python爬取QQVIP音乐
QQ音乐相比于网易云音乐加密部分基本上没有,但是就是QQ音乐的页面与页面之间的联系太强了,,导致下载一个音乐需要分析前面多个页面,找数据。。太繁琐了
1、爬取链接:https://y.qq.com/
首先随便找一个页面先点进去

2、点击播放歌曲会打开一个页面,按F12打开控制台,然后刷新页面并点击播放歌曲,network里面就会有数据包
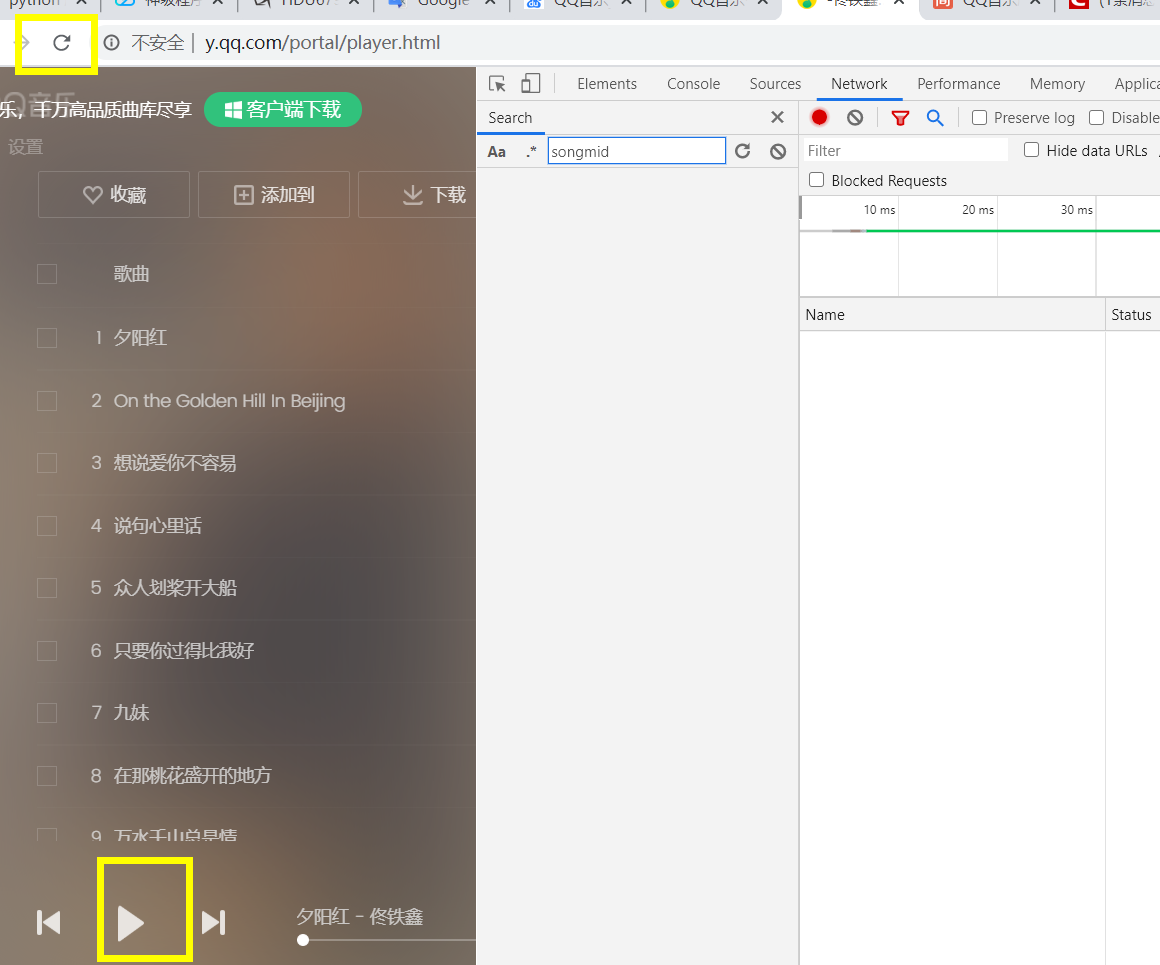
3、在控制台选中media,找到下图这样类型的文件,它的request url就是歌曲播放url,如下下图

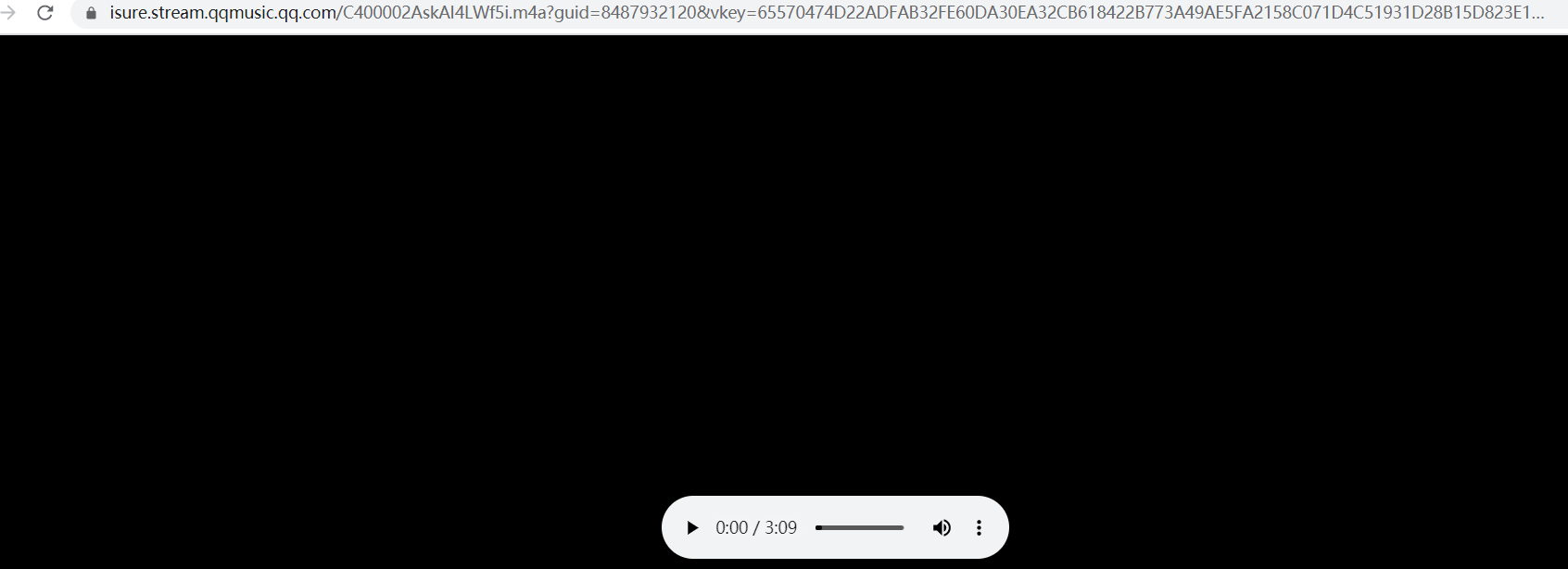
当然,我们肯定不能每下载一首歌都这样,一是这样很麻烦,二是遇到vip等音乐,你在线都不能播放,你还怎么找到歌曲链接
所以,分析页面是必然的!!!我们首先分析一下这个歌曲播放链接的url
https://isure.stream.qqmusic.qq.com/C400002AskAI4LWf5i.m4a?guid=8487932120&vkey=65570474D22ADFAB32FE60DA30EA32CB618422B773A49AE5FA2158C071D4C51931D28B15D823E1BA87BCA837EC09A0FCF8BD9E2763D46B91&uin=0&fromtag=66
我们对这个url进行删减(因为url有些部分都不需要,我们为了看起来更直观要对其进行处理)
