新手用Python运行selenium的常见问题
1.更换Python版本
打开pycharm,点击 file——setting——project项目名——project Interpreter,点击右侧的设置,如下图
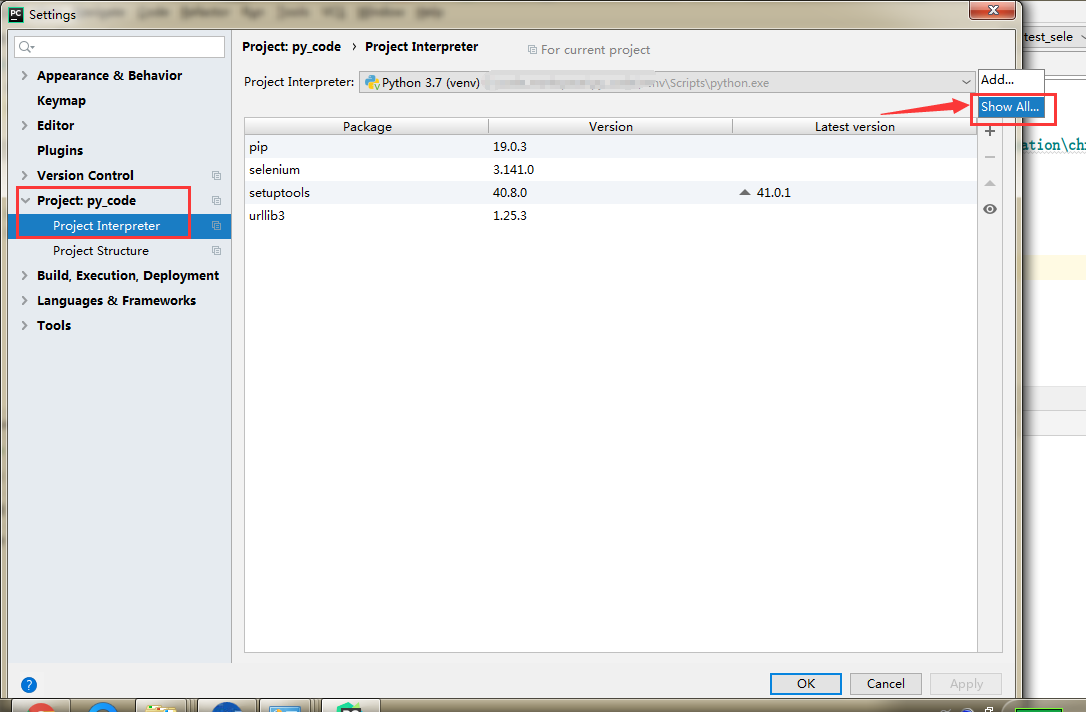
选择新Python版本的安装路径。
如果location提示“environment location directory is not empty”,导致无法保存。则将location路径的文件夹删掉,然后再重新设置就可以保存了。
2.添加selenium包
没有安装selenium包时,程序中importselenium包报错:
no module named 'selenium'
查看Python3安装目录 ..\python37\Script\目录下是否存在pip.exe,并确保该目录已添加到“环境变量”的“path”下面。
打开windows命令提示符,输入“pip”命令,确保该命令可以执行成功。
