EM算法(3):EM算法运用
目录
EM算法(3):EM算法运用
1. 内容
EM算法全称为 Expectation-Maximization 算法,其具体内容为:给定数据集$\mathbf{X}=\{\mathbf{x}_1,\mathbf{x}_2,...,\mathbf{x}_n\}$,假定这个数据集是不完整的,其还缺失了一些信息Y,一个完整的样本Z = {X,Y}。而且假定如果我们能得到完整样本信息的话,训练模型就有闭式解(这个假定对于EM算法理论上可以没有,但是实际操作时我们还是要选定这样的完整信息)。那么EM算法分为两步,第一步(E-step),根据前一步得到的参数$\theta^{(i)}$,计算目标函数的期望$Q(\theta;\theta^{(i)})$:
$Q(\theta;\theta^{(i)}) = E_Y[lnp(X,Y|\theta) | X,\theta^{(i)}]$
$=\int lnp(X,Y|\theta)\cdot p(Y|X,\theta^{(i)})dY$
第二步,选择一个$\theta^{(i+1)}$,使得$Q(\theta;\theta^{(i)})$最大化。
2. EM算法在GMM模型上的运用
上面讲的EM算法大家肯定觉得很空洞、无法理解,这样就对了,光看这个肯定是看不出什么来的,这个时候就需要一个例子来说明,GMM模型是最合适的。
在运用EM算法之前,我们首先要明确,缺失的Y取什么,这个得自己选取。那么由我们之前那篇博客,Y用来代表数据属于某个高斯分量最合适。y取1~k,分别代表k个高斯分量。那么很容易有$p(x,y=l|\pi,\mu,\Sigma) = \pi_l\mathcal{N}(x|\mu_l,\Sigma_l)$,而$p(x|\pi,\mu,\Sigma) = \sum_kp(x,y=k|\pi,\mu,\Sigma) = \sum_k\pi_k\mathcal{N}(x|\mu_k,\Sigma_k)$,这与我么GMM模型的结果也是一致的。
首先我们先计算$Q(\theta;\theta^{(i)})$(这里公式比较复杂,博客园的Latex比较坑,我就直接用Latex写了然后截图了):
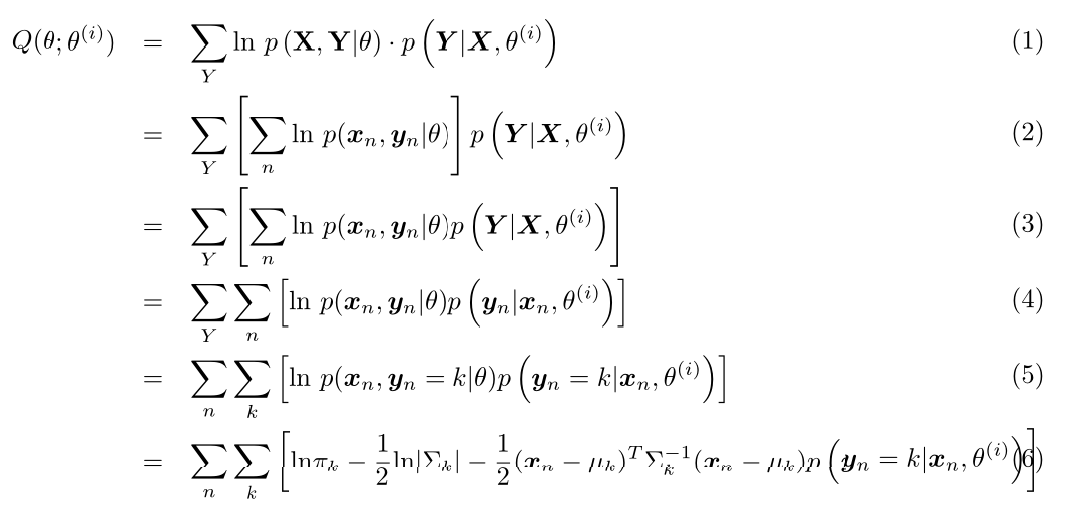
其中$p(\mathbf{y}_n=k|\mathbf{x}_n,\theta^{(i)}) = \frac{p(\mathbf{y}_n=k,\mathbf{x}_n|\theta^{(i)})}{p(\mathbf{x}_n|\theta^{(i)})} = \gamma_{nk}$(推导要使用本小节第二段中的两个式子,$\gamma_{nk}$定义见本系列第二篇博客)。
第二步,我们对$Q(\theta;\theta^{(i)})$进行最值优化,首先对均值进行求导,则有:
$\frac{\partial Q}{\partial \mu_k}=0$ 得到 $\mu_k^{(i+1)} = \frac{\sum_n\gamma_{nk}\mathbf{x}_n}{\sum_n\gamma_{nk}}$
细心的读者可能已经发现,这与我们在第二篇博客中得到的结果是一样的。同样,对$\pi$和$\Sigma$求导得到的结果同样和第二篇博客中一样(有兴趣的读者可以自行推导一下,其中对$\Sigma$求导可能需要参考我的另一篇博文多维高斯概率密度函数对协方差矩阵求导),这样我们就由EM算法得到了GMM的训练算法。
EM算法(3):EM算法运用的更多相关文章
- 【EM算法】EM(转)
Jensen不等式 http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html 回顾优化理论中的一些概念.设f是定义域为实数的函数 ...
