吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值,
用 Python 在网页上收集数据,不仅抓取数据的操作简单,
而且其数据分析功能也十分强大。
通过 Python 的时lib 组件中的 urlparse 函数,可轻松解
析指定网址的内容,在接收返回的 ParseResult 对象后,即
可通过其属性取出网址中各项有用信息 。
Python 还可进一步用 requests 函数抓取网页源代码,
再通过相关语句或正则表达式搜索得到指定的数据。
如果要抓取的数据比较复杂, Python 还可以通过功能
更为强大的网页解析工具 Beautifulsoup ,来对特定的网页
及目标进行抓取与分析。
网址解析
想要抓取网站的数据,必须先指定网址及所需参数 。因 此理解网址的构成方式
是进行网站数据抓取的基本技能。
以中国大陆地区 PM2.5 查询网站 http://www.prn25x.com/为例,其中的数据是
根据城市来查询的,如果要查询北京市的 PM2 .5 数据,则要在网址后面加上“ city/
beijing.htm 飞即 h忧p: //www.prn25x.com/city/beijing.htm
通过 Python 的 urlli b 组件中的 urlparse 函数,可以对网址进行解析,其返回值是
元组型 ParseResult 对象,通过该对象的属性就可以得到网址中的各项参数。
ParseResult 对象属性如下表 :
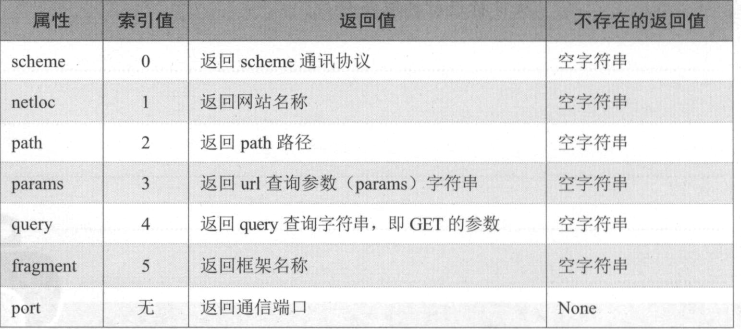
例如:解析中国大陆地区 PM2.5 查询网站。
from urllib.parse import urlparse url = 'http://www.pm25x.com/city/beijing.htm'
o = urlparse(url)
print(o) print("scheme={}".format(o.scheme)) # http
print("netloc={}".format(o.netloc)) # www.pm25x.com
print("port={}".format(o.port)) # None
print("path={}".format(o.path)) # /city/beijing.htm
print("query={}".format(o.query)) # 空

网页数据抓取
requests 用于抓取网页源代码,由于它比内置 urllib 模块好用,因此己经逐渐取
代了 urllib 模块。抓取源代码后可以用 in 或正则表达式搜索获取所需的数据。
用 requests 抓取网页源代码
导入 reques也后,我们可用 requests .getO 函数模拟 HπP GET 方法发出 一个请求
( Request )到远程的服务器( Server ),当服务器接受请求后,就会响应( Response )井
返回网页内容(源代码),设置正确的编码格式,即可通过text 属性取得网址中的源代码 。
例如 : 以 GBK 编码抓取“万水书苑”的源代码。
import requests url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="GBK"
print(html.text)

取得网页的源代码后,即可以对源代码加以处理。例如 : 以把每一行分割成列表,
并去除换行符。
import requests url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="gbk"
htmllist = html.text.splitlines()
for row in htmllist:
print(row)