#精简后url
https://isure.stream.qqmusic.qq.com/C400002AskAI4LWf5i.m4a?guid=8487932120&vkey=65570474D22ADFAB32FE60DA30EA32CB618422B773A49AE5FA2158C071D4C51931D28B15D823E1BA87BCA837EC09A0FCF8BD9E2763D46B91
我们大致一看它的url,就知道页面提交用get将参数guid和vkey追加到url地址后面,那么我们就要去找vkey和guid参数是怎么来的
guid参数:
你多打开几个歌曲就会发现它的guid都是一样的,所以这个我们就不用管
vkey参数:
这个参数难为死我了,我刚开始以为它和网易云音乐一样也是加密一下,然后我就去js文件里面找,找了半天没找到赋值语句,我就纳闷了,以为这是更高级的加密,,,,然后看了半天js,最后终于确定,js和这个没啥关系。。。。。。。
之后感觉分析页面分析不动了,上网找了篇博客给了我灵感,虽然那篇博客代码已经过时了,但是它启发了我 “播放歌曲的链接可能不止一个”
于是我又开始找vkey在哪个数据包出现过,如下图

我找到了vkey且对比了一下和之前链接上vkey的值一样,你再仔细看就会发现那个歌曲下载链接就是
https://isure.stream.qqmusic.qq.com/加上purl的值。(我giao!!)
