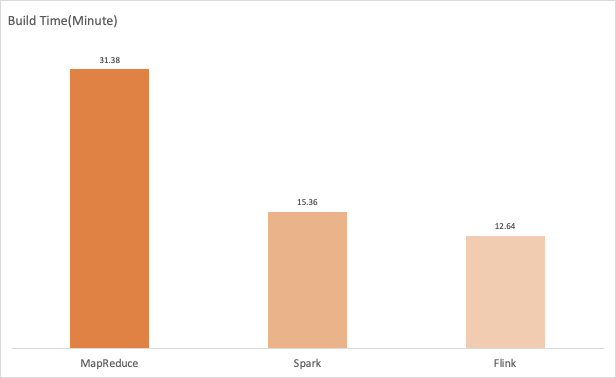
结论:Flink Engine在对比测试中已超过 2 mins + 的明显优势胜出。
*注:整个测试过程由 Kylin Committer 倪春恩实施并提供测试结果。
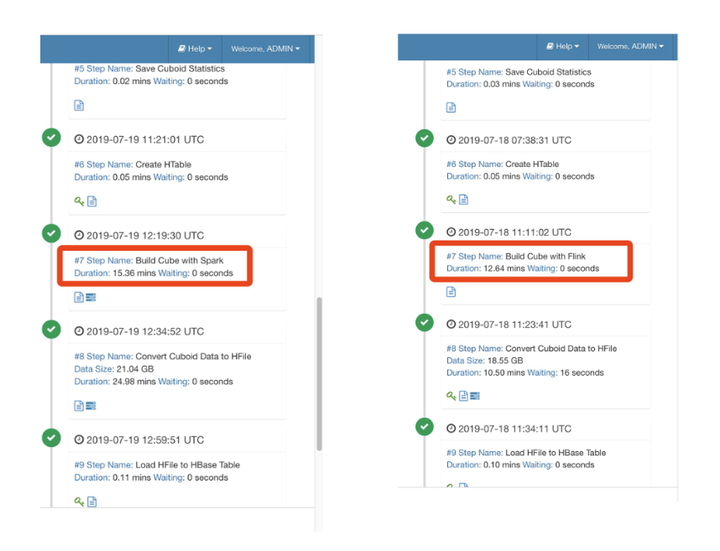
构建过程中的相关 UI 的截图如下:
两个 Engine 相关的配置信息如下:
Spark Cube Engine:
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
kylin.engine.spark-conf.spark.dynamicAllocation.enabled=true
kylin.engine.spark-conf.spark.dynamicAllocation.minExecutors=1
kylin.engine.spark-conf.spark.dynamicAllocation.maxExecutors=1000
kylin.engine.spark-conf.spark.dynamicAllocation.executorIdleTimeout=300
kylin.engine.spark-conf.spark.shuffle.service.enabled=true
kylin.engine.spark-conf.spark.hadoop.dfs.replication=2
kylin.engine.spark-conf.spark.driver.memory=4G
kylin.engine.spark-conf.spark.executor.memory=4G
kylin.engine.spark-conf.spark.executor.cores=1
kylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=1024
Flink Cube Engine:
kylin.engine.flink-conf.jobmanager.heap.size=2G
kylin.engine.flink-conf.taskmanager.heap.size=4G
kylin.engine.flink-conf.taskmanager.numberOfTaskSlots=4
kylin.engine.flink-conf.taskmanager.memory.preallocate=false
kylin.engine.flink-conf.job.parallelism=80
kylin.engine.flink-conf.program.enableObjectReuse=false
Flink 引擎后续规划
Flink Cube 引擎,随 Kylin 3.1 版本一起发布,这给了用户足够的信心来使用它。当然,由于维护精力受限,它还有一些不足和待改进的空间,我们很开心看到社区也有其他小伙伴将 Flink Cube 引擎在自己公司内使用并将相关的优化与改进反馈回 Kylin社区。例如,harveyyue 同学实现了 cubing step 中的 fact distinct 以及 convert to HFile 等子任务[2]。随着 Flink Cube 引擎被正式发布,我们有理由相信它能在 Kylin 生态中占有一席之地。
参考文献:
[1]: http://kylin.apache.org/blog/2017/02/23/by-layer-spark-cubing/
[2]: https://github.com/apache/kylin/commits?author=harveyyue
[3]: https://issues.apache.org/jira/browse/KYLIN-3758
作者简介:
杨华,T3 出行大数据平台负责人,前腾讯高级工程师。Apache Hudi Committer & PMC Member。Apache Kylin 的 Flink Cube Engine 作者。
*如果想第一时间获得 Kylin 的资讯和活动信息,请添加 K 小助 (微信号:uncertainly5)并备注您的 “所在城市-公司-岗位-昵称”。
Kylin Flink Cube 引擎的前世今生的更多相关文章
- Kylin的cube模型
1. 数据仓库的相关概念 OLAP 大部分数据库系统的主要任务是执行联机事务处理和查询处理,这种处理被称为OLTP(Online Transaction Processing, OLTP),面向的是顾 ...
