hadoop ozone入门
简介
- 众所周知,HDFS是大数据存储系统,并在业界得到了广泛的使用。但是无论大集群还是小集群其扩展性都受NameNode的限制,虽然HDFS可以通过Federation进行扩展,但是依然深受小文件和4亿个文件的困扰。
- 于是分布式key-value存储系统Ozone诞生了,Ozone能够轻松管理小文件和大文件。
- 其他能处理小文件的存储方案有Hbase, ceph等, 本人目前所了解的是ceph性能更好, ozone由于未在上产环境中实践过, 性能对比尚不可知。
- Ozone是专门为Hadoop设计的可扩展的分布式对象存储系统。
- Hadoop生态中的其它组件如Spark、Hive和Yarn不需要任何修改就可以直接运行在Ozone之上。
- Ozone的使用方式也较为丰富,可以通过命令行直接使用也有java客户端接口,而且接口支持RPC和REST。
- 组成:
- volumes
- Volumes只有管理员能够创建和删除,类似账号的概念,管理员一般都是给某个团队或者组织创建一个Volume。
- Buckets是在Volume下,一个Volume可以包含n个Buckets,但是Buckets下面只能是Keys。
- buckets
- 类似目录, 但只能有一层, 因为Buckets中不能包含其它Buckets。
- Keys
- Keys就是具体的对象,在Buckets中是唯一的,其名字可以是任意字符串,其值就是需要存储的数据,也就是具体的文件。
- 目前ozone对key的大小没有限制,bucket可以包含n个keys。
- volumes
设计原则
- Ozone是由一群对大规模Hadoop集群有着丰富运维和管理经验的工程师设计开发的,因此HDFS在实践中的优缺点深刻的影响着Ozone的设计和优化。
- Strongly Consistent(强一致性)
- Architectural Simplicity(结构简化)
- Ozone尽可能的将架构进行简单化,即使牺牲掉一些可扩展性,但是在扩展性上Ozone并不逊色。Ozone目前在单个集群上可以存储10亿个对象。
- Layered Architecture(分层结构)
- Ozone将namespace management与块和节点管理层分开,允许用户分别对其进行扩展。
- Painless Recovery(无痛恢复)
- Open Source(开源)
- Interoperability with Hadoop Ecosystem(具有与Hadoop生态系统的互用性)
架构
架构图
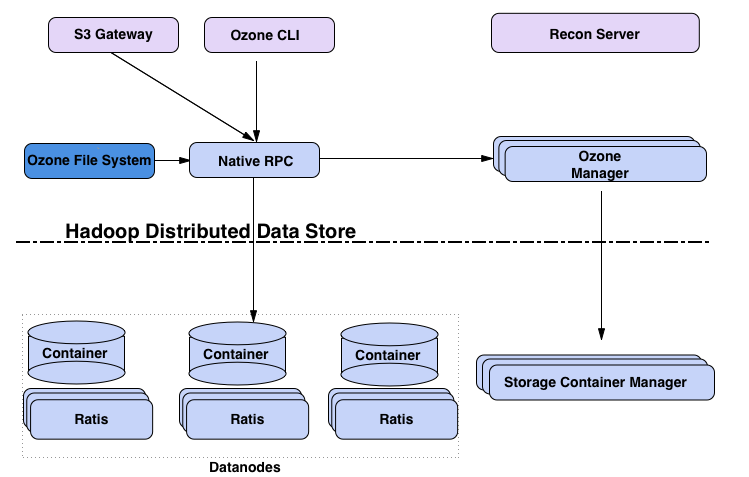
Ozone Manager(OM)
- OzoneManager是一个server服务,主要负责Ozone的namespace,记录所有的volume, bucket和key操作。有点类似HDFS的namenode
Storage Container Manager(SCM)
- 类似HDFS中的block manager,是Ozone中一个非常重要的组件,用来管理container的,为OM提供基于block和container的服务。
- container是由一些block组成的集合,这些block相互之间没有关系。
- SCM与数据节点协同工作从而维护群集所需的复制级别
Datanodes
- 如果是基于HDFS部署的Ozone也就是Ozone数据节点功能以插件的功能运行在HDFS的datanode中,则就指HDFS的datanode。
单节点部署
需要先部署Hadoop3.0+,具体部署请参考: https://www.cnblogs.com/ronnieyuan/p/11518913.html
将tar包解压并修改ozone目录名
tar -zxvf hadoop-ozone-0.4.1-alpha.tar.gz -C /opt/ronnie/
mv ozone-0.4.1-alpha/ ozone-0.4.1
将Ozone的相关内容复制到Hadoop的home目录:
cd ozone-0.4.1/
cp libexec/ozone-config.sh /opt/ronnie/hadoop-3.1.2/libexec
cp -r share/ozone /opt/ronnie/hadoop-3.1.2/share
cp -r share/hadoop/ozoneplugin /opt/ronnie/hadoop-3.1.2/share/hadoop/
vim ~/.bashrc 添加ozone环境变量 并source ~/.bashrc 使变量生效。
# Ozone
export OZONE_HOME=/opt/ronnie/ozone-0.4.1
export PATH=$OZONE_HOME/bin:$PATH
利用Ozone的命令生成conf文件
ozone genconf /opt/tmp/ # 我先给他生成到一个临时目录
修改该配置文件
vim /opt/tmp/ozone-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<configuration>
<property>
<name>ozone.enabled</name>
<value>true</value>
<tag>OZONE, REQUIRED</tag>
<description>
Status of the Ozone Object Storage service is enabled.
