Spark Streaming架构设计和运行机制总结
本期内容 :
- Spark Streaming中的架构设计和运行机制
- Spark Streaming深度思考
Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行触发周而复始的接收数据及产生Job处理数据。
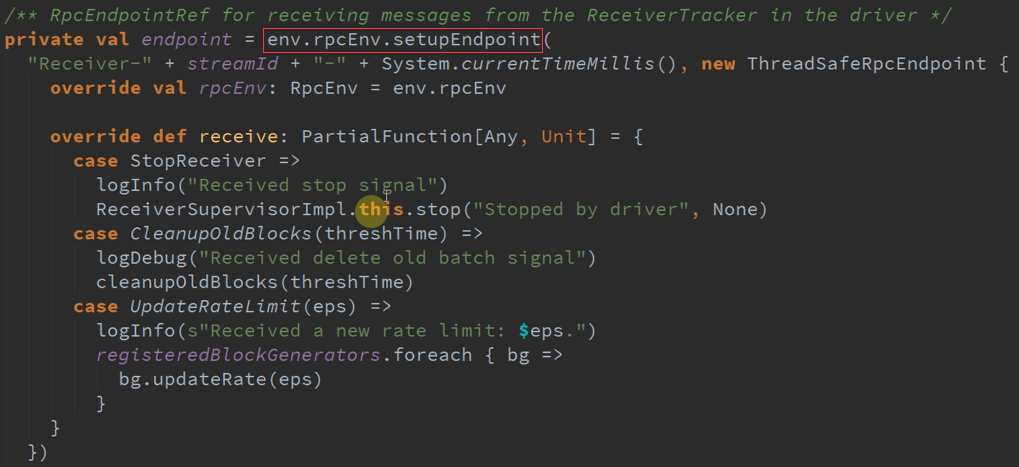
一、 ReceiverTracker :
Receiver数据接收器的启动、接收数据过程中元数据管理,元数据管理是使用内部的RPC。
根据时间的间隔把数据分配给当前的BatchDuration :
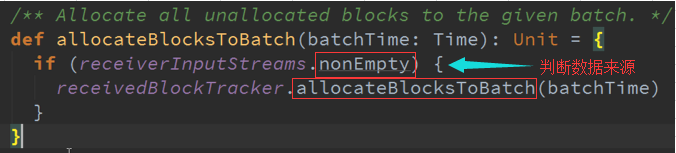
通过Dstreams中的StreamID以及这个DStreamID给这个时间段(getReceivedQueue(SteamID))的Block为例 :
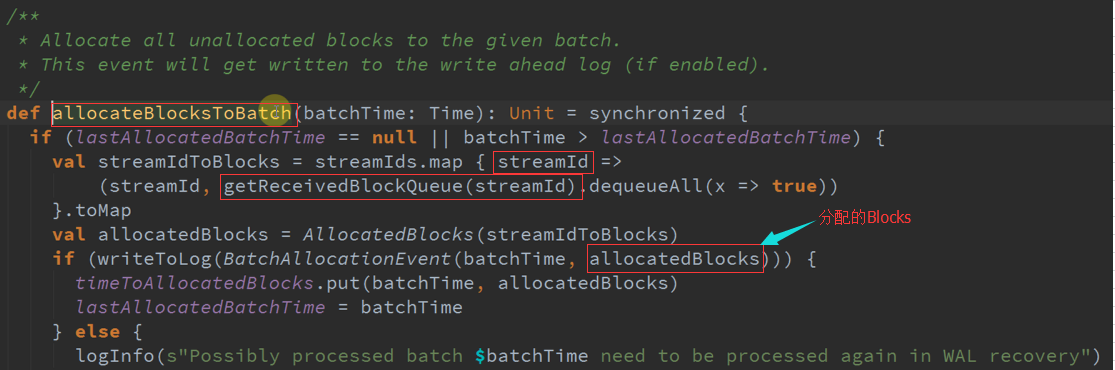
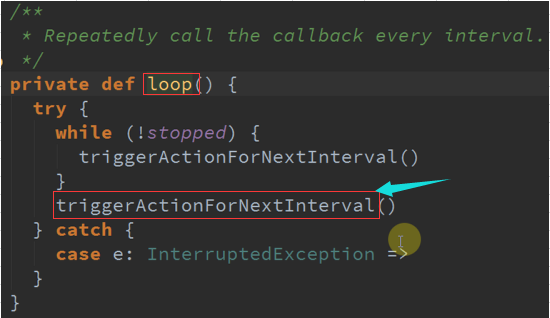