然后就要去分析这个数据包的请求头了(呜呜呜~),请求头如下(好长~~~)
https://u.y.qq.com/cgi-bin/musics.fcg?-=getplaysongvkey6574047973093009&g_tk=1740745507&sign=zzaztgck8xaqpsxorw45ed952a339dbe91c7990f803cb9a6f1&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data=%7B%22req_0%22%3A%7B%22module%22%3A%22vkey.GetVkeyServer%22%2C%22method%22%3A%22CgiGetVkey%22%2C%22param%22%3A%7B%22guid%22%3A%228487932120%22%2C%22songmid%22%3A%5B%22003cGaJY10RAsX%22%5D%2C%22songtype%22%3A%5B0%5D%2C%22uin%22%3A%220%22%2C%22loginflag%22%3A1%2C%22platform%22%3A%2220%22%7D%7D%2C%22comm%22%3A%7B%22uin%22%3A0%2C%22format%22%3A%22json%22%2C%22ct%22%3A24%2C%22cv%22%3A0%7D%7D
这个时候我就遇到一个坑点(QQ音乐有毒),这么长的链接我们肯定要对其进行删减,好看看哪些参数有用,哪些参数用来混乱我们的视线
但是如果你前面的一段链接改为
https://u.y.qq.com/cgi-bin/musicu
你就能对很多参数进行删除,就最后一个字母不一样,但是对参数进行删除的时候前面那个链接就基本上参数都不能删除
这让我就很难受,我的访问链接就是
https://u.y.qq.com/cgi-bin/musics
这一部分,但是有些人访问链接是
https://u.y.qq.com/cgi-bin/musicu
化简之后链接就变成了
https://u.y.qq.com/cgi-bin/musicu.fcg?format=json&data=%7B%22req_0%22%3A%7B%22module%22%3A%22vkey.GetVkeyServer%22%2C%22method%22%3A%22CgiGetVkey%22%2C%22param%22%3A%7B%22guid%22%3A%22358840384%22%2C%22songmid%22%3A%5B%22{}%22%5D%2C%22songtype%22%3A%5B0%5D%2C%22uin%22%3A%221443481947%22%2C%22loginflag%22%3A1%2C%22platform%22%3A%2220%22%7D%7D%2C%22comm%22%3A%7B%22uin%22%3A%2218585073516%22%2C%22format%22%3A%22json%22%2C%22ct%22%3A24%2C%22cv%22%3A0%7D%7D".format(mid值)
与其他歌曲的这个链接对比一下就会发现只有songmid的值再改变
我们再去找songmid是什么,疯狂在文件中寻找,结果没有songmid字样,有也是在js中,songmid在js中还多以注释出现。。。
之后我在搜索歌曲之后,在歌曲信息的数据包里面发现了mid,然后我把url地址中编码过的mid解码后发现它们一样。。。(牛掰!!!)
