PRML读书笔记——3 Linear Models for Regression
Linear Basis Function Models
线性模型的一个关键属性是它是参数的一个线性函数,形式如下:

w是参数,x可以是原始的数据,也可以是关于原始数据的一个函数值,这个函数就叫basis function,记作φ(x),于是线性模型可以表示成:
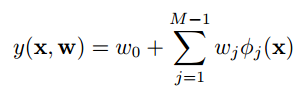
w0看着难受,定义一个函数φ0(x) = 1, 模型的形式再一次简化成:
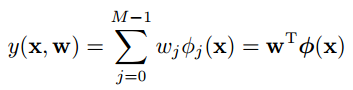
以上就是线性模型的一般形式。basis function有很多选择,例如Gaussian、sigmoid、tanh (tanh(x) = 2 * sigmoid(a) − 1)。
Maximum likelihood and least squares
训练线性模型的时候,假设cost function为sum-of-squares error function,那么minimize cost function 和 maximize likelihood function是等价的。
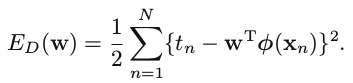
另外一个发现就是,w0最终解出来为target values的均值 和 各个特征的basis function values均值的加权和 的差,如下:
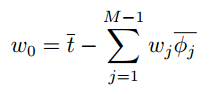
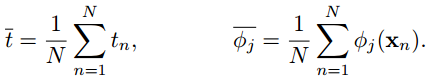
Regularized least squares
一般的正则化形式如下:
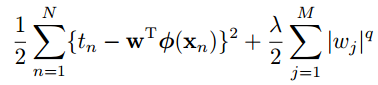
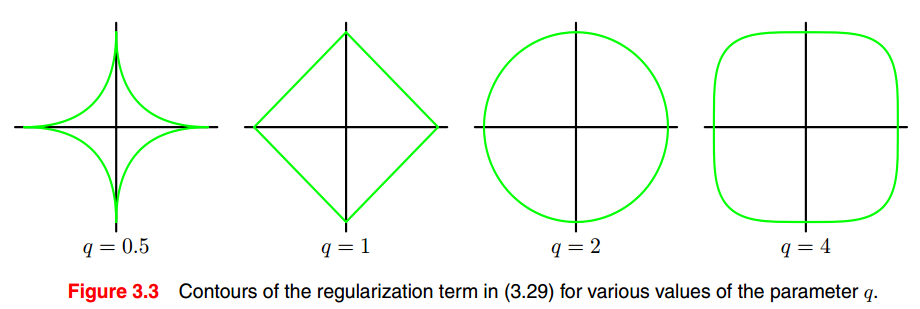
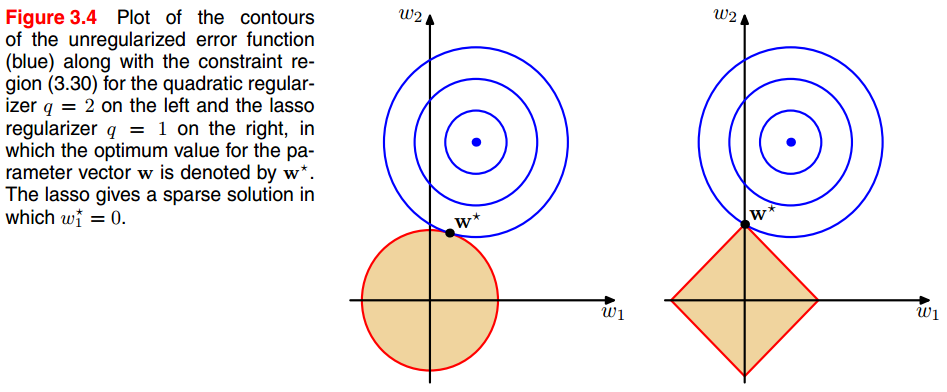
q = 1, 为lasso(least absolute shrinkage and selection operator) 正则化,其特点是,当λ足够大的时候,某些参数会趋向0,看下图。
q = 2, 二次正则化,使得一些参数足够小。
Bias-Variance trade-off
假设y(x, D)代表基于数据集D训练出来的regression function, h(x)代表数据集D中,给定x条件下target value的期望
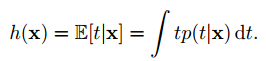
squared loss function可以写成:
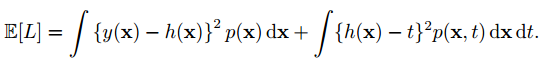
后一项与y(x)无关,考虑前一项积分里面的部分:
{y(x; D) − h(x)}2 = {y(x; D) − ED[y(x; D)] + ED[y(x; D)] − h(x)}2
= {y(x; D) − ED[y(x; D)]}2 + {ED[y(x; D)] − h(x)}2
+2{y(x; D) − ED[y(x; D)]}{ED[y(x; D)] − h(x)}
这样积分取期望后为:
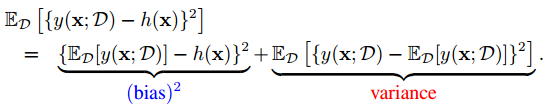
前一项为bias,后一项为variance。
于是loss function的总体希望就为,(bias)2 + variance + noise
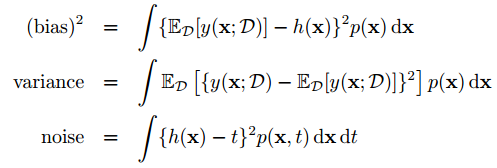
于是就产生了bias-variance trade-off问题, flexible models低bias,高variance;rigid models 高bias,低variance。
在实际应用中,为了观察bias和variance,计算如下:
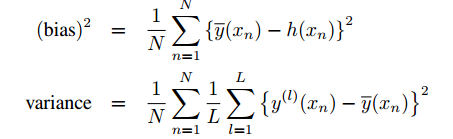
