机器学习技法笔记(2)-Linear SVM
从这一节开始学习机器学习技法课程中的SVM, 这一节主要介绍标准形式的SVM: Linear SVM
引入SVM
首先回顾Percentron Learning Algrithm(感知器算法PLA)是如何分类的,如下图,找到一条线,将两类训练数据点分开即可:
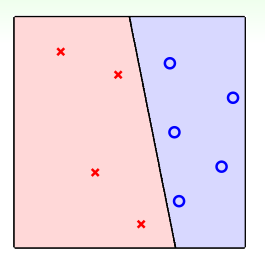
PLA的最后的直线可能有很多条,那到底哪条好呢?好坏的标准则是其泛化性能,即在测试数据集上的正确率,如下,下面三条直线都能正确的分开训练数据,那到底哪个好呢?SVM就是解决这个问题的。
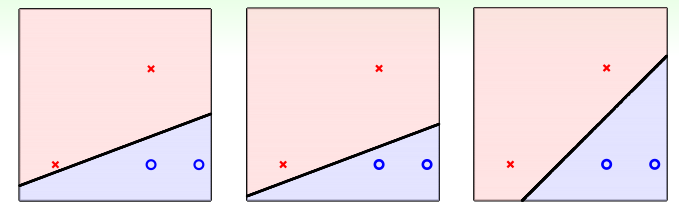
SVM求解
直觉告诉我们最右的要好一些,因为测试数据的分布应该与训练数据的分布类似,因此看起来它可以容忍更多的噪音,假设有一个数据在第一个红叉叉下方位置,也是属于叉类别,前两直线则容易把它分到圈圈的类别,而造成错误。因此理想的直线或者分类平面应该距离两类训练数据集越远越好:也就是下面的灰色区域越胖越好:
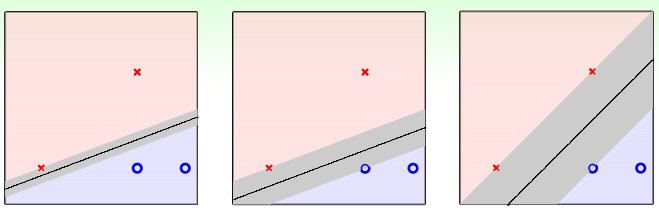
灰色区域的宽度是由直线与训练数据(x_{1..N}) 中到分类平面最近的距离决定的,这个距离称为margin,因此我们就可以将问题描述如下:
[begin{align} & maxlimits_{W,b}(margin(W,b)) \ & s.t. y_n(W^TX_n+b) > 0 end{align}]
其中,分类平面由(W,b)决定,我们要找出最大(margin)的那条直线,这里的(margin(W)=minlimits_{n=1...N} distance(x_n,,W,b)), 约束条件是这条直线已经将两类完全分开,即:(y_n(X_n+b) >0) 。下面我们看看点((x_n))到平面(W^TX+b = 0)的距离,看下图:
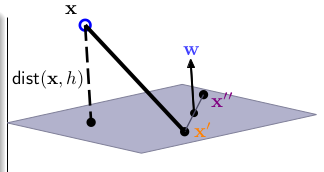
(W) 为平面(W^TX+b=0)的法向量,(x^{'})与(x^{''})为平面上的两个点,现在如果要求点(X)到平面的距离(dist(X,W,b)),即向量(X-X^{'})投影(proj)到法向量(W):
[distance(X,W,b)=left | frac{W^T}{Arrowvert WArrowvert }(X-X^{'}) right |= frac{1}{Arrowvert WArrowvert }|(W^TX +b) |]
到此,再结合约束条件(y_n(W^TX+b)>0, y_n in {-1, 1}), 点(X)到平面的距离可以通过去绝对值符号,转化为如下的式子:
[distance(X,W,b)=frac{1}{Arrowvert W Arrowvert }y_n(W^TX+b)]
因此问题转化如下的优化问题:
[begin{align} & maxlimits_{W,b} quad & margin(b,W) \ & s.t. & every y_n(W^TX_n +b) > 0 \ & & margin(b,W) = minlimits_{n=1..N} frac{1}{Arrowvert W Arrowvert}y_n(W^TX_n +b)end{align}]
