Python模块---Wordcloud生成词云图
wordcloud是Python扩展库中一种将词语用图片表达出来的一种形式,通过词云生成的图片,我们可以更加直观的看出某篇文章的故事梗概。
首先贴出一张词云图(以哈利波特小说为例):

在生成词云图之前,首先要做一些准备工作
1.安装结巴分词库
pip install jieba

Python中的分词模块有很多,他们的功能也都是大同小异,我们安装的结巴分词 是当前使用的最多的类型。
下面我来简单介绍一下结巴分词的用法
结巴分词的分词模式分为三种:
(1)全模式:把句子中所有的可以成词的词语都扫描出来, 速度快,但是不能解决歧义问题
(2)精确模式:将句子最精确地切开,适合文本分析
(3)搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
下面用一个简单的例子来看一下三种模式的分词区别:
import jieba # 全模式:把句子中所有的可以成词的词语都扫描出来, 速度快,但是不能解决歧义问题
text = "哈利波特是一常优秀的文学作品"
seg_list = jieba.cut(text, cut_all=True)
print(u"[全模式]: ", "/ ".join(seg_list)) # 精确模式:将句子最精确地切开,适合文本分析
seg_list = jieba.cut(text, cut_all=False)
print(u"[精确模式]: ", "/ ".join(seg_list)) # 默认是精确模式
seg_list = jieba.cut(text)
print(u"[默认模式]: ", "/ ".join(seg_list)) # 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
seg_list = jieba.cut_for_search(text)
print(u"[搜索引擎模式]: ", "/ ".join(seg_list))
下面是对这句话的分词方式:
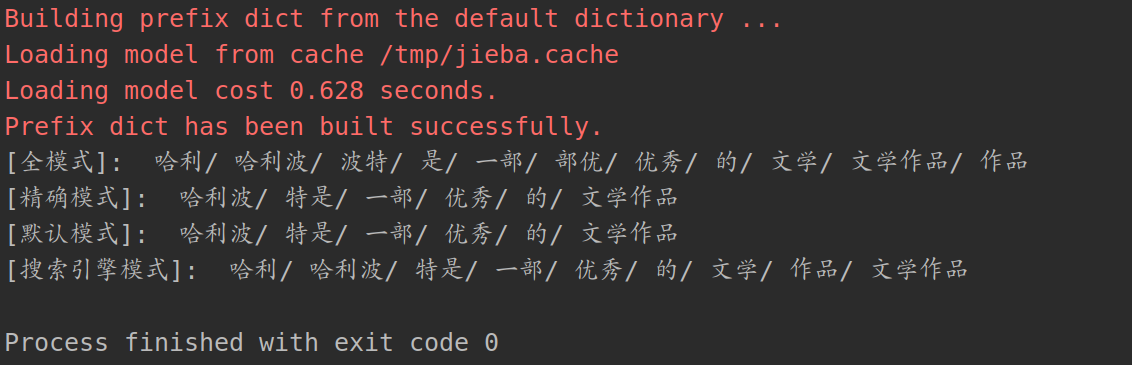
通过这三种分词模式可以看出,这些分词模式并没有很好的划分出“哈利波特”这个专有名词,这是因为在结巴分词的字典中并没有记录这个名词,所以需要我们手动添加自定义字典
添加自定义字典:找一个方便引用的位置 (下图的路径是我安装的位置),新建文本文档(后缀名为.txt),将想添加的词输入进去(注意输入格式),保存并退出