然后按照安装selenium包。
输入命令:pip install selenium
安装成功后,输入:from selenium import selenium
不报错,表示selenium包安装成功
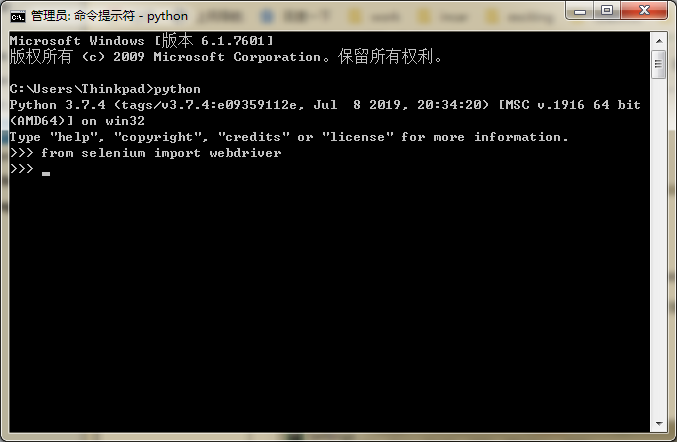
然后在重新配置project interpret,步骤与1相同。
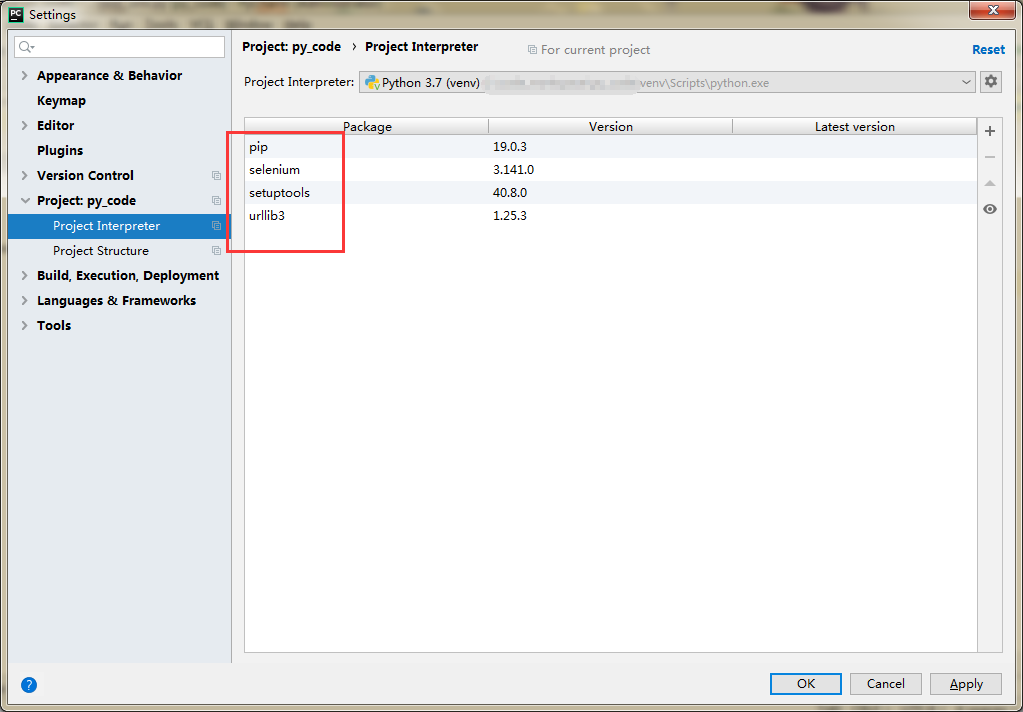
3.添加Chromedriver包
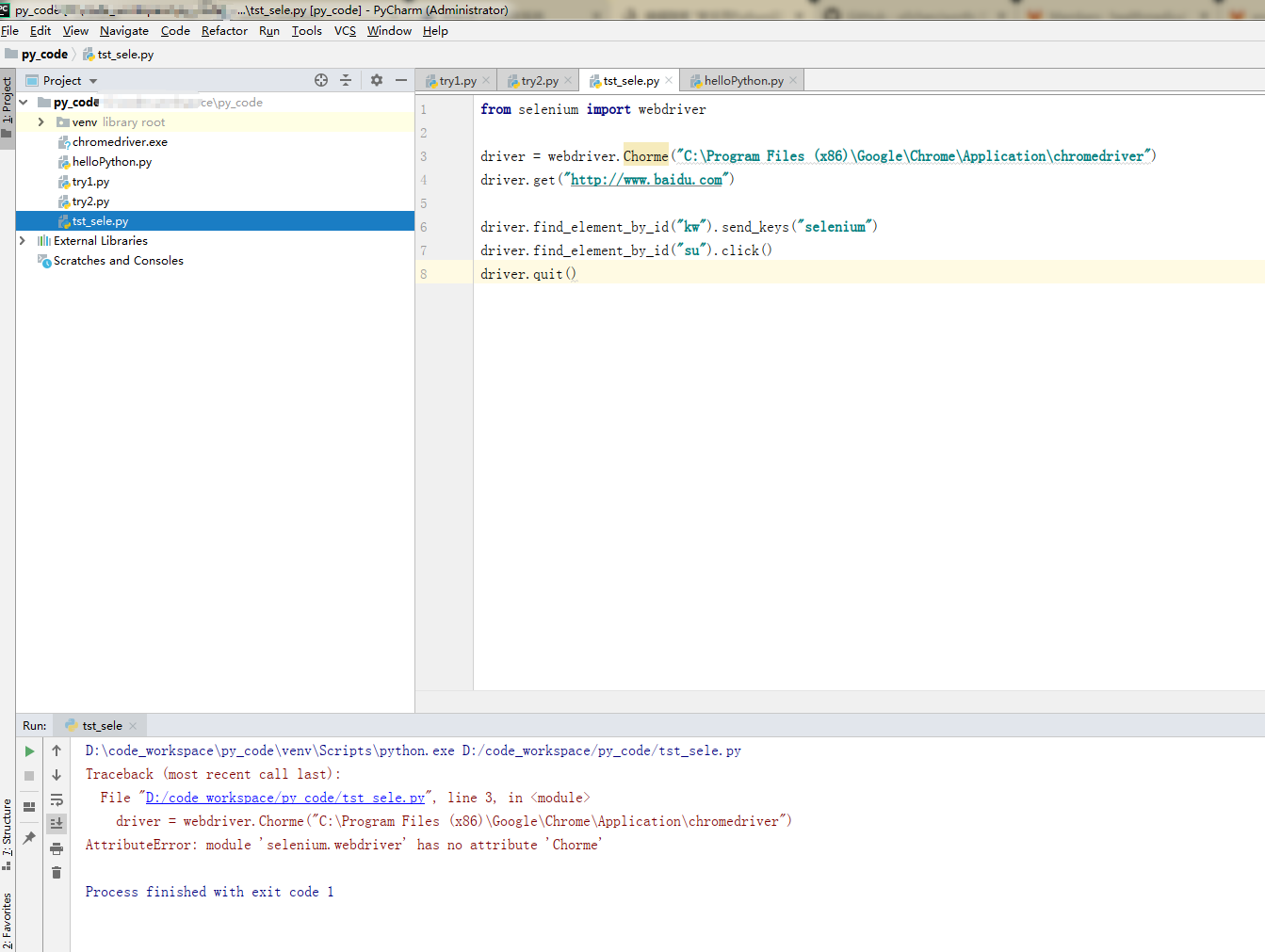
常见报错:
driver = webdriver.Chorme()
AttributeError: module 'selenium.webdriver' has no attribute 'Chorme'
查找Chrome版本对应的Chromedriver版本:https://chromedriver.storage.googleapis.com/index.html
