Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三、 Spark集群安装
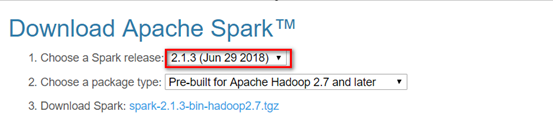
3.1 下载spark安装包
下载地址spark官网:http://spark.apache.org/downloads.html
这里我们使用 spark-2.1.3-bin-hadoop2.7版本.
3.2 规划安装目录
/export/servers
3.3 解压安装包
tar -zxvf spark-2.1.3-bin-hadoop2.7.tgz
3.4 重命名目录
mv spark-2.1.3-bin-hadoop2.7 spark
3.5 修改配置文件
配置文件目录在 /export/servers/spark/conf
vi spark-env.sh 修改文件(先把spark-env.sh.template重命名为spark-env.sh)
|
#配置java环境变量 export JAVA_HOME=/opt/bigdata/jdk1.7.0_67 #指定spark老大Master的IP export SPARK_MASTER_HOST=node1 #指定spark老大Master的端口 export SPARK_MASTER_PORT=7077 |
vi slaves 修改文件(先把slaves.template重命名为slaves)
|
node2 node3 |
3.6 拷贝配置到其他主机
通过scp 命令将spark的安装目录拷贝到其他机器上
scp -r /export/servers/spark node2:/export/servers
scp -r /export/servers/spark node3:/export/servers
3.7 配置spark环境变量(3台服务器都要配置)
将spark添加到环境变量,添加以下内容到 /etc/profile
|
export SPARK_HOME=/export/servers/spark export PATH=$PATH:$SPARK_HOME/sbin:$SPARK_HOME/bin |
注意最后 source /etc/profile 刷新配置
3.8 启动spark
#在主节点上启动spark
|
/export/servers/spark/sbin/start-all.sh |
注意:hadoop中也有start-all.sh 、stop-all.sh 的命令,如果仅仅写start-all.sh,会优先执行hadoop的命令,为了避免和hadoop冲突,命令前要带上路径。
3.9 停止spark
#在主节点上停止spark集群
|
/export/servers/spark/sbin/stop-all.sh |
3.10 spark的web界面
正常启动spark集群后,可以通过访问 http://node1:8080,查看spark的web界面,查看相关信息。
namenode: hdfs://node1:8020-----------------> http://node1:50070
master: spark://node1:7077 --------------------> http://node1:8080
访问
master所在的主机名或者是ip地址:8080
可以看到spark集群的所有信息
spark集群总的资源信息(有多少core 有多少内存)
spark集群已经使用的资源信息
spark集群还剩的资源信息
spark集群对应的worker信息
spark集群正在运行的任务信息
spark集群已经完成的任务信息
在实际工作中我们会搭建一个非常多的服务器组成一个spark集群,每一台服务器都有对应的资源信息
10台worker,每一个worker的cpu核数20,内存大小100G
worker会参与任务的计算,整个spark集群所有的资源信息就是把所有的worker节点资源信息进行累加
spark集群总的资源信息:
内存: 10*100G=1T
cpu核数:10*20=200核
后期会把大量的spark任务提交到spark集群去运行,这个时候就需要考虑spark集群还剩的资源信息,以及后面可能还会跑其他的任务,他们也需要对应的资源。资源分配的时候要合理点。
四、 Spark HA高可用部署
4.1 高可用部署说明
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题。如何解决这个单点故障的问题,Spark提供了两种方案:
(1)基于文件系统的单点恢复(Single-Node Recovery with Local File System)。
主要用于开发或测试环境。当spark提供目录保存spark Application和worker的注册信息,并将他们的恢复状态写入该目录中,这时,一旦Master发生故障,就可以通过重新启动Master进程(sbin/start-master.sh),恢复已运行的spark Application和worker的注册信息。
(2)基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)。
用于生产模式。其基本原理是通过zookeeper来选举一个Master,其他的Master处于Standby状态。将spark集群连接到同一个ZooKeeper实例并启动多个Master,利用zookeeper提供的选举和状态保存功能,可以使一个Master被选举成活着的master,而其他Master处于Standby状态。如果现任Master死去,另一个Master会通过选举产生,并恢复到旧的Master状态,然后恢复调度。整个恢复过程可能要1-2分钟。
4.2 基于zookeeper的Spark HA高可用集群部署
该HA方案使用起来很简单,首先需要搭建一个zookeeper集群,然后启动zooKeeper集群,最后在不同节点上启动Master。具体配置如下:
(1)vim spark-env.sh
注释掉export SPARK_MASTER_HOST=node1
(2)在spark-env.sh添加SPARK_DAEMON_JAVA_OPTS,内容如下:
|
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark" |
参数说明
spark.deploy.recoveryMode:恢复模式(Master重新启动的模式)
有三种:(1)ZooKeeper (2) FileSystem (3)NONE
spark.deploy.zookeeper.url:ZooKeeper的Server地址
spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。
包括Worker,Driver和Application。
注意:
在普通模式下启动spark集群,只需要在主机上面执行start-all.sh 就可以了。
在高可用模式下启动spark集群,先需要在任意一台节点上启动start-all.sh命令。然后在另外一台节点上单独启动master。命令start-master.sh。
补充说明:
|
(1)如何恢复到上一次活着master挂掉之前的状态: 在高可用模式下,整个spark集群就有很多个master,其中只有一个master被zk选举成活着的master,其他的多个master都处于standby,同时把整个spark集群的元数据信息通过zk中节点进行保存。 后期如果活着的master挂掉。首先zk会感知到活着的master挂掉,下面开始在多个处于standby中的master进行选举,再次产生一个活着的master,这个活着的master会读取保存在zk节点中的spark集群元数据信息,恢复到上一次master的状态。整个过程在恢复的时候经历过了很多个不同的阶段,每个阶段都需要一定时间,最终恢复到上个活着的master的转态,整个恢复过程一般需要1-2分钟。 (2)在master的恢复阶段对任务的影响 针对于正在运行的任务,由于它已经分配到了资源,它是不受任何影响. 受影响的就是在当前这个挂掉的阶段,后面提交的新的任务,由于没有活着的master分配资源,该任务是无法运行。 (3)在任意一台机器来执行start-all.sh脚本的前提条件:需要实现任意2台机器之间ssh免密登录。 |
Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2的更多相关文章
- Flink 集群搭建,Standalone,集群部署,HA高可用部署
基础环境 准备3台虚拟机 配置无密码登录 配置方法:https://ipooli.com/2020/04/linux_host/ 并且做好主机映射. 下载Flink https://www.apach ...