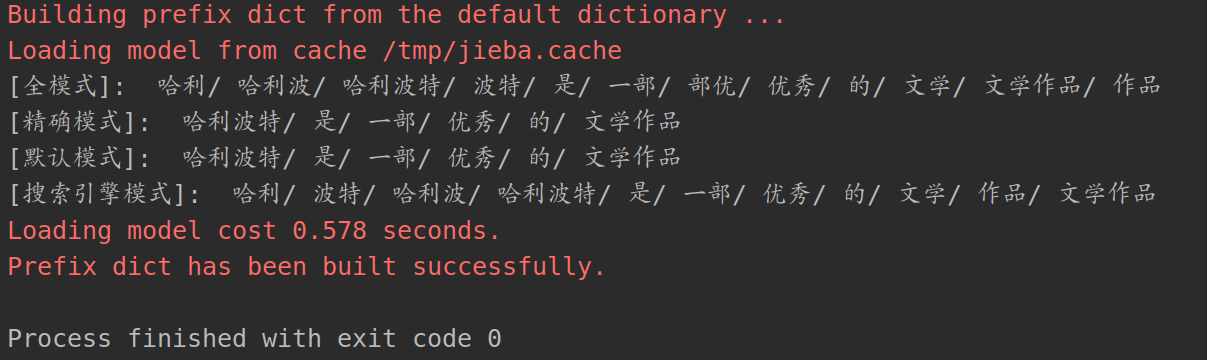
在上面的代码中加入自定义字典的路径,再点击运行
jieba.load_userdict("/home/jmhao/anaconda3/lib/python3.7/site-packages/jieba/mydict.txt")
分词结果,可以看出“哈利波特”这个词已经被识别出来了
结巴分词还有另一个禁用词的输出结果
stopwords = {}.fromkeys(['优秀', '文学作品'])
#添加禁用词之后
seg_list = jieba.cut(text)
final = ''
for seg in seg_list:
if seg not in stopwords:
final += seg
seg_list_new = jieba.cut(final)
print(u"[切割之后]: ", "/ ".join(seg_list_new))
可以看到输出结果中并没有“优秀”和“文学作品”两个词

结巴分词还有很多比较复杂的操作,具体的可以去官网查看,我就不再过多的赘述了
下面我们正式开始词云的制作
首先下载模块,这里我所使用的环境是Anaconda,由于Anaconda中包含很多常用的扩展包,所以这里只需要下载wordcloud。若使用的环境不是Anaconda,则另需安装numpy和PIL模块
pip install wordcloud
然后我们需要找一篇文章并使用结巴分词将文章分成词语的形式
# 分词模块
def cut(text):
# 选择分词模式
word_list = jieba.cut(text,cut_all= True)
# 分词后在单独个体之间加上空格
result = " ".join(word_list)
# 返回分词结果
return result
这里我在当前文件夹下创建了一个文本文档“xiaoshuo.txt”,并复制了一章的小说作为词云的主体文字
使用代码控制,打开并读取小说的内容
#导入文本文件,进行分词,制作词云
with open("xiaoshuo.txt") as fp:
text = fp.read()
# 将读取的中文文档进行分词
text = cut(text)
在网上找到一张白色背景的图片下载到当前文件夹,作为词云的背景图(若不指定图片,则默认生成矩形词云)
#设置词云形状,若设置了词云的形状,生成的词云与图片保持一致,后面设置的宽度和高度将默认无效
mask = np.array(image.open("monkey.jpeg"))
接下来可以根据喜好来定义词云的颜色、轮廓等参数 下面为常用的参数设置方法
| font_path : "字体路径" | 词云的字体样式,若要输出中文,则跟随中文的字体 |
| width = n | 画布宽度,默认为400像素 |
| height = n | 画布高度,默认为400像素 |
| scale = n | 按比例放大或缩小画布 |
| min_font_size = n | 设置最小的字体大小 |
| max_font_size = n | 设置最大的字体大小 |
| stopwords = 'words' | 设置要屏蔽的词语 |
| background_color = ''color | 设置背景板颜色 |
| relative_scaling = n | 设置字体大小与词频的关联性 |
| contour_width = n | 设置轮廓宽度 |
| contour_color = 'color' | 设置轮廓颜色 |
完整代码
#导入词云库
from wordcloud import WordCloud
#导入图像处理库
import PIL.Image as image
#导入数据处理库
import numpy as np
#导入结巴分词库
import jieba # 分词模块
def cut(text):
# 选择分词模式
word_list = jieba.cut(text,cut_all= True)
# 分词后在单独个体之间加上空格
result = " ".join(word_list)
return result #导入文本文件,进行分词,制作词云
with open("xiaoshuo.txt") as fp:
text = fp.read()
# 将读取的中文文档进行分词
text = cut(text)
#设置词云形状
mask = np.array(image.open("monkey.jpeg"))
#自定义词云
wordcloud = WordCloud(
# 遮罩层,除白色背景外,其余图层全部绘制(之前设置的宽高无效)
mask=mask,
#默认黑色背景,更改为白色
background_color='#FFFFFF',
#按照比例扩大或缩小画布
scale=1,
# 若想生成中文字体,需添加中文字体路径
font_path="/usr/share/fonts/bb5828/逐浪雅宋体.otf"
).generate(text)
#返回对象
image_produce = wordcloud.to_image()
#保存图片
wordcloud.to_file("new_wordcloud.jpg")
#显示图像
image_produce.show()
注:若想要生成图片样式的词云图,找到的图片背景必须为白色,或者使用Photoshop抠图替换成白色背景,否则生成的词云为矩形
我的词云原图:

生成的词云图:

Python模块---Wordcloud生成词云图的更多相关文章
- python根据文本生成词云图
python根据文本生成词云图 效果 代码 from wordcloud import WordCloud import codecs import jieba #import jieba.analy ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- 小白学Python(12)——pyecharts ,生成词云图 WordCloud
WordCloud(词云图) from pyecharts import options as opts from pyecharts.charts import Page, WordCloud fr ...
- (数据科学学习手札71)在Python中制作个性化词云图
本文对应脚本及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 词云图是文本挖掘中用来表征词频的数据可视化 ...
- 用Python制作酷炫词云图,原来这么简单!
一.简介词云图是文本挖掘中用来表征词频的数据可视化图像,通过它可以很直观地展现文本数据中地高频词:! 图1 词云图示例 在Python中有很多可视化框架可以用来制作词云图,如pyecharts,但这些 ...
- 已知词频生成词云图(数据库到生成词云)--generate_from_frequencies(WordCloud)
词云图是根据词出现的频率生成词云,词的字体大小表现了其频率大小. 写在前面: 用wc.generate(text)直接生成词频的方法使用很多,所以不再赘述. 但是对于根据generate_from_f ...
- python:用wordcloud生成一个文本的词云
今天学习了wordcloud库,对<三国演义>生成了词云图片,非常漂亮.就想多尝试几个,结果发现一系列问题.最常出现的一个错误就是"UnicodeDecodeError : .. ...
- 用Python和WordCloud绘制词云(内附让字体清晰的秘笈)
环境及模块: Win7 64位 Python 3.6.4 WordCloud 1.5.0 Pillow 5.0.0 Jieba 0.39 目标: 绘制安徽省2018年某些科技项目的词云,直观展示热点. ...
- Excel催化剂开源第27波-Excel离线生成词云图
在数据分析领域,词云图已经成为在文本分析中装逼的首选图表,大家热烈地讨论如何在Python上做数据分析.做词云图. 数据分析从来都是Excel的主战场,能够让普通用户使用上的技术才是最有价值的技术,一 ...
随机推荐
- 如何安装及使用honmaple社区程序 · honmaple's blog · 风落花语风落天,花落风雨花落田.
Table of Contents 1. 如何安装及使用 1.1. 安装需要的package 1.2. 配置config 1.3. 注释下面代码 1.4. 初始化数据库 1.5. 创建管理员账户 2. ...
- LISTAGG函数
官网进入 该函数作用是可以实现对列值得拼接: 根据官网介绍,可以对列值排序进行拼接,也可以分组拼接 1.1运行结果 1.2运行结果 2运行结果 注意该函数提供的 over( partition by ...
- Js对于数组去重提高效率一些心得
最近在找工作,好几次面试都问过数组去重的问题.虽然问的都不一样,但是核心思想是没有变的. 第一种是比较常规的方法 思路: 构建一个新的数组存放结果 for循环中每次从原数组中取出一个元素,用这个元素循 ...
- 2、【Spark】Spark环境搭建(集群方式)
Spark集群方式搭建结构如图所示,按照主从方式.
- C#连接Informix数据库
最近在工作中遇到了需要连接Informix数据库的问题,在通过研究后发现了可以通过多种方式实现,我选择的是通过IBM Informix .NET Provider.该方式需要引用IBM.Data.In ...
- Spring Boot从入门到精通(六)集成Redis实现缓存机制
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言 ...
- vijos 1011 清帝之惑之顺治
背景 顺治帝福临,是清朝入关后的第一位皇帝.他是皇太极的第九子,生于崇德三年(1638)崇德八年八月二ten+six日在沈阳即位,改元顺治,在位18年.卒于顺治十八年(1661),终24岁. 顺治即位 ...
- Python3爬虫使用requests爬取lol英雄皮肤
本人博客:https://xiaoxiablogs.top 此次爬取lol英雄皮肤一共有两个版本,分别是多线程版本和非多线程版本. 多线程版本 # !/usr/bin/env python # -*- ...
- A. Reorder the Array
You are given an array of integers. Vasya can permute (change order) its integers. He wants to do it ...
- nohub 将程序永久运行下去
今天看了一遍文章,一直以为将程序制成sh脚本,通过crontab来间隔执行以为是真的不断执行,后来才发现是错误的,每隔一段时间都会执行一次,都会占用一个进程,难怪一看进程几十来个同样名字的进程在运行 ...