- 【转】Kylin的cube模型
转自:http://www.cnblogs.com/en-heng/p/5239311.html 1. 数据仓库的相关概念 OLAP 大部分数据库系统的主要任务是执行联机事务处理和查询处理,这种处理被 ...
- Kylin引入Spark引擎
1 引入Spark引擎 Kylin v2开始引入了Spark引擎,可以在构建Cube步骤中替换MapReduce. 关于配置spark引擎的文档,下面给出官方链接以便查阅:http://kylin.a ...
- kylin构建cube优化
前言 下面通过对kylin构建cube流程的分析来介绍cube优化思路. 创建hive中间表 kylin会在cube构建的第一步先构建一张hive的中间表,该表关联了所有的事实表和维度表,也就是一张宽 ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Kylin构建Cube过程详解
1 前言 在使用Kylin的时候,最重要的一步就是创建cube的模型定义,即指定度量和维度以及一些附加信息,然后对cube进行build,当然我们也可以根据原始表中的某一个string字段(这个字段的 ...
- Kylin构建cube时状态一直处于pending
在安装好kylin之后我直接去访问web监控页面发现能够进去,也没有去看日志.然后在运行官方带的例子去bulid cube时去发现状态一直是pending而不是runing.这个时候才去查看日志: 2 ...
- 如何通过java代码对kylin进行cube build
通常是用于增量 代码如下: package com.dlht.kylinDemo; import java.io.BufferedReader; import java.io.FileNotFound ...
- 创建 kylin Module/Cube
1. 首先要创建 Project 2. 再把Hive 表加载进来: 3. 创建model 3.1. 首先选择或者创建一个project 3.2.创建一个新modle 3.3. 选择数据库 ...
随机推荐
- 《MapReduce: Simplified Data Processing on Large Clusters》论文研读
MapReduce 论文研读 说明:本文为论文 <MapReduce: Simplified Data Processing on Large Clusters> 的个人理解,难免有理解不 ...
- 你还在担心rpc接口超时吗
在使用dubbo时,通常会遇到timeout这个属性,timeout属性的作用是:给某个服务调用设置超时时间,如果服务在设置的时间内未返回结果,则会抛出调用超时异常:TimeoutException, ...
- axure8.0实现tab切换
这两天帮忙做产品原型图,tab切换做一次忘一次,这次索性记录一下,免得下次再忘了. 1.在元件库中拉出来一个动态面板,双击动态面板,添加状态,添加完成之后,点击红色标注的地方,开始编辑每个面板状态: ...
- 「杂烩」精灵魔法(P1908逆序对弱化版)
「杂烩」精灵魔法(P1908逆序对弱化版) 题面: 题目描述 \(Tristan\)解决了英灵殿的守卫安排后,便到达了静谧的精灵领地--\(Alfheim\) .由于$ Midgard$ 处在$ Al ...
- PCA算法 | 数据集特征数量太多怎么办?用这个算法对它降维打击!
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第27文章,我们一起来聊聊数据处理领域的降维(dimensionality reduction)算法. 我们都知道,图片 ...
- 武科WUST-CTF2020“Tiki组 ”
赛事信息 官网地址:https://ctfgame.w-ais.cn/参赛地址:https://ctfgame.w-ais.cn/起止时间:2020-03-27 18:00:00 - 2020-03- ...
- day51 作业
用html搭建一个注册页面 <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...
- pytest框架使用教程
Pytest框架 一.简介 pytest:基于unittest之上的单元测试框架 有什么特点? 自动发现测试模块和测试方法 断言更加方便,assert + 表达式,例如 assert 1 == 1 灵 ...
- [网鼎杯 2020 青龙组]AreUSerialz
题目分析 <?php include("flag.php"); highlight_file(FILE); class FileHandler { protected $op ...
- 数据可视化之powerBI技巧(四)使用Power BI制作帕累托图
各种复杂现象的背后,其实都是受关键的少数因素和普通的大多数因素所影响,把主要精力放在关键的少数因素上,就能达到事半功倍的效果. 这就是大家常说的二八原则,也称为帕累托原则,最早是由意大利经济学家 V. ...