FlatBuffers使用小结
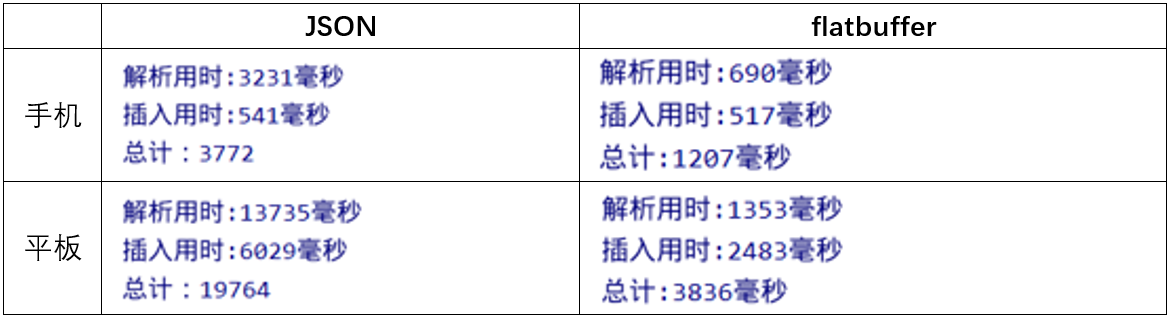
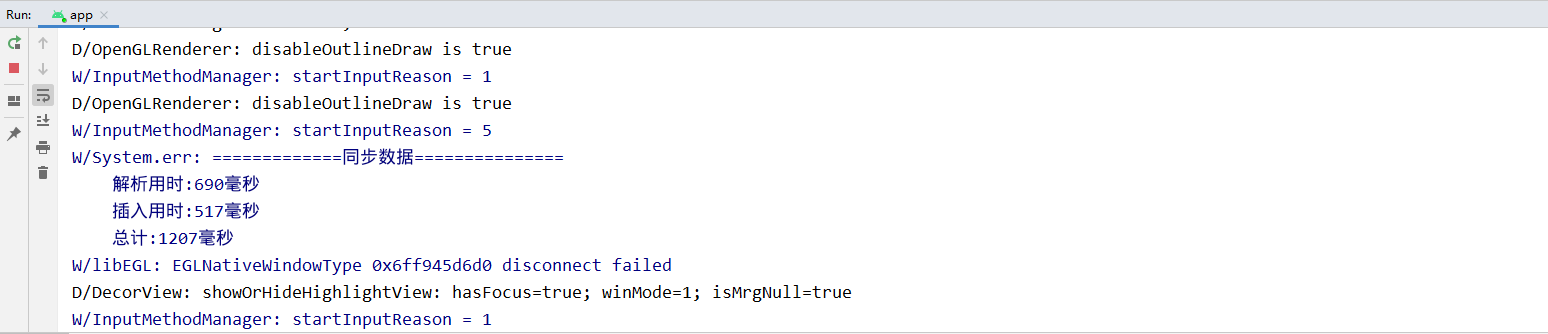
最近做一个Android APP,由于离线业务需求,需要在启动APP时候同步大量数据到APP上,遇到了JSON性能瓶颈。从下方的图片中可以看出,当使用 json 传输数据,在解析json的时候会产生大量的对象,使得内存疯狂飙升,不论是配置低端的平板还是配置比较高端的手机都会 GC 。而在使用 flatbuffers 的时候不论是平板还是手机,都没有 GC,并且在时间是数量级的差别。0.5s与0.05s的差距对你而言或许并不大,但是1s和10s的差距就很明显了噻,应该没人能忍受一个app的反应时间需要10s之久吧...
下面是我测试的参数与测试结果,对比提升可以说是相当的明显了。注(这里的解析时间是指:从发起请求到响应后把数据解析成对象的时间,也就是说除去相差不多的网络传输时间,单纯的对数据的解析时间 faltbuffers 提升会更加明显 )

什么是 FlatBuffers ?