- 【Service Fabric】小白入门记录 本地Service Fabric集群安装及设置
本篇内容是自学自记,现在我还不知道Service Fabric究竟是怎么个入门法,反正按照入门教程先进行本地Service Fabric集群的安装,万里路始于足下,要学习总得先把环境装好了才能开始学习 ...
- 近千节点的Redis Cluster高可用集群案例:优酷蓝鲸优化实战(摘自高可用架构)
(原创)2016-07-26 吴建超 高可用架构导读:Redis Cluster 作者建议的最大集群规模 1,000 节点,目前优酷在蓝鲸项目中管理了超过 700 台节点,积累了 Redis Clus ...
- Linux centosVMware 集群介绍、keepalived介绍、用keepalived配置高可用集群
一.集群介绍 根据功能划分为两大类:高可用和负载均衡 高可用集群通常为两台服务器,一台工作,另外一台作为冗余,当提供服务的机器宕机,冗余将接替继续提供服务 实现高可用的开源软件有:heartbeat. ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- ubuntu ceph集群安装以及简单使用
ubuntu ceph安装以及使用 1.安装环境 本文主要根据官方文档使用ubuntu14.04安装ceph集群,并且简单熟悉其基本操作.整个集群包括一个admin节点(admin node,主机名为 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十七)Elasticsearch-6.2.2集群安装,组件安装
1.集群安装es ES内部索引原理: <时间序列数据库的秘密(1)—— 介绍> <时间序列数据库的秘密 (2)——索引> <时间序列数据库的秘密(3)——加载和分布式计算 ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
随机推荐
- java 数据类型优先级
由低到高:byte,short,char—> int —> long—> float —> double 1. 不能对boolean类型进行类型转换. 2. 不能把对象类型转换 ...
- office自签名证书
在 Office安装目录,找到 SELFCERT 文件,双击打开填写名称,生成
- Re(正则表达式)库入门
一.正则表达式的概念 正则表达式 "一行胜千言" regular expression regex RE 是用来简洁表达一组字符串的表达式. 'PN' 'PYN' 'PYTN' & ...
- Linux03——磁盘分区和挂载
Windows下的磁盘分区: 常用的两种磁盘分区类型 mbr: 操作系统安装在主分区 只支持4个主分区 拓展分区占一个主分区 gpt(win7 64位之后) 无限主分区 支持超大硬盘3T以上 查看所有 ...
- 2019 EIS高校安全运维赛 misc webshell
webshell 第一种思路: 1.菜刀都是http协议,发的包都是POST包,所以在显示过滤器下命令:http.request.method==POST 2.右键,追踪tcp流,发现是蚁剑流量 3. ...
- JavaScript 事件 继承链 元素和结点
继承链: HTMLElement->Element->Node->EventTarget->Object document和body:document代表整个文档,body是指 ...
- 洛谷P1049装箱问题(01背包)
题目描述 有一个箱子容量为VVV(正整数,0≤V≤200000 \le V \le 200000≤V≤20000),同时有nnn个物品(0<n≤300<n \le 300<n≤30, ...
- java处理节假日和工作时间的工具类
import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.ArrayList; impo ...
- SpringCloud全家桶学习之消息总线---SpringCloud Bus
一.概述 ConfigClient(微服务)从ConfigServer端获取自己对应的配置文件,但是目前的问题是:当远程git仓库配置文件发生改变时,每次都是需要重启ConfigCient(微服务), ...
- DELPHI开发和使用REDIS
DELPHI开发和使用REDIS REDIS SERVER是独立的存在,支持WINDOWS,LINUXREDIS PUB/SUB 用于聊天 只是其中的一种用法任何消息或其他类型数据 都可以必须安装 ...