其中:
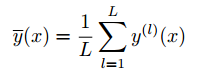
y(l)(x)是prediction function。
Bayesian Linear Regression(该段摘自Jian Xiao(iamxiaojian@gmail.com)的笔记Notes on Pattern Recognition and Machine Learning (Bishop))
Bayesian 方法能够避免 over-fitting 的原因是: Marginalizing over the model parameters instead of making point estimates of their values.
假设有多个 model;观察到的 data set 是 D。 Bayesian 的 model comparison 方法是,比较各个模型的后验概率,即:
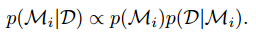
先验概率 p(Mi) allows us to express a preference for different model。可以假设每个模型的先验概率相等,那么剩下要比较的关键是: p(D|Mi) ——model evidence 或 marginal likelihood。
Model averaging V.S. model selection
Model averaging:把多个模型,用各自模型的后验概率加权平均,得到 predictive distribution为
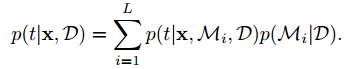
Model selection: 只选择一个模型,即其中后验概率最大的模型。这是一种 approximation to model averaging。以上分析可以看出,各个 model 的后验概率是关键,而计算后验概率的关键又是 model evidence。
从 sampling 的角度看, Mi 相当于 hyper-parameter,而 w 则是 parameter。 一个 model 不同于另一个 model,是因为 hyper-parameter。
The Evidence Approximation
full Bayesian需要marginalize with respect to hyper-parameters as well as parameters,例如hyperparameter是alpha和beta,w是parameter,那么predictive distribution为:
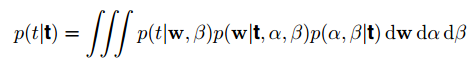
就比较难,这里就考虑一种approximation,给hyperparameters设置一个特定的数值,这个数值由maximizing the marginal likelihood function 来确定。这个方法叫empirical Bayes、 type 2 maximum likelihood、generalized maximum likelihood、evidence approximation(in machine learning)
Previous Chapter | Next Chapter
PRML读书笔记——3 Linear Models for Regression的更多相关文章
- PRML读书笔记——Introduction
1.1. Example: Polynomial Curve Fitting 1. Movitate a number of concepts: (1) linear models: Function ...
- Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面介绍一个线性回归问题,符合高斯分布 一个分类问题,logstic回 ...