FlatBuffers是一个高效的跨平台序列化库,适用于C++, C#, C, Go, Java, Kotlin, JavaScript, Lobster, Lua, TypeScript, PHP, Python, Rust 和Swift。它们最早由谷歌创立,用来开发游戏和其他一些需要高性能的程序。
为什么使用 FlatBuffers 会这么快?
无需解析/拆包即可访问序列化数据-FlatBuffers的与众不同之处在于,它在平坦的二进制缓冲区中表示层次结构数据,使得无需解析/拆包就可以直接访问它,同时还支持数据结构的演进(forward /向后兼容)
如何使用 FlatBuffers ?
1.编译器下载地址:https://github.com/google/flatbuffers/releases
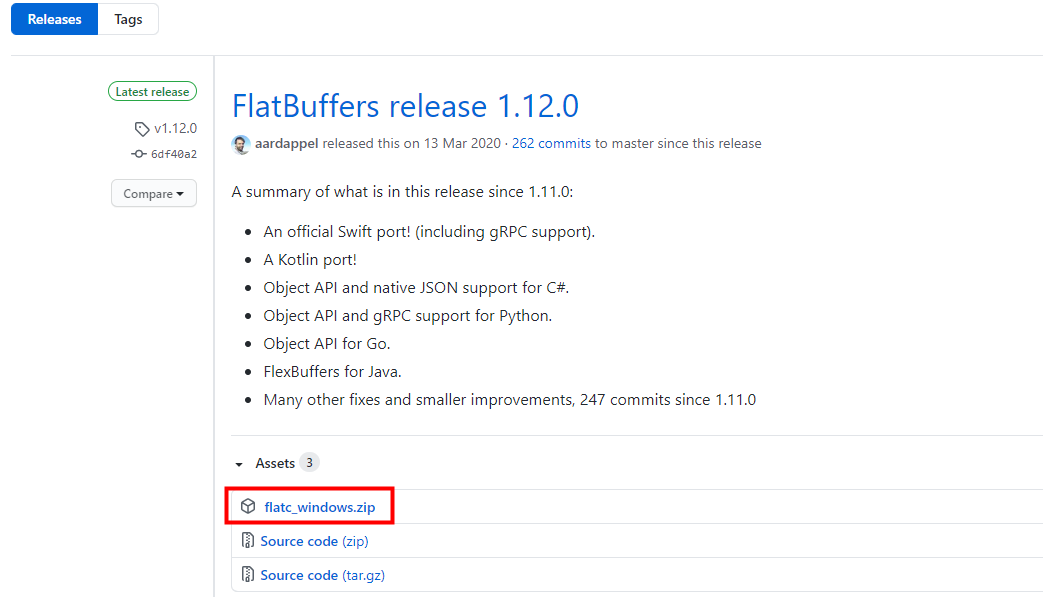
2.编写Schema文件 demo.fbs
namespace com.zxz.demo.flatbuffer;
table User {
id : long;
name : string;
gender : string;
departmentId : long;
createTime : string;
enabled : bool;
status : string;
}
table Account {
id : long;
userId : long;
login : string;
password : string;
loginCount : int;
}
table Data {
userList : [User];
accountList : [Account];
}
root_type Data;
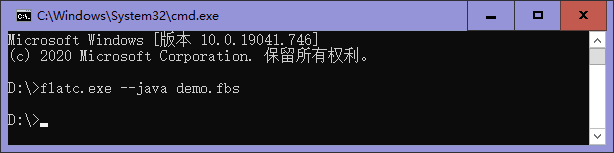
3.生成javaBean文件:flatc.exe --java demo.fbs
4.下载 FlatBuffers 源码: https://github.com/google/flatbuffers/tree/master/java,或者看看maven仓库有没有依赖包引入项目
5.服务端创建数据