不断的分配是依赖定时器,看数据生成的时候怎么产生数据及通过他的方式管理数据的 。

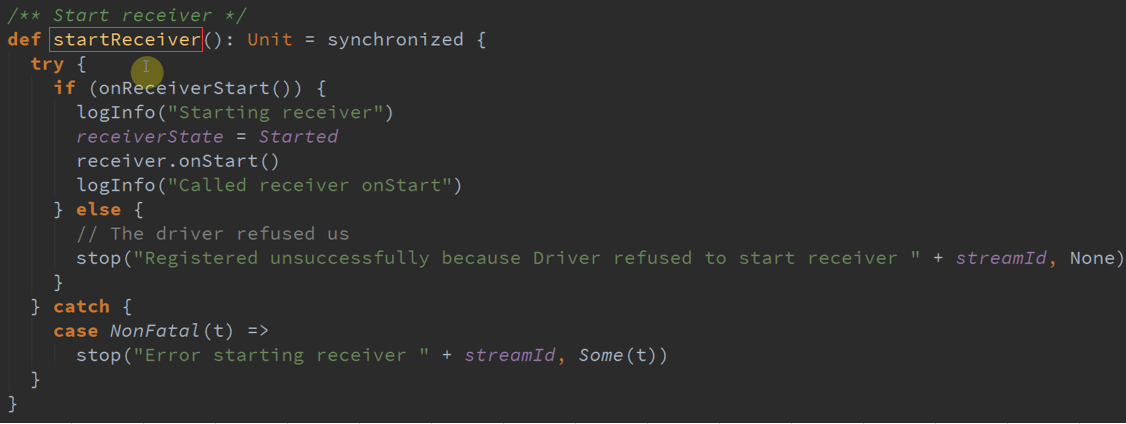
不断接收数据并保存起来,在BlockTracker启动Receiver时首先会启动StartReceiver 。
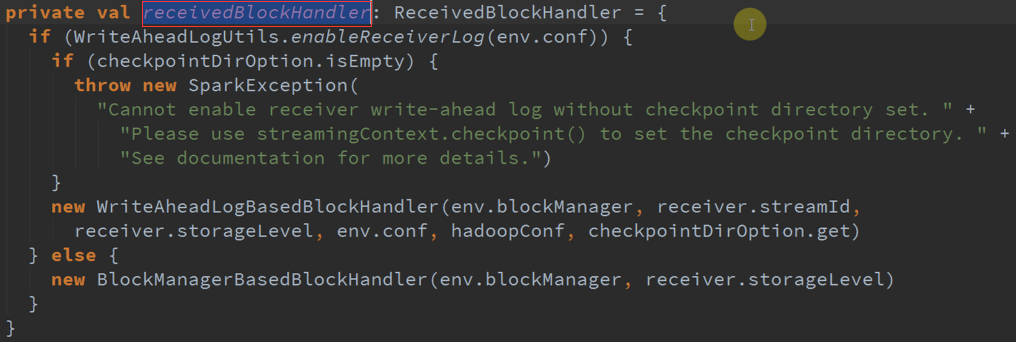
写数据时有不同的BlockHandler 。
Receiver自己的RPC ,响应不同的消息。
定时器按照具体的时间间隔 :


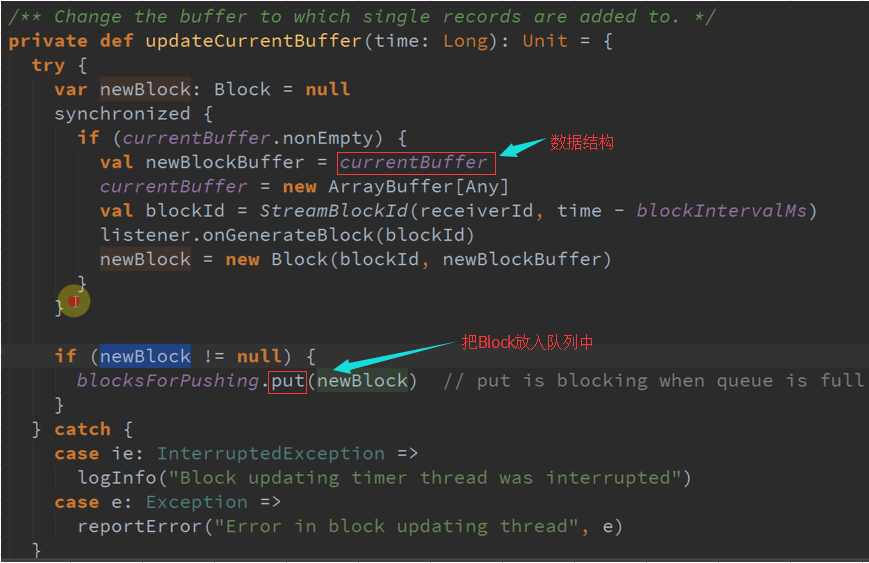
二、 currentBuffer :
把接收的数据保存在一个currentBuffer数据结构(属于临时数据结构)中,每次根据其时间间隔进行,每次都会New一下currentBuffer,默认是200MS。

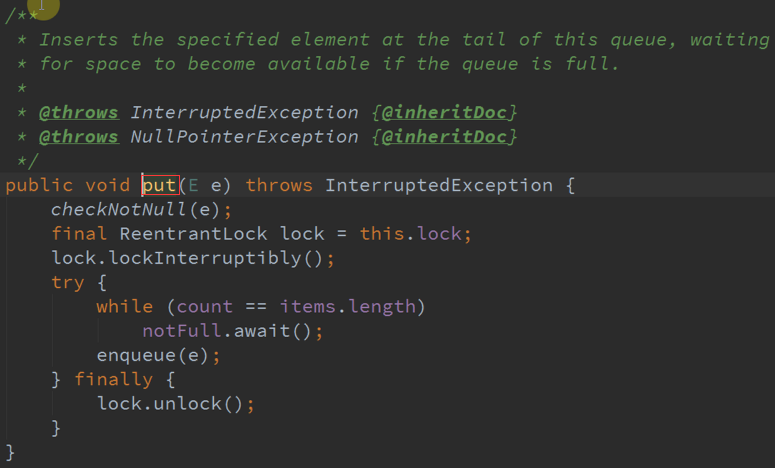
三、 架构思考 :