搜索指定字符串
用 text 属性取得的源代码其实是一大串字符串,如果想搜索其中指定的字符或
字符串,可使用 m 来完成。例如,查询是否含有“新概念”字符串。

也可以一行一行依次搜索,并统计该字符串出现次数 。 例如,搜索万水书苑网
站的首页出现“新概念”字符串的次数。
import requests url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="gbk" htmllist = html.text.splitlines()
n=0
for row in htmllist:
if "新概念" in row:
n+=1
print("找到 {} 次!".format(n))
用正则表达式抓取网页内容
实际应用中,我们需搜索的字符串可能较复杂,有时用 m 根本无法完成。比如
要搜索网站中的超链接、电话号码等,对这种复杂搜索,就要用到正则表达式了。
正则表达式的英文全称是 regu lar expression (简称 regex ) 。 正则表达式就是由类
似 Windows 中搜索文件时用到的通配符符号所构成的公式,用于实现字符串的复杂
搜索 。
网站 http : //pythex.org/ 可以测试正则表达式的结果是否正确 。 假如我们要用正则
表达式表达一 串整数数字,可以用“[O 123456789 ] +这个表达式”,其中,中括号 门
中的一堆字符表示合法的字符,后面的加号“+”表示重复 1 次或无数次,因此,该
表达式就可以表达像 126706 、 9902 、 8 等样式的数字 。
在正则表达式中,为了简化输入,还可以用“ [ 0-9 ] +这样的缩写”表达同样的含
义,其中的 0-9 其实就表示了 0123456789 0 甚至我们还可以再度缩写成[\d] +,其中的 \d
就表示由数字所构成的字符集合。
常见的正则表达式功能介绍




创建正则表达式对象
要使用 正则表达式, 需要先导入 re 包,再用 re 包提供的 compile 方法创建一个
正则表达式对象,语法如下 :

创建正则表达式对象后,再利用正则表达式对象的方法搜索指定的字符串。正
则表达式对象包含了下列方法 :

match (string)方法
在 s tring 中查找符合正则表达式规则的字符串,遇到第一个不符合字符时结束查找,并把结果存入 match 对象( obj e ct )中 : 若没找到符合的字符,返回 None 。
import re
pat = re . compile ( ’ [a - z ]+ ’ )
m = pat . match (’ teml2po ’ ) #简便起见,我们把 ma tc h 对象的伯赋给 m
print(m)
上例会返回"<_sre.SRE_Match object; s pan=( O,匀, mat c h=’ te rn’〉 ”对象, 并将结
果存入 match 对象中。我们通过 match 对象的方法即可得到相应的结果 。
match 对象包含的方法如下 :


直接调用 re.match ()方法
直接调用的语法格式为 r巳 . match ( 正则表达式,搜索字符串)。它包含两个参 .
数, 习 惯上我们会在第一个参数前加上r字符,用于告诉编译器这个参数是正则表 :
达式;第 二个参数传递待投索的字符串,这样就可省去先用 r e.co mpil e 方法创建正’
: 则表达式的 步骤.
import re m = re.match(r'[a-z]+','tem12po')
print(m) if not m==None:
print(m.group())
print(m.start())
print(m.end())
print(m.span())



import re
pat = re.compile('[a-z]+')
m = pat.search('3tem12po')
print(m) # <_sre.SRE_Match object; span=(1, 4), match='tem'>
if not m==None:
print(m.group()) # tem
print(m.start()) #
print(m.end()) #
print(m.span()) # (1,4)