public void service() throws Exception {
HttpServletResponse response = ActionContext.get().getResponse();
// 1.创建builder
FlatBufferBuilder builder = new FlatBufferBuilder(1024);
List<Integer> list1 = new ArrayList<Integer>();
for (int i = 0; i < 10; i++) {
long id = 0L;
int nameOffset = builder.createString("name");
int genderOffset = builder.createString("gender");
long departmentId = 0L;
int createTimeOffset = builder.createString("2021-01-10");
boolean enabled = true;
int statusOffset = builder.createString("status");
// 2.创建User对象返回 offset值
int createUser = User.createUser(builder, id, nameOffset, genderOffset, departmentId,
createTimeOffset, enabled, statusOffset);
list1.add(createUser);
}
// 3.把存储对象offset值的集合转成数组
int[] arr1 = list1.stream().mapToInt(Integer::valueOf).toArray();
// 4.构建User的数据
int createUsersVector = Data.createUsersVector(builder, arr1);
// 5.构建Data对象(Data中包含[User])
Data.startData(builder);
// 6.添加User的集合
Data.addUsers(builder, createUsersVector);
int offset = Data.endData(builder);
Data.finishDataBuffer(builder, offset);
// 7.把DataBuffer写入到IO中
ServletOutputStream os = response.getOutputStream();
os.write(builder.dataBuffer().array(), builder.dataBuffer().position(), builder.offset());
os.close();
}
6.客户端接收数据
public void onResponse(Call call, Response response) throws IOException {
byte[] bytes = response.body().bytes();
ByteBuffer bb = ByteBuffer.wrap(bytes);
Data data = Data.getRootAsData(bb);
}
==================================END==================================
==============================测试结果截图===============================
图一、平板上使用 json 传输数据
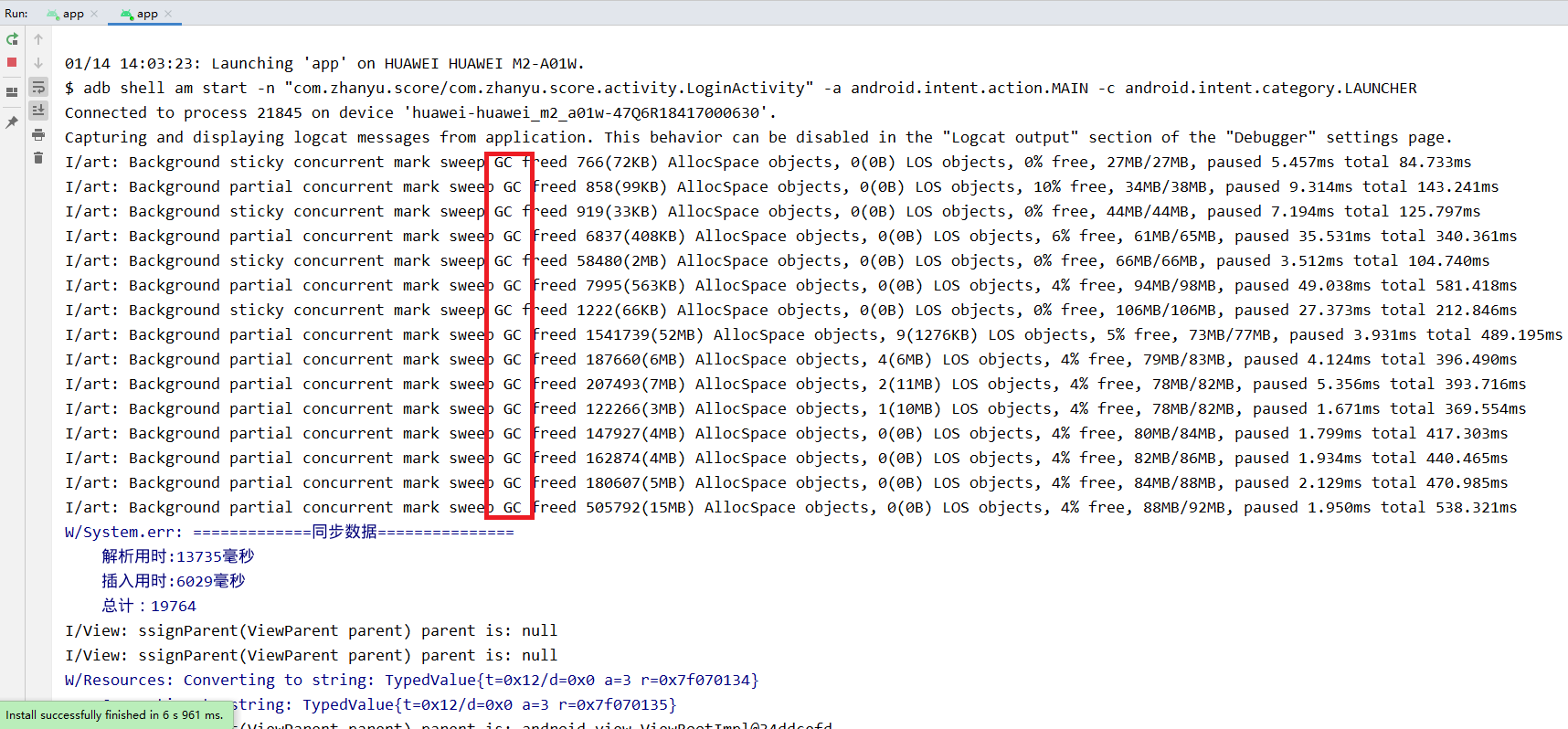
图二、手机上使用 json 传输数据

图三、平板上使用 flatbuffers 传输数据
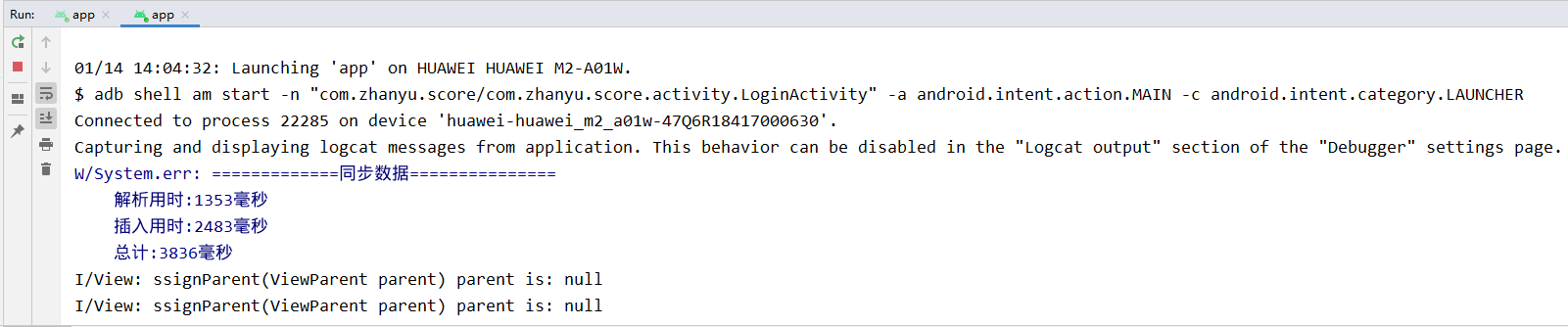
图四、手机上使用 flatbuffers 传输数据
FlatBuffers使用小结的更多相关文章
- 从零开始编写自己的C#框架(26)——小结
一直想写个总结,不过实在太忙了,所以一直拖啊拖啊,拖到现在,不过也好,有了这段时间的沉淀,发现自己又有了小小的进步.哈哈...... 原想框架开发的相关开发步骤.文档.代码.功能.部署等都简单的讲过了 ...