下载相应的版本后,将 Chromedriver.exe 放到Chrome安装目录下
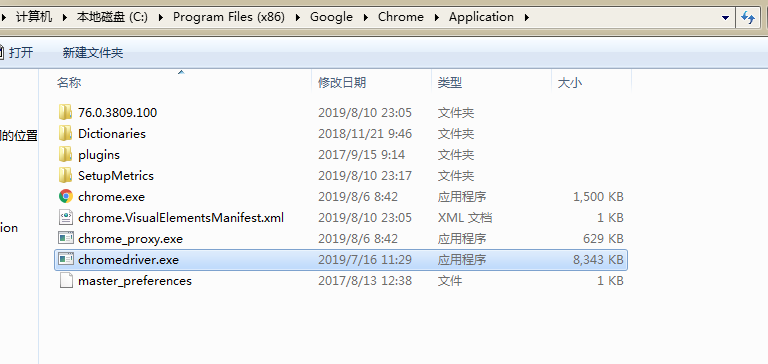
配置环境变量:将Chromedriver.exe的路径加到环境变量path中
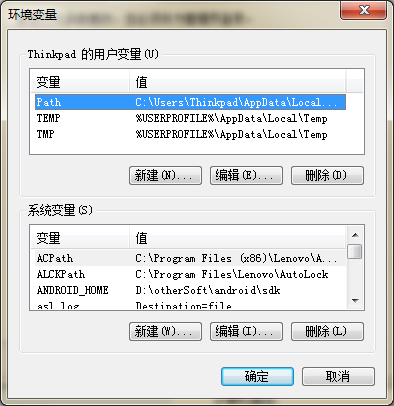
检验是否添加成功:
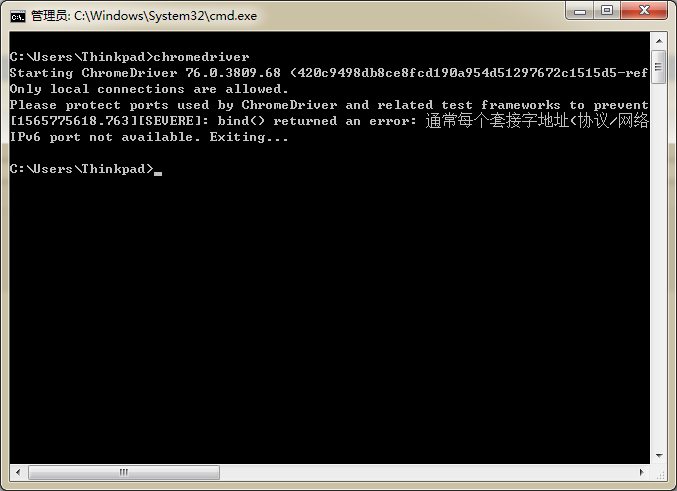
打开cmd,输入 Chromedriver。如下图,安装成功。
思考:
上面都操作成功了,运行下面程序报错
新手用Python运行selenium的常见问题的更多相关文章
- python运行selenium时出现的一个错误总结
1.SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame 场景:运用pan ...