Set to true to enable Ozone.
Set to false to disable Ozone.
Unless this value is set to true, Ozone services will not be started in
the cluster. Please note: By default ozone is disabled on a hadoop cluster.
</description>
</property>
<property>
<name>ozone.om.address</name>
<value>localhost</value>
<tag>OM, REQUIRED</tag>
<description>
The address of the Ozone OM service. This allows clients to discover
the address of the OM.
</description>
</property>
<property>
<name>ozone.metadata.dirs</name>
<value>/opt/ronnie/hadoop-3.1.2/ozone</value>
<tag>OZONE, OM, SCM, CONTAINER, STORAGE, REQUIRED</tag>
<description>
This setting is the fallback location for SCM, OM, Recon and DataNodes
to store their metadata. This setting may be used only in test/PoC
clusters to simplify configuration. For production clusters or any time you care about performance, it is
recommended that ozone.om.db.dirs, ozone.scm.db.dirs and
dfs.container.ratis.datanode.storage.dir be configured separately.
</description>
</property>
<property>
<name>ozone.scm.client.address</name>
<value>localhost</value>
<tag>OZONE, SCM, REQUIRED</tag>
<description>
The address of the Ozone SCM client service. This is a required setting. It is a string in the host:port format. The port number is optional
and defaults to 9860.
</description>
</property>
<property>
<name>ozone.scm.names</name>
<value>localhost</value>
<tag>OZONE, REQUIRED</tag>
<description>
The value of this property is a set of DNS | DNS:PORT | IP
Address | IP:PORT. Written as a comma separated string. e.g. scm1,
scm2:8020, 7.7.7.7:7777.
This property allows datanodes to discover where SCM is, so that
datanodes can send heartbeat to SCM.
</description>
</property>
<property>
<name>ozone.replication</name>
<value>1</value>
</property>
</configuration>改配置之后复制到Hadoop3.0的conf目录中
cp /opt/tmp/ozone-site.xml /opt/ronnie/hadoop-3.1.2/etc/hadoop/
将Ozone运行在HDFS之上的话,需要在hdfs-site.xml中添加如下内容:
<property>
<name>dfs.datanode.plugins</name>
<value>org.apache.hadoop.ozone.HddsDatanodeService</value>
</property>
start-dfs.sh 启动hdfs
其次启动scm和om,要先启动scm再启动om,而且在第一次启动的时候要先初始化,命令如下:
ozone scm --init
ozone --daemon start scm
ozone om --init
ozone --daemon start om
一切正常就可以在OM的UI上查看信息,OM默认端口上9874
hadoop ozone入门的更多相关文章
- Hadoop快速入门
目的 这篇文档的目的是帮助你快速完成单机上的Hadoop安装与使用以便你对Hadoop分布式文件系统(HDFS)和Map-Reduce框架有所体会,比如在HDFS上运行示例程序或简单作业等. 先决条件 ...
- hadoop pig入门总结
在这里贴一个pig源码的分析,做pig很长时间没做笔记,不包含任何细节,以后有机会再说吧 http://blackproof.iteye.com/blog/1769219 hadoop pig入门总结 ...