- [Scikit-learn] 1.1 Generalized Linear Models - Logistic regression & Softmax
二分类:Logistic regression 多分类:Softmax分类函数 对于损失函数,我们求其最小值, 对于似然函数,我们求其最大值. Logistic是loss function,即: 在逻 ...
- PRML读书会第三章 Linear Models for Regression(线性基函数模型、正则化方法、贝叶斯线性回归等)
主讲人 planktonli planktonli(1027753147) 18:58:12 大家好,我负责给大家讲讲 PRML的第3讲 linear regression的内容,请大家多多指教,群 ...
- PRML读书笔记——机器学习导论
什么是模式识别(Pattern Recognition)? 按照Bishop的定义,模式识别就是用机器学习的算法从数据中挖掘出有用的pattern. 人们很早就开始学习如何从大量的数据中发现隐藏在背后 ...
- PRML-Chapter3 Linear Models for Regression
Example: Polynomial Curve Fitting The goal of regression is to predict the value of one or more cont ...
- Coursera台大机器学习课程笔记10 -- Linear Models for Classification
这一节讲线性模型,先将几种线性模型进行了对比,通过转换误差函数来将linear regression 和logistic regression 用于分类. 比较重要的是这种图,它解释了为何可以用Lin ...
- [Scikit-learn] 1.1 Generalized Linear Models - Lasso Regression
Ref: http://blog.csdn.net/daunxx/article/details/51596877 Ref: https://www.youtube.com/watch?v=ipb2M ...
- PRML读书笔记——线性回归模型(上)
本章开始学习第一个有监督学习模型--线性回归模型."线性"在这里的含义仅限定了模型必须是参数的线性函数.而正如我们接下来要看到的,线性回归模型可以是输入变量\(x\)的非线性函数. ...
随机推荐
- Spring整合web开发
正常整合Servlet和Spring没有问题的 public class UserServlet extends HttpServlet { public void doGet(HttpServlet ...
- iOS GCD学习笔记
// 后台执行: dispatch_async(dispatch_get_global_queue(, ), ^{ // something }); // 主线程执行: dispatch_async( ...
- 【Ajax 基础学习】
http://www.cnblogs.com/guduoduo/p/3681296.html 今天简单的学习了 Ajax 的基础知识,总结在这里.部分代码不是原创,特此说明. [Ajax 简介] AJ ...
- Theano:LSTM源码解析
最难读的Theano代码 这份LSTM代码的作者,感觉和前面Tutorial代码作者不是同一个人.对于Theano.Python的手法使用得非常娴熟. 尤其是在两重并行设计上: ①LSTM各个门之间并 ...
- 修改AspNetPager的CustomInfoHTML,添加自定义样式
AspNetPager控件有一个属性叫CustomInfoHTML,可以把它写在前台页面,如下: <webdiyer:AspNetPager ID=" HorizontalAlign= ...
- activity跳转到新的activity后清除之前的activity
Intent intent = new Intent(A.this, B.class); intent.setFlags(Intent.FLAG_ACTIVITY_CLEAR_TASK | Inten ...
- jenkins,dns错误log过大
http://stackoverflow.com/questions/31719756/how-to-stop-jenkins-log-from-becoming-huge Recently my j ...
- WPF中UserControl和DataTemplate
最新更新: http://denghejun.github.io 前言 前言总是留给我说一些无关主题的言论,WPF作为全新Microsoft桌面或web应用程序显示技术框架, 从08年开始,一直到现在 ...
- Git系列教程一 入门与简介
一.版本控制引入 可能我们都会有这样的经历:创建了一个文件,并对它做了多次更改,当我们想回到其中的某一次更改的时候,由于时间太长记不得那次更改的内容,于是我们在每次大的更改的时候,会创建一个文件的副本 ...
- C# 依赖注入
http://www.cnblogs.com/leoo2sk/archive/2009/06/17/1504693.html 这篇文章真的非常非常好···绝对值得收藏学习. 目录 目录 1 ...