- 使用Python的selenium库制作脚本,支持后台运行
本文介绍如何使用Python的selenium库制作脚本.概念: Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome.Firefox.Safari等主流界面 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- [Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
前三篇文章介绍了安装过程和通过Selenium实现访问Firefox浏览器并自动搜索"Eastmount"关键字及截图的功能.而这篇文章主要简单介绍如何实现自动登录163邮箱,同时 ...
- [Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
前面几篇文章介绍了Selenium.PhantomJS的基础知识及安装过程,这篇文章是一篇应用.通过Selenium调用Phantomjs获取CSDN下载资源的信息,最重要的是动态获取资源的评论,它是 ...
- [Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
前面我讲述过如何通过BeautifulSoup获取维基百科的消息盒,同样可以通过Spider获取网站内容,最近学习了Selenium+Phantomjs后,准备利用它们获取百度百科的旅游景点消息盒(I ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- 【Python】 Selenium 模拟浏览器 寻路
selenium 最开始我碰到SE,是上学期期末,我们那个商务小组做田野调查时发的问卷的事情.当时在问卷星上发了个问卷,但是当时我对另外几个组员的做法颇有微词,又恰好开始学一些软件知识了,就想恶作剧( ...
- Python 配置 selenium 模拟浏览器环境,带下载链接
使用浏览器渲染引擎.直接用浏览器在显示网页时解析HTML,应用CSS样式并执行JavaScript的语句. 这方法在爬虫过程中会打开一个浏览器,加载该网页,自动操作浏览器浏览各个网页,顺便把数据抓下来 ...
随机推荐
- 本地配置gitee
一 下载工具 Git-2.62.0-64-bit.exe 以上工具版本号不需要一样,安装完前两个后重新启动系统,再安装第3个. 二 码云网站注册 https://gitee.com/ 使用邮箱注册 注 ...
- boost常用库(一):boost数值转换
在STL中有一些字符转换函数,例如atoi,itoa等,在boost里面只需用一个函数lexical_cast进行转换,lexical_cast是模板方法,使用时需要传入类型.只能是数值类型转字符串. ...
- Jupyter的搭建
在家实在无聊,伏案沉思良久,忽然灵机一动,何不写写Python?然而电脑上的软件早已人是物非,Pycharm已然不复存在.但是又不想装软件找激活码,于是,只好建个Jupyter先凑合一下. 1. 安装 ...
- python常见数据类型及操作方法
title: "python数据类型及其常用方法" date: 2020-04-21T10:15:44+08:00 可变数据类型:允许变量的值发生变化,即如果对变量进行append ...
- 腾讯云Redis混合存储版重磅推出,万字长文助你破解缓存难题!
导语 | 缓存+存储的系统架构是目前常见的系统架构,缓存层负责加速访问,存储层负责存储数据.这样的架构需要业务层或者是中间件去实现缓存和存储的双写.冷热数据的交换,同时还面临着缓存失效.缓存刷脏.数据 ...
- Linux MySQL分库分表之Mycat
介绍 背景 当表的个数达到了几百千万张表时,众多的业务模块都访问这个数据库,压力会比较大,考虑对其进行分库 当表的数据达到几千万级别,在做很多操作都比较吃力,考虑对其进行分库或分表 数据切分(shar ...
- Beta冲刺<1/10>
这个作业属于哪个课程 软件工程 (福州大学至诚学院 - 计算机工程系) 这个作业要求在哪里 Beta冲刺 这个作业的目标 Beta冲刺--第一天(05.19) 作业正文 如下 其他参考文献 ... B ...
- 键盘侠Linux干货| ELK(Elasticsearch + Logstash + Kibana) 搭建教程
前言 Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案,分析网站的访问情况时我们一般会借助 Google / 百度 / CNZZ 等方式嵌入 JS ...
- SpringCloud教程第1篇:Eureka(F版本)
一.创建服务注册中心(Eureka组件) 1.1 首先创建一个maven主工程. 1.创建maven项目 是一个主Maven工程,spring Boot版本为2.0.3.RELEASE,Spring ...
- java基础 内部类详解
什么是内部类? 1.内部类也是一个类: 2.内部类位于其他类声明内部. 内部类的常见类型 1.成员内部类 2.局部内部类 3.匿名内部类 4.静态内部类 简单示例 /** * 外部类 * */ pub ...