另外,考虑到(W^TX+b=0)与(2W^TX+2b=0)这两个平面是同一个平面,只是对(W,b)经过了放缩(scaling),因此在缩放的过程中,不管是(W,b),还是(2W,2b), 都是对应同一个平面,因此求距离进行优化的过程不会有影响,利用这个特点,同时为了方便计算,对于某个的超平面,作出如下的假设放缩:
[minlimits_{n=1...N}y_n(W^TX_n+b) = 1]
因为对于一个固定的平面,通过放缩,肯定存在一组(W,b)使得上述的等式成立,同时也保证了条件(y_n(W^TX_n+b) >0),这样(margin(W,b) = frac{1}{Arrowvert W Arrowvert}),因此我们的优化问题转化为如下:
[begin{align} & maxlimits_{W,b} quad frac{1}{Arrowvert WArrowvert} \ & s.t. qua 大专栏 机器学习技法笔记(2)-Linear SVMd minlimits_{n=1...N}(y_n(W^TX_n+b)) =1 end{align}]
上述的约束条件是最小值等于1,对于优化问题来说,一般是某个等式或者不等式,这样容易求解,因此将上述的约束条件转为:[y_n(W^TX_n +b) geq 1, quad for all n]
考虑上述转换的正确性: 反证法,假设对于所有的(n), 有(y_n(W^TX_n+b) > 1), 即不满足最小值为1的条件,不妨设为(min = K, K>1),设此时得到的最优解为(W,b),那么(frac{W}{K},frac{b}{K}) 很显然比(W,b)更优,矛盾。因此下面两式等价:
[begin{align}& min(y_n(W^TX_n + b)) =1 \ & y_n(W^TX_n+B) geq 1, for all n end{align}]
再结合将求max转为min, 求距离,转为求平方等转化,最后我们的优化问题如下:
[begin{align} & minlimits_{W,b} quad frac{1}{2}W^TW \ & s.t. y_n(W^TX_n +b) geq 1, for all n end{align}]
这个问题的优化方程为二次方程,条件为一次线性约束,是一个典型的二次规划问题(Quadratic Programming),而QP问题有很多解法,我们只需要将上述优化问题,转化为QP问题解法的格式,然后直接代入QP Solver,即可,如下:

左侧是我们最后的优化问题,右侧是标准的QP问题的输入格式,一共有4个输入变量: (Q,p,A,c), 及一个最终的优化结果: (u) ,我们只需要表示出上述四个输入变量,就可以输入到某个QP Solver里面即可,通过对应关系,表示如下:
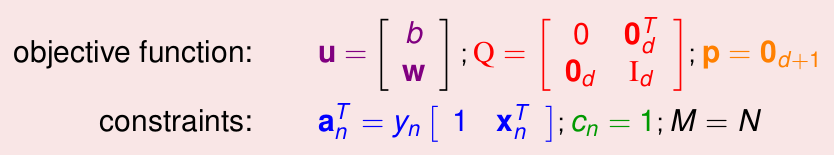
这样就可以得到最优的(W,b),进而求出(g_{SVM} = sign(W^TX+b)),进行后续预测。
上述的算法仅仅是最简单的线性SVM, 不过是其它类型SVM的基础,总结一下,流程很简单,如下:
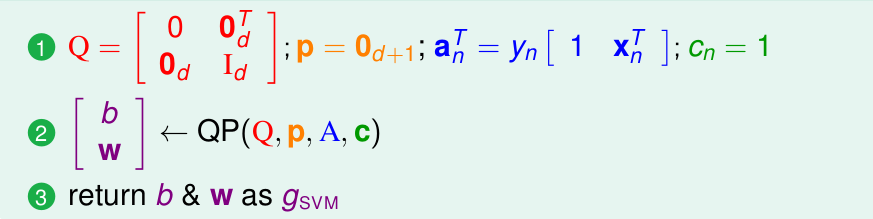
这种算法同样也可以解决非线性分类问题,通过之前的非线性转化,到线性空间: (z_n = phi(x_n)),理论上即可直接应用到非线性问题中。不过缺陷也很明显,要求数据点必须线性可分,由于这个特点,这种算法也叫做: Linear Hard-Margin SVM。