下面给一个在多个文件中快速搜索关键子字的方法,如下图:
在线url解码:http://tool.chinaz.com/tools/urlencode.aspx
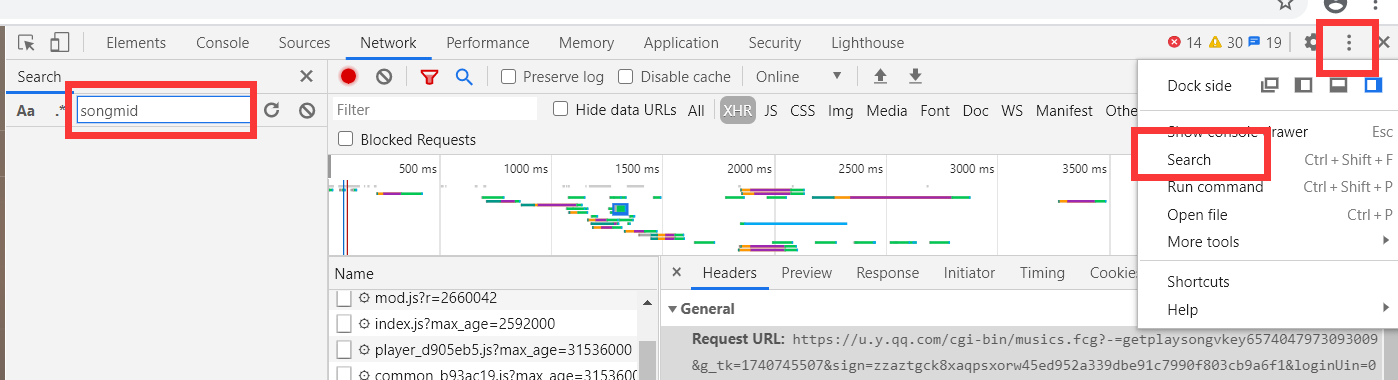
以搜索“夕阳红为例”
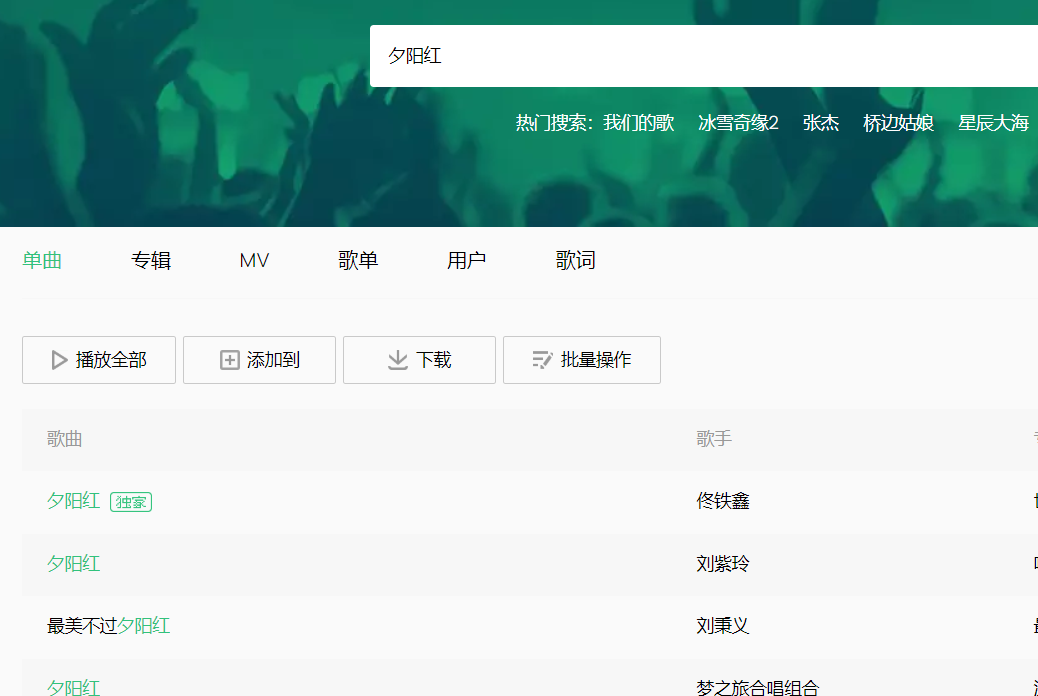
数据包list字段下面就是歌曲信息
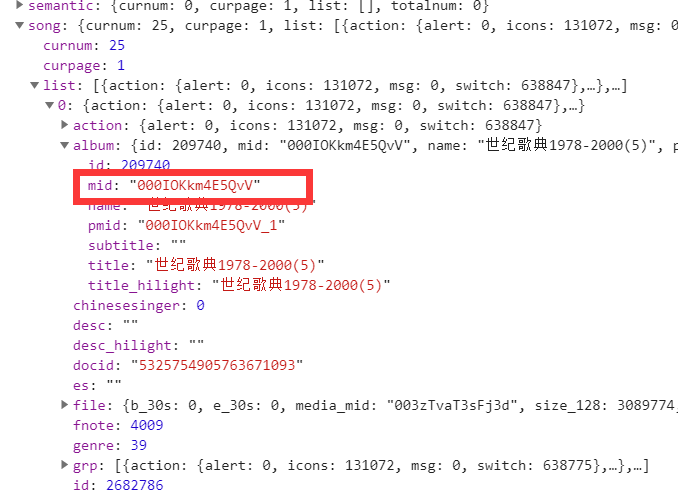
然后再看一下这个数据包的请求头(希望不要麻烦)
https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=70921863029222715&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%A4%95%E9%98%B3%E7%BA%A2&g_tk_new_20200303=1740745507&g_tk=1740745507&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0
删减之后
https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=70631360004412645&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E9%9D%9E%E9%B1%BC&g_tk_new_20200303=5381&g_tk=5381&loginUin=2272463882&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0
通过归纳可以知道n代表搜索到的歌曲显示数目,w是搜索的关键字
所以我们n设定一个值就行,w就运行程序是输入就行
所有问题都解决了(呼~~~~~~~)
import requests
import re
import os
import json
import time as t class QQmusic():
"""代码仅供学习""" def __init__(self):
"""初始化"""
self.headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'http://www.baidu.com/',
'Connection': 'keep-alive',
}
self.names = []
self.order = ' ' def search(self):
"""搜索"""
w = input("请输入歌曲名: ")
url_0 = "https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=61460539676714578&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w={0}&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0".format(
w)
res_0 = requests.get(url_0, headers=self.headers) # 第一层,搜索页
res_0.encoding = res_0.apparent_encoding
res_0 = res_0.json() # dict
music_list = res_0["data"]["song"]["list"]
print("共计" + str(len(music_list)) + "结果: ") all_singers = []
a = 0
for music in music_list:
singer = music["singer"][0]["title"] # 歌手名