上例若用 match 方法搜索 ,得到的结果将会是 None 。

例如 ,用
findall 方法搜索“ teml2po ”字符串,代码如下 。
import re
pat = re.compile('[a-z]+')
m = pat.findall('tem12po')
print(m) # ['tem', 'po']
吴裕雄--天生自然python学习笔记:WEB数据抓取与分析的更多相关文章
- 吴裕雄--天生自然python学习笔记:python爬虫与网页分析
我们所抓取的网页源代码一般都是 HTML 格式的文件,只要研究明白 HTML 中 的标签( Tag )结构,就很容易进行解析并取得所需数据 . HTML 网页结构 HTML 网 页是由许多标签( Ta ...
- 吴裕雄--天生自然python学习笔记:pandas模块强大的数据处理套件
用 Python 进行数据分析处理,其中最炫酷的就属 Pa ndas 套件了 . 比如,如果我 们通过 Requests 及 Beautifulsoup 来抓取网页中的表格数据 , 需要进行较复 杂的 ...
- 吴裕雄--天生自然python学习笔记:python爬虫PM2.5 实时监测显示器
PM2.5 对人体的健康影响很大,所以空气中的 PM2.5 实时信息受到越来越多的关注. Python 的 Pandas 套件不但可以自动读取网页中的表格 数据 , 还可对数据进行修改.排序等处理,也 ...
- 吴裕雄--天生自然python学习笔记:pandas模块导入数据
有时候,手工生成 Pandas 的 DataFrame 数据是件非常麻烦的事情,所以我们通 常会先把数据保存在 Excel 或数据库中,然后再把数据导入 Pandas . 另 一种情况是抓 取网页中成 ...
- 吴裕雄--天生自然python学习笔记:python实现自动网页测试
Python 可实现的网页测试的功能十分强大,甚至能通 过编程来实现让绝大多数的测试过程自动化. 这对很多开 发者来说,绝对是不可多得的神器. hash lib 纽件可以判别文件是否有过更改,只需要用 ...
- 吴裕雄--天生自然python学习笔记:beautifulsoup库的使用
Beautiful Soup 库简介 Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能.它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简 ...
- 吴裕雄--天生自然python学习笔记:python 用pyInstaller模块打包文件
要想在没有安装 Python 集成环境的电脑上运行开发的 Python 程序,必须把 Python 文件打包成 .exe 格式的可执行 文件. Python 的打包工作 PyInstaller 提供了 ...
- 吴裕雄--天生自然python学习笔记:python 文件批量查找
在多个文本文件中查找 我们首先来学习文本文件的查找字符 . 我们通过 os.walk 扩大查找范围, 查找指定目录和子目录下的文件. 应用程序总览 读取 当 前目录及子目录下的所有 PY 和 txt ...
- 吴裕雄--天生自然python学习笔记:Python uWSGI 安装配置
本文主要介绍如何部署简单的 WSGI 应用和常见的 Web 框架. 以 Ubuntu/Debian 为例,先安装依赖包: apt-get install build-essential python- ...
随机推荐
- gradle配置多个代码仓库repositories
repositories { mavenCentral() maven { url "https://jitpack.io" } maven { url "http:// ...
- IO流的学习以及统计次数最多的单词
IO流: 处理数据类型:字节流(InputStream OutputStream)和字节流(Reader Writer) 数据流向不同:输入流和输出流(FileInputStream File ...
- 内存管理之栈stack
1.什么是栈 栈是一种数据结构,C语言中使用栈来保存局部变量.栈是被发明出来管理内存的.2.栈管理内存的特点(小内存.自动化) 先进后出 FILO first in last out ...
- HttpClient4.x 上传文件
https://blog.csdn.net/wsdtq123/article/details/78888734
- dfs--迷宫
题目背景 给定一个N*M方格的迷宫,迷宫里有T处障碍,障碍处不可通过.给定起点坐标和终点坐标,问: 每个方格最多经过1次,有多少种从起点坐标到终点坐标的方案.在迷宫中移动有上下左右四种方式,每次只能移 ...
- spring手动回滚当前事务
通常情况下,主动回滚事务,可以手动抛异常即可,不抛异常可以如下方式回滚 TransactionAspectSupport.currentTransactionStatus().setRollbackO ...
- PAT Basic 1013 数素数 (20) [数学问题-素数]
题目 令Pi表示第i个素数.现任给两个正整数M <= N <= 10^4,请输出PM到PN的所有素数. 输⼊格式: 输⼊在⼀⾏中给出M和N,其间以空格分隔. 输出格式: 输出从PM到PN的 ...
- StdinNotImplementedError: raw_input was called, but this frontend does not support input requests.
当时VS CODE内嵌的jupyter 交互界面的时候,出现了这个错误 原因是,这样的界面不支持行输入.可以使用cmd终端或其他方式运行该文件进行交互输入
- Python—快速排序算法
# _*_ coding=utf-8 _*_ """ 快速排序: 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比 另外一部分的所有数据都要小,然后 ...
- Django专题之ORM
ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描述 ...