- 从决策树学习谈到贝叶斯分类算法、EM、HMM --别人的,拷来看看
从决策树学习谈到贝叶斯分类算法.EM.HMM 引言 最近在面试中,除了基础 & 算法 & 项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法(当然,这完全 ...
- 从决策树学习谈到贝叶斯分类算法、EM、HMM
从决策树学习谈到贝叶斯分类算法.EM.HMM (Machine Learning & Recommend Search交流新群:172114338) 引言 log ...
- Python实现机器学习算法:EM算法
''' 数据集:伪造数据集(两个高斯分布混合) 数据集长度:1000 ------------------------------ 运行结果: ---------------------------- ...
- MM 算法与 EM算法概述
1.MM 算法: MM算法是一种迭代优化方法,利用函数的凸性来寻找它们的最大值或最小值. MM表示 “majorize-minimize MM 算法” 或“minorize maximize MM 算 ...
- K-means聚类算法与EM算法
K-means聚类算法 K-means聚类算法也是聚类算法中最简单的一种了,但是里面包含的思想却不一般. 聚类属于无监督学习.在聚类问题中,给我们的训练样本是,每个,没有了y. K-means算法是将 ...
- EM算法浅析(二)-算法初探
EM算法浅析,我准备写一个系列的文章: EM算法浅析(一)-问题引出 EM算法浅析(二)-算法初探 一.EM算法简介 在EM算法之一--问题引出中我们介绍了硬币的问题,给出了模型的目标函数,提到了这种 ...
- 机器学习经典算法之EM
一.简介 EM 的英文是 Expectation Maximization,所以 EM 算法也叫最大期望算法. 我们先看一个简单的场景:假设你炒了一份菜,想要把它平均分到两个碟子里,该怎么分? 很少有 ...
- EM相关两个算法 k-mean算法和混合高斯模型
转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html http://www.cnblogs.com/jerrylead/ ...
- 机器学习优化算法之EM算法
EM算法简介 EM算法其实是一类算法的总称.EM算法分为E-Step和M-Step两步.EM算法的应用范围很广,基本机器学习需要迭代优化参数的模型在优化时都可以使用EM算法. EM算法的思想和过程 E ...
随机推荐
- angular2开发01
// */ // ]]> angular2开发01 1. angular2 开发准备 1.1. 安装node 1.2. 安装npm 1.3. 运行qickStart 1 angular2 开发准 ...
- Flexigrid从对象中加载数据
(有问题,在找…………) Flexigrid是用来动态加载数据的一种比较好(老)的Jquery表插件,然后有些时候,我们需要其从本地或者jQuery对象中加载数据,比如有这么个需求,页面显示中有两个表 ...
- C#程序以管理员身份运行
选中"Security",在界面中勾选"Enable ClickOnce Security Settings"后,在Properties下就有自动生成app.m ...
- Best Practices for Performance_4.Optimizing Battery Life 获取充电状态、电池信息,"sticky"类型的广播
http://developer.android.com/training/monitoring-device-state/index.htmlhttp://developer.android.com ...
- some notes about spring aop
1 . timeCountIntecetor implements handlerInterceptor { preHandle(); postHandle(); afterComplete(); } ...
- php类中常量的定义
先看下面一段代码: class SVN { const DEFAULT_PATH = "/tmp"; const SVNLOOK_CMD = "/usr/bin/svnl ...
- GDB 调试遇到??的问题
今天总算解决了一个大的bug,爽! 我的程序crash,有了coredump文件,在Linux PC上用arm-linux-gdb debug it. The result is: #0 0x402 ...
- java.lang.ArrayIndexOutOfBoundsException: 1
数组越界 但是我这个也不是这个原因: 在CuiShouDetail.jsp 里,如果 添加上 QiTaDianHua,如果为空就会报错,别的都么有问题null,或者是空格,或者是有数据 1. Stri ...
- xcode:关于Other Linker Flags
一.关于Other Linker Flags xcode中,在“Targets”选项下有Other Linker Flags选项,在这里可以填写xcode链接器的参数,如:-ObjC.-all_loa ...
- [python实现设计模式]-2.模板方法模式---把大象关进冰箱.
平时大家上班都很累,为了增加工作中的欢乐气氛,黄页组准备搞个游戏. 游戏的名字是把大象关进冰箱.游戏很简单,需要把指定的物品放进冰箱. 我们都知道,把大象放进冰箱,分3步. 第一步,打开冰箱门,第二步 ...