name = str(a) + " " + music["title"] # 歌曲名
all_singers.append(singer)
self.names.append(name)
a = a + 1
infs = dict(zip(self.names, all_singers))
infs = json.dumps(infs, ensure_ascii=False, indent=4, separators=(',', ':'))
infs = infs.replace('"', ' ')
infs = infs.replace(':', '——————')
print(infs) self.order = input("请输入歌曲前的序号:")
songmid = res_0['data']['song']['list'][int(self.order)]['mid']
url_1 = "https://u.y.qq.com/cgi-bin/musicu.fcg?format=json&data=%7B%22req_0%22%3A%7B%22module%22%3A%22vkey.GetVkeyServer%22%2C%22method%22%3A%22CgiGetVkey%22%2C%22param%22%3A%7B%22guid%22%3A%22358840384%22%2C%22songmid%22%3A%5B%22{}%22%5D%2C%22songtype%22%3A%5B0%5D%2C%22uin%22%3A%221443481947%22%2C%22loginflag%22%3A1%2C%22platform%22%3A%2220%22%7D%7D%2C%22comm%22%3A%7B%22uin%22%3A%2218585073516%22%2C%22format%22%3A%22json%22%2C%22ct%22%3A24%2C%22cv%22%3A0%7D%7D".format(songmid) res_1 = requests.get(url_1, headers=self.headers)
res_1.encoding = res_1.apparent_encoding
res_1 = res_1.json() # dict
purl = res_1['req_0']['data']['midurlinfo'][0]['purl']
url_2 = "https://isure.stream.qqmusic.qq.com/" + purl
return url_2 def download(self):
"""下载"""
res_2 = requests.get(self.search(), headers=self.headers).content
fir = self.names[int(self.order)]
tit = re.sub(r'\d+', '', fir)
now = os.getcwd()
now = os.path.join(now, "qq音乐 ")
if not os.path.exists(now):
os.mkdir(now)
os.chdir(now)
file_name = tit + '.m4a'
with open(file_name, 'wb') as f:
f.write(res_2) one_file = QQmusic()
one_file.download()
python爬取QQVIP音乐的更多相关文章
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- python爬取酷我音乐
我去!!!我之后一定按照搜索方式下载歌曲~~~~~~~~~ 1.首先打开我们本次主讲链接:http://www.kuwo.cn/ 2.刚开始我就随便点了一个地方,然后开始在后台找歌曲的链接地址.但是 ...