- Python自然语言处理工具小结
Python自然语言处理工具小结 作者:白宁超 2016年11月21日21:45:26 目录 [Python NLP]干货!详述Python NLTK下如何使用stanford NLP工具包(1) [ ...
- java单向加密算法小结(2)--MD5哈希算法
上一篇文章整理了Base64算法的相关知识,严格来说,Base64只能算是一种编码方式而非加密算法,这一篇要说的MD5,其实也不算是加密算法,而是一种哈希算法,即将目标文本转化为固定长度,不可逆的字符 ...
- iOS--->微信支付小结
iOS--->微信支付小结 说起支付,除了支付宝支付之外,微信支付也是我们三方支付中最重要的方式之一,承接上面总结的支付宝,接下来把微信支付也总结了一下 ***那么首先还是由公司去创建并申请使用 ...
- iOS 之UITextFiled/UITextView小结
一:编辑被键盘遮挡的问题 参考自:http://blog.csdn.net/windkisshao/article/details/21398521 1.自定方法 ,用于移动视图 -(void)mov ...
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- scikit-learn随机森林调参小结
在Bagging与随机森林算法原理小结中,我们对随机森林(Random Forest, 以下简称RF)的原理做了总结.本文就从实践的角度对RF做一个总结.重点讲述scikit-learn中RF的调参注 ...
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- scikit-learn 梯度提升树(GBDT)调参小结
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
随机推荐
- VMware 虚拟机网卡设置与外网访问
1 查看虚拟机网卡设置,查看虚拟机网关. 2 然后,设置本地机器VMnet8网卡的IP地址和子网掩码.切记,IP地址不能与虚拟机网卡IP地址相同. 3 配置虚拟机Centos的ens33网卡 TYPE ...
- 06 python开发之函数
06 python开发之函数 目录 06 python开发之函数 6 函数 6.1 基本使用 6.1.1 基本概念 6.1.2 定义函数 6.2 调用函数与函数返回值 6.2.1 调用函数三种形式 6 ...
- Springboot mini - Solon详解(七)- Solon Ioc 的注解对比Spring及JSR330
Springboot min -Solon 详解系列文章: Springboot mini - Solon详解(一)- 快速入门 Springboot mini - Solon详解(二)- Solon ...
- Collections.synchronizedList 并发
1.背景 集合类中的map,大家一定熟悉,知道它非线程安全.使用的方法有两种,一种是在map上加同步器(锁),另一种是创建容器时使用Collections中的静态方法对map进行包装. java ap ...
- 记一次 HBase Master is initializing 问题处理
问题 hbase shell中建立建表出错 分析 org.apache.hadoop.hbase.PleaseHoldException: Master is initializing代表Master ...
- Spark性能优化指南
1 Spark开发调优篇 原则一:避免创建重复的RDD 原则二:尽可能复用同一个RDD 原则三:对多次使用的RDD进行持久化 原则四:尽量避免使用shuffle类算子 因此在我们的开发过程中,能避免则 ...
- MySQL高级部分理论知识细讲
文章目录 一.数据库分区.分表.分库.分片 YesOk ,大家好 ,我是小刘,许久不见,甚是想念 ,小刘今天来带大家学习 分库分表的基础知识 1.1 单机数据库的瓶颈 单个表数据量越大,读写锁,插入操 ...
- 一个shell程序
使用vi写一个shell程序 touch cdlog echo "cd /app/mycrm/log" >> cdlog chmod +x cdlog 执行: ...
- Python实现全自动购买火车票!抢票回家过年咯
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理这个是实现结果,因为一天只能取消三次,所以最后一步点击确认被我注释了1.首先实现使用selenium登 ...
- ConcurrentHashMap线程安全吗?
前言 没啥深入实践的理论系同学,在使用并发工具时,总是认为把HashMap改为ConcurrentHashMap,就完美解决并发了呀.或者使用写时复制的CopyOnWriteArrayList,性能更 ...