- Hadoop高速入门
Hadoop高速入门 先决条件 支持平台 GNU/Linux是产品开发和执行的平台. Hadoop已在有2000个节点的GNU/Linux主机组成的集群系统上得到验证. Win32平台是作为开发平台支 ...
- 详细的Hadoop的入门教程-完全分布模式Fully-Distributed Operation
1. 前面在伪分布模式下已经创建了一台机器,为了统一命名,hostname更名为hadoop01.然后再克隆2台机器:hadoop02. hadoop03:将第一台机器hadoop01上的伪分布停止, ...
- 1.2 Hadoop快速入门
1.2 Hadoop快速入门 1.Hadoop简介 Hadoop是一个开源的分布式计算平台. 提供功能:利用服务器集群,根据用户定义的业务逻辑,对海量数据的存储(HDFS)和分析计算(MapReduc ...
- Hadoop大数据学习视频教程 大数据hadoop运维之hadoop快速入门视频课程
Hadoop是一个能够对大量数据进行分布式处理的软件框架. Hadoop 以一种可靠.高效.可伸缩的方式进行数据处理适用人群有一定Java基础的学生或工作者课程简介 Hadoop是一个能够对大量数据进 ...
- hadoop MapReduce 入门
原创播客,如需转载请注明出处.原文地址:http://www.cnblogs.com/crawl/p/7687120.html ------------------------------------ ...
- hadoop(1)入门
hadoop入门(一) 一.概述 1.什么是hadoop hadoop不仅是一个用于存储分布式文件系统,还是设计用来在有通用计算设备组成的大型集群上执行的分布式应用的基础框架. hadoop框架最 ...
- 大数据之Hadoop技术入门汇总
今天,小编对Hadoop入门学习知识进行了汇总,帮助大家更好地入手大数据.小编关于Hadoop入门总共发写了12篇原创文章,文章是参照尚硅谷大数据视频教程来进行撰写的. 今天,小编带你解锁正确的阅读顺 ...
随机推荐
- 二十二 XML校验器
Struts2提供的校验器及其规则:
- 【转】PowerDesigner数据库视图同时显示Code和Name
1.按顺序打开: Tools>>>Display Preference 2.依次点击 选中Code打钩,并点击箭头指向图标把Code置顶 3.最终效果图 原文链接
- 1.HTTP与HTTPS区别
1.HTTP与HTTPS区别 HTTP协议默认采用80端口 HTTPS协议默认采用443 HTTPS相较于HTTP协议更安全一些,采用SSL+安全证书,但是效率低 2.使用代码格式模拟HTTP请求(H ...
- 小KING教你做android项目(二)---实现登陆页面并跳转和简单的注册页面
原文:http://blog.csdn.net/jkingcl/article/details/10989773 今天我们主要来介绍登陆页面的实现,主要讲解的就是涉及到的布局,以及简单的跳 ...
- Kafka 启动报错java.io.IOException: Can't resolve address.
阿里云上 部署Kafka 启动报错java.io.IOException: Can't resolve address. 本地调试的,报错 需要在本地添加阿里云主机的 host 映射 linux ...
- 2.分析Ajax请求并抓取今日头条街拍美图
import requests from urllib.parse import urlencode # 引入异常类 from requests.exceptions import RequestEx ...
- Python 之并发编程之进程下(事件(Event())、队列(Queue)、生产者与消费者模型、JoinableQueue)
八:事件(Event()) # 阻塞事件: e = Event() 生成事件对象e e.wait() 动态给程序加阻塞,程序当中是否加阻塞完全取决于该对象中的is_set() [默认返回值 ...
- nginx_1_初始nginx
一.nginx简介: nginx是一个性能优秀的web服务器,同时还提供反向代理,负载均衡,邮件代理等功能.是俄罗斯人用C语言开发的开源软件. 二.安装nginx step1:安装依赖库 pcre(支 ...
- 在Windows中实现Java调用DLL(转载)
本文提供调用本地 C 代码的 Java 代码示例,包括传递和返回某些常用的数据类型.本地方法包含在特定于平台的可执行文件中.就本文中的示例而言,本地方法包含在 Windows 32 位动态链接库 (D ...
- 利用SSH在本机和远程服务器之间传输文件或文件夹
1.从远程服务器上下载文件到本机 scp <服务器用户名>@<服务器地址>:<服务器中要下载的文件路径> <下载到本机的绝对路径> 2.从本机上传本地文 ...