- Python 爬取qqmusic音乐url并批量下载
qqmusic上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的.于是,来了个qqmusic的爬虫. 至少我觉得for循环爬虫,最核心的应该就是找到待爬元素所在ur ...
- python爬取酷我音乐(收费也可)
第一次创作,请多指教 环境:Python3.8,开发工具:Pycharm 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的 ...
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- 手把手教你使用Python抓取QQ音乐数据(第一弹)
[一.项目目标] 获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 由浅入深,层层递进,非常适合刚入门的同学练手. [二.需要的库] 主要涉及的库有:requests.json ...
- 手把手教你使用Python抓取QQ音乐数据(第二弹)
[一.项目目标] 通过Python爬取QQ音乐数据(一)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 此次我们在之前的基础上获取QQ音乐指定歌曲的歌词及前15个精 ...
- python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet mail:vpoet_sir@163.com 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 # ...
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
随机推荐
- LeetCode747 至少是其他数字两倍的最大数
在一个给定的数组nums中,总是存在一个最大元素 . 查找数组中的最大元素是否至少是数组中每个其他数字的两倍. 如果是,则返回最大元素的索引,否则返回-1. 示例 1: 输入: nums = [3, ...
- 【Spring】Spring中的Bean - 1、Baen配置
Bean配置 简单记录-Java EE企业级应用开发教程(Spring+Spring MVC+MyBatis)-Spring中的Bean 什么是Spring中的Bean? Spring可以被看作是一个 ...
- 【Linux】centos 7中,开机不执行rc.lcoal中的命令
最近将一些需要开机启动的命令添加到了rc.local中 本想着开机就启动了,很省事 但是一次意外的重启,发现rc.local中的全部命令都没有执行 发现问题后,及时查找 参考:https://blog ...
- YYDS: Webpack Plugin开发
目录 导读 一.cdn常规使用 二.开发一个webpack plugin 三.cdn优化插件实现 1.创建一个具名 JavaScript 函数(使用ES6的class实现) 2.在它的原型上定义 ap ...
- ctfhub技能树—web前置技能—http协议—302跳转
开启靶机 打开环境,查看显示 点击Give me Flag后发生跳转 根据题目提示为HTTP临时重定向 简单记录一下HTTP临时重定向是什么 HTTP重定向:服务器无法处理浏览器发送过来的请求(req ...
- Android 代码规范大全
前言 虽然我们项目的代码时间并不长,也没经过太多人手,但代码的规范性依然堪忧,目前存在较多的比较自由的「代码规范」,这非常不利于项目的维护,代码可读性也不够高, 此外,客户端和后端的研发模式也完全不同 ...
- 转 10 jmeter之动态关联
10 jmeter之动态关联 jmeter中关联是通过之前请求的后置处理器实现的,具体有两种方式:XPath Extractor(一般xml的时候用的多)和正则表达式提取器. 以webtours登 ...
- 离线安装docker-ce
1.用一台可以连外网的虚拟机把docker-ce安装包下载下来,vim /tmp/docker-download.sh #!/bin/bash set -e mkdir -p /apps/docker ...
- mysql的安装使用及其用户管理
mysql的安装使用及其用户管理 一.mariadb安装 搭建yum源 [mariadb] name = MariaDB baseurl = http://mirrors.ustc.edu.cn/ ...
- (06)-Python3之--判断、循环
1.判断(if) 语法: if 条件(True/False): 条件为真时,执行的代码(要干的事情)[elif 条件: 条件为真时,执行的代码(要干的事情)elif 条件: 条件为真时,执行的代码(要 ...