从Spark Streaming的角度讲静态生成Dstreams,Dstreams当遇到时间的时候才会生成RDD和DStreamGenerator。
基于DStreamGenerator就构成了这个依赖关系。调度层面讲JobScheduler,是基于时间的流处理框架。

根据BatchDuration的时钟不断循环,不断的发送消息 。


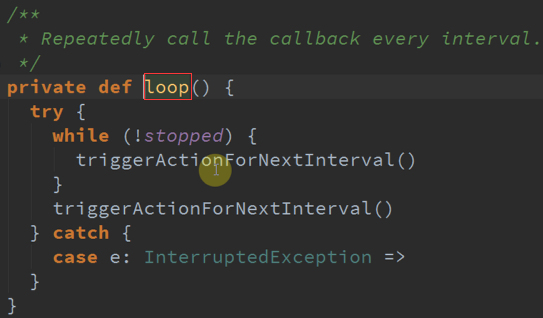
以时间为基准 不断的发送消息给event 。


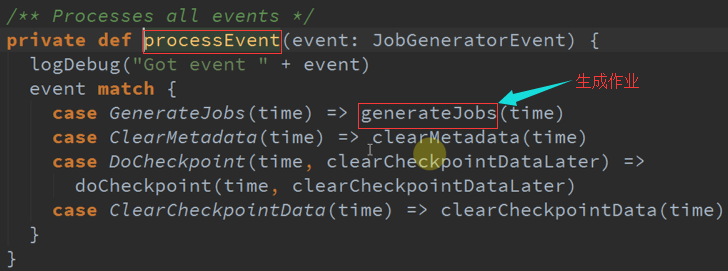
生成作业 :
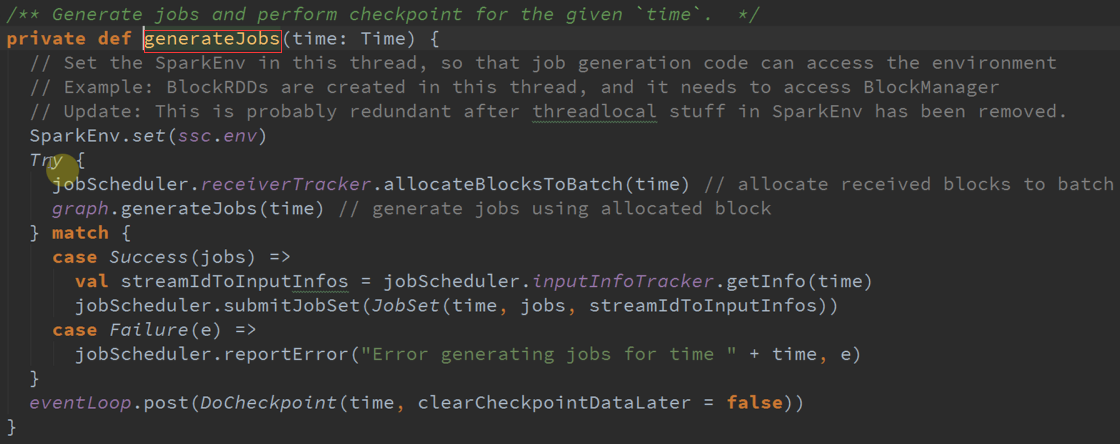
Spark Streaming运行核心:
Spark RDD加上Time,无论是从概念还是数据接收、数据处理,Time是驱动力,不断的循环事件、消息,时间的确定、数据、RDD接着就转到Spark Core。
Spark Streaming架构设计和运行机制总结的更多相关文章
- Spark Streaming揭秘 Day19 架构设计和运行机制
Spark Streaming揭秘 Day19 架构设计和运行机制 今天主要讨论一些SparkStreaming设计的关键点,也算做个小结. DStream设计 首先我们可以进行一个简单的理解:DSt ...
- Spark Streaming揭秘 Day27 Job产生机制
Spark Streaming揭秘 Day27 Job产生机制 今天主要讨论一个问题,就是除了DStream action以外,还有什么地方可以产生Job,这会有助于了解Spark Streaming ...
- Spark Streaming揭秘 Day16 数据清理机制
Spark Streaming揭秘 Day16 数据清理机制 今天主要来讲下Spark的数据清理机制,我们都知道,Spark是运行在jvm上的,虽然jvm本身就有对象的自动回收工作,但是,如果自己不进 ...
- Spark Streaming 架构
图 1 Spark Streaming 架构图 组件介绍: Network Input Tracker : 通 过 接 收 器 接 收 流 数 据, 并 将 流 数 据 映 射 为 输 入DSt ...
- Qt之UI文件设计和运行机制
1.项目文件组成在QtCreator中新建一个WidgetApplocation项目,选中窗口基类中选中QWidget作为窗口基类,并选中"GnerateForm"复选框.创建后项 ...
- 宜信开源|分布式任务调度平台SIA-TASK的架构设计与运行流程
一.分布式任务调度的背景 无论是互联网应用或者企业级应用,都充斥着大量的批处理任务.我们常常需要一些任务调度系统来帮助解决问题.随着微服务化架构的逐步演进,单体架构逐渐演变为分布式.微服务架构.在此背 ...
- 60、Spark Streaming:缓存与持久化机制、Checkpoint机制
一.缓存与持久化机制 与RDD类似,Spark Streaming也可以让开发人员手动控制,将数据流中的数据持久化到内存中.对DStream调用persist()方法,就可以让Spark Stream ...
- MySQL架构原理之运行机制
所谓运行机制即MySQL内部就如生产车间如何进行生产的.如下图: 1.建立连接,通过客户端/服务器通信协议与MySQL建立连接.MySQL客户端与服务端的通信方式是"半双工".对于 ...
- 2.Spark Streaming运行机制和架构
1 解密Spark Streaming运行机制 上节课我们谈到了技术界的寻龙点穴.这就像过去的风水一样,每个领域都有自己的龙脉,Spark就是龙脉之所在,它的龙穴或者关键点就是SparkStreami ...
随机推荐
- PetaPoco 批量插入数据
网上找的代码,还没经过验证 /// <summary> /// Bulk inserts multiple rows to SQL /// </summary> /// < ...
- OpenGL观察轴
旋转矩阵可以通过观察向量构造,观察向量可以是3D空间的两个或三个点.如果一个处于P1点的对象面向P2点,则观察向量就是P2-P1,如下图: 首先,前轴向量通过归一化的观察向量简单计算而来. 其次,左轴 ...
- MATLAB 绘图时的相关心得
matlab中如何调整legend的位置? legend('sinx',-1); %----位于图形框外面-----------------------legend('sinx',0);------- ...
- 强大的矩阵奇异值分解(SVD)及其应用
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- python使用xlrd模块读写excel
1.行列索引均从0开始2.int数据被读成float数据,解决办法,if type(value) == float and value%1 == 0,value= int(value)模块读 #!/u ...
- Fatal error 829---数据库 ID 8,页 (1:80740) 已标记为 RestorePending,可能表明磁盘已损坏(日志备份和热备、双机的重要性)
问题现象: 在业务数据库中查询:SELECT a.NAME FROM SYSOBJECTS a WHERE a.NAME LIKE '%2015' AND a.XTYPE='u' 提示:消息 21,级 ...
- Oracle基本教程
Oracle基本教程 1.Oracle介绍 2.SqlPlus使用 3.用户管理与权限控制 4.数据库备份与还原 5.物理备份--Rman 6.常用查询 7.Oracle用法集锦 8.oracle修改 ...
- [PHP] - PDO事务操作
PHP使用PDO事务操作数据库. 参考文章: http://php.ncong.com/mysql/pdo/pdo_shiwu.html 上代码: <!doctype html> < ...
- C 最熟悉的陌生人 (纪念当年就读的梅州市江南高级中学)
最熟悉的陌生人 作者:张慧桥 “枪与玫瑰” 我送走了“蝶恋花”,犹有一种身在梦中的感觉,昨晚的宿醉让我只觉得头晕乎乎的很不舒服,想想自己连澡都还没洗呢,便去洗了个冷水澡. 煮了杯浓浓的咖啡喝了下去,我 ...
- chart.js插件生成折线图时数据普遍较大时Y轴数据不从0开始的解决办法[bubuko.com]
chart.js插件生成折线图时数据普遍较大时Y轴数据不从0开始的解决办法,原文:http://bubuko.com/infodetail-328671.html 默认情况下如下图 Y轴并不是从0开始 ...