SVM 与 VC 维
这里需要提一下,SVM(Support Vector Machine)的含义,我们了解到,SVM就是要找到最胖的那个分类面,如下:
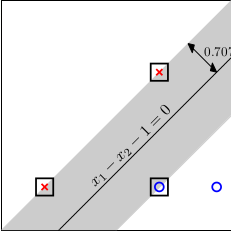
其中,在边界上的用黑框圈出来的三个点,我们就称为SV,Support Vector,因为它们才是求解过程中,真正起到作用的点,其余的点没有起到作用,后续的课程中也有进一步的介绍SV。
简单来说,SVM是基于PLA的一个算法,上面开始说了, 直觉告诉我们最胖的直线应该容错性好,其中的原理其实则是SVM相对于PLA,VC维降低了(注: 算法的VC维的定义不太明确,类比与(mathcal{H})的VC维定义即可, 这里只是定性的介绍),看下图:
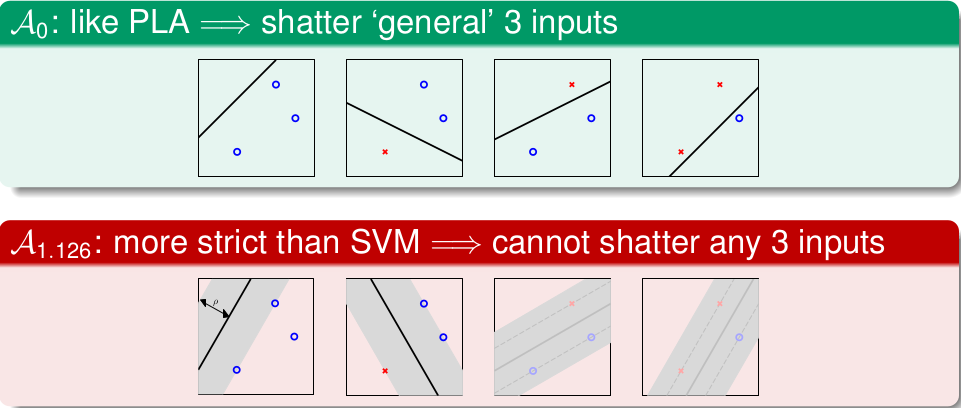
以三个输入的数据为例,PLA可以shatter(能够将(2^3)种情况都分开),而无法将4个数据点shatter,因此VC(PLA)=3,我们从另外一个角度来考虑, 假设我们规定了Margin的值为(rho) ,也就是胖瘦的程度,那么肯定会存在输入数据量为3,且无法shatter的情形,比如上图的后两种,在(rho)下 无法shatter,因此大致看起来,(d_{VC}(rho) < 3)的。其实有严格的数学证明,可以得到:
[d_{VC}(rho) leq d+1 = d_{VC}(PLA)]
VC维减少了,意味着复杂度降低,也就是说更不容易overfitting,泛化性能更好,这也是就是我们要找最胖的分类面的原因。
机器学习技法笔记(2)-Linear SVM的更多相关文章
- 机器学习技法笔记:Homework #5 特征变换&Soft-Margin SVM相关习题
原文地址:https://www.jianshu.com/p/6bf801bdc644 特征变换 问题描述 程序实现 # coding: utf-8 import numpy as np from c ...
- 机器学习技法笔记:01 Linear Support Vector Machine
Roadmap Course Introduction Large-Margin Separating Hyperplane Standard Large-Margin Problem Support ...
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- Coursera台大机器学习课程笔记8 -- Linear Regression
之前一直在讲机器为什么能够学习,从这节课开始讲一些基本的机器学习算法,也就是机器如何学习. 这节课讲的是线性回归,从使Ein最小化出发来,介绍了 Hat Matrix,要理解其中的几何意义.最后对比了 ...
- Coursera台大机器学习课程笔记10 -- Linear Models for Classification
这一节讲线性模型,先将几种线性模型进行了对比,通过转换误差函数来将linear regression 和logistic regression 用于分类. 比较重要的是这种图,它解释了为何可以用Lin ...
- 机器学习技法笔记:15 Matrix Factorization
Roadmap Linear Network Hypothesis Basic Matