Hadoop学习之旅二:HDFS
本文基于Hadoop1.X
概述
分布式文件系统主要用来解决如下几个问题:
- 读写大文件
- 加速运算
对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整个硬盘的容量的文件,这时需要将文件分割为若干较小的块,然后将这些块按照一定的规则分放在集群中若干台节点计算机里。
分布式文件系统的另一个作用是加速运算,在多台计算机上对每个子文件进行计算最后再汇总结果通常比在一台计算机上处理大量文件的运算要块。这种分而治之的思想倡导:与其追求造价昂贵的高性能计算机,不如多找几个性能普通的廉价机器来搞。
廉价的机器集群还有一个比单个高性能计算机更有优势的地方是灵活性,可以非常方便的增加或减少集群中节点的数量,比起单个高性能机器,这种设计在计规模小时也不会造成资源(CPU,内存)的浪费,在规模膨胀时又能通过简单的增加节点的动作轻松应对。
然而,任何事情都有两面性,集群的弱点在于出现故障的几率变大了,假设单台机器故障率是p,那么具有n台机器节点的集群故障率就是pn,为了能够在某些节点出现故障的情况下不影响整个集群的健康,集群中不得不将每个节点中的数据备份多份放在别的节点,这样当某个节点的数据不可用时还可以读取备份节点的数据。集群以冗余为代价换取高可用性。
HDFS(Hadoop Distrbuted File System)是当今世界上最流行的分布式大数据处理系统Hadoop所依赖的文件系统,它的思想源头是伟大的Google公司发表的论文:The Google File System,受此启发,雅虎的若干大神包括Doug Cutting等把它搞出来的。
HDFS的特点
- 适合处理超大文件:超大文件是指大小超过几百M,几百G甚至几百T的文件。HDFS不适合处理小文件,首先,HDFS的文件块(block)默认为64M,太小的文件会造成磁盘的浪费;其次,HDFS的元数据信息(记录文件、路径和分块情况等信息)保存在某个节点(NameNode)的内存中,大量的小文件需要大量的元素据来记录,大量的元素据需要大量的内存;
- 流式数据访问:一次写入数据,然后多次读取数据的大部分甚至全部进行分析,不支持随机读取操作
- 对节点计算机的要求较低:无需昂贵的高性能机器,集群可由廉价机器组成
- 不适合对数据读写延时有严格要求的场景:HDFS重在高吞吐量,付出的代价之一就是提高了延迟时间
- 不支持多用户写入,不支持随机写操作:只能顺序将数据添加到文件结尾
想要实现随机读写以及延时较低的数据读写,请考虑使用基于HDFS的HBase数据库。
HDFS的结构
HDFS是一个基于操作系统本身的文件系统之上的虚拟文件系统,和常见的文件系统一样,HDFS文件存储的最小单元是块(block),默认的块的大小是64M,一个文件的若干块可分布在不同的机器上(DataNode),所以才“分布式”了。
集群节点由三部分组成,分别是
- NameNode (只有一个)
- DataNode
- Secondary NameNode(只有一个)
NameNode节点负责保存和维护整个集群的元数据(Hadoop2并不是这样,希望后续文章会涉及),包括文件名、文件分块(block)、文件的块分布在哪些节点、整个文件系统的运行状态等信息,一个集群中只有一个节点是NameNode节点。
DataNode节点负责实际存放数据。
由于整个集群只有一个NameNode节点,该节点如果挂了整个集群也就完蛋了,所有又搞了一个Secondary NameNode出来,它会定时获取NameNode的快照,当NameNode挂掉后可以通过Secondary NameNode快速恢复(Hadoop2并不是这样,希望后续文章会涉及)。
下图来自《Hadoop 实战》:
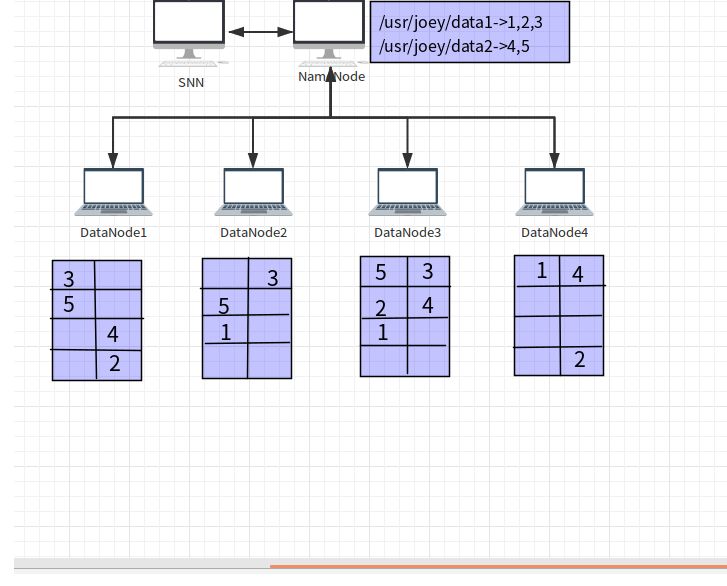
文件data1和data2的元数据信息保存在NameNode节点中,元数据中记录了data1文件由3个文件块1,2和3组成,文件data2由2个文件块4和5组成,并且记录了每个块所在的DataNode节点。文件块分布在4个DataNode节点上,每个文件块有都保存3份(3份是默认的设置)。DataNode还定时给NameNode发送心跳数据,如果NameNode长时间没有收到心跳数据,则认为DataNode挂掉了。
HDFS的命令行接口
下载并安装Hadoop后,即可使用HDFS了,Hadoop的安装和配置请参考Hadoop学习之旅一:Hello Hadoop。HDFS类似于Unix的文件系统,权限的设定也是分w、r和x(可执行ls命令查看,该命令类似Unix的ls -l 命令),常用命令和Unix的文件操作命令相同或类似,下面介绍几个常用的命令:
- ls:
bin/hadoop fs -ls /user#列出路径/user下的所有文件和路径 - lsr: `bin/hadoop fs -lsr /user #列出路径/user下的所有文件并递归列出子路径及子路经下的文件
- mkdir: bin/hadoop fs -mkdir /user/hdfs_test #创建路径 /user/hdfs_test
- rmr: bin/hadoop fs -rmr /user/hdfs_test #删除路径 /user/hdfs_test
- put: bin/hadoop fs -put hello.txt /user/hdfs_test #拷贝本地文件到HDFS路径/user/hdfs_test
- get: bin/hadoop fs -get /user/hdfs_test/hello.txt /home/joey #将hello.txt文件从HDFS拷贝到本地文件系统
- cat: bin/hadoop fs -cat /user/hdfs_test/hello.txt #查看文件内容
更多命令请查看官方文档。
HDFS的Java编程接口
实际上,上面的命令行接口就是一个Java应用,下面利用编程接口写一个示例程序,该程序使用FileSysgem类读取本地参数指定的路径下以“hadoop”开头的文件并将其复制到参数指定的HDFS路径:
package test.joye.com;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Copy {
public static void main(String[] args) {
Path localPath = new Path(args[0]); // /home/joey/test"
String hdfsPath = args[1]; // /user/hdfs
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:9000");
try {
FileSystem hdfs = FileSystem.get(conf);
FileSystem local = FileSystem.getLocal(conf);
FileStatus[] inputFiles = local.listStatus(localPath);
for(int i = 0; i < inputFiles.length; i++){
String fileName = inputFiles[i].getPath().getName();
if(fileName.startsWith("hadoop")){
FSDataOutputStream out = hdfs.create(new Path(hdfsPath + "/" + fileName));
FSDataInputStream in = local.open(inputFiles[i].getPath());
byte[] buffer = new byte[256];
int bytesRead = 0;
while((bytesRead = in.read(buffer)) > 0){
out.write(buffer, 0, bytesRead);
}
in.close();
out.close();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
该程序引用了如下包:
关于更多的API可以参考官方文档
参考资料
《Hadoop权威指南》
《Hadoop实战》
网易云课堂:大数据工程师
Hadoop学习之旅二:HDFS的更多相关文章
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
- hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用
一.HDFS的相关基本概念 1.数据块 1.在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置. 2.为何数据块如此大,因为数据传输时间 ...
- hadoop学习之旅1
大数据介绍 大数据本质也是数据,但是又有了新的特征,包括数据来源广.数据格式多样化(结构化数据.非结构化数据.Excel文件.文本文件等).数据量大(最少也是TB级别的.甚至可能是PB级别).数据增长 ...
- hadoop学习笔记(二):简单启动
一.hadoop组件依赖关系 二.hadoop日志格式: 两种日志,分别以out和log结尾: 1 以log结尾的日志:通过log4j日志记录格式进行记录的日志,采用日常滚动文件后缀策略来命名日志文件 ...
- 滴滴Booster移动APP质量优化框架 学习之旅 二
推荐阅读: 滴滴Booster移动App质量优化框架-学习之旅 一 Android 模块Api化演练 不一样视角的Glide剖析(一) 续写滴滴Booster移动APP质量优化框架学习之旅,上篇文章分 ...
- Hadoop学习(2)-- HDFS
随着信息技术的高度发展,数据量越来越多,当一个操作系统管辖范围存储不下时,只能将数据分配到更多的磁盘中存储,但是数据分散在多台磁盘上非常不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,因此诞 ...
- Hadoop学习总结之二:HDFS读写过程解析
一.文件的打开 1.1.客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public F ...
- Hadoop 学习笔记(二) HDFS API
4.删除HDFS上的文件 package proj; import java.io.IOException; import org.apache.hadoop.conf.Configuration; ...
- hadoop学习笔记(二):hdfs优点和缺点
优点 其中的10k+,指的是每一个块必须>=1M 缺点 低延迟:是指hadoop处理数据都是以分钟为单位的,而不像storm那样的是以毫秒级为单位的. 高吞吐率:是指你分布式存储的文件块的大小必 ...
随机推荐
- html5 canvas常用api总结(三)--图像变换API
canvas的图像变换api,可以帮助我们更加方便的绘画出一些酷炫的效果,也可以用来制作动画.接下来将总结一下canvas的变换方法,文末有一个例子来更加深刻的了解和利用这几个api. 1.画布旋转a ...
- Web性能优化:What? Why? How?
为什么要提升web性能? Web性能黄金准则:只有10%~20%的最终用户响应时间花在了下载html文档上,其余的80%~90%时间花在了下载页面组件上. web性能对于用户体验有及其重要的影响,根据 ...
- vs15 preview5 离线安装包
1.介绍 vs15是微软打造的新一代IDE,全新的安装方式.官网介绍如下(https://blogs.msdn.microsoft.com/visualstudio/2016/10/05/announ ...
- WebApi基于Token和签名的验证
最近一段时间在学习WebApi,涉及到验证部分的一些知识觉得自己并不是太懂,所以来博客园看了几篇博文,发现一篇讲的特别好的,读了几遍茅塞顿开(都闪开,我要装逼了),刚开始读有些地方不理解,所以想了很久 ...
- Mysql基础代码(不断完善中)
Mysql基础代码,不断完善中~ /* 启动MySQL */ net start mysql /* 连接与断开服务器 */ mysql -h 地址 -P 端口 -u 用户名 -p 密码 /* 跳过权限 ...
- 【从零开始学BPM,Day2】默认表单开发
[课程主题]主题:5天,一起从零开始学习BPM[课程形式]1.为期5天的短任务学习2.每天观看一个视频,视频学习时间自由安排. [第二天课程] Step 1 软件下载:H3 BPM10.0全开放免费下 ...
- Oracle 分页
--1:无ORDER BY排序的写法.(效率最高) --(经过测试,此方法成本最低,只嵌套一层,速度最快!即使查询的数据量再大,也几乎不受影响,速度依然!) SELECT * FROM (SELECT ...
- T-SQL字符串相加之后被截断的那点事
本文出处:http://www.cnblogs.com/wy123/p/6217772.html 字符串自身相加, 虽然赋值给了varchar(max)类型的变量,在某些特殊情况下仍然会被“截断”,这 ...
- python selenium
https://segmentfault.com/a/1190000007249396?_ea=1293878
- 我的MYSQL学习心得(十五) 日志
我的MYSQL学习心得(十五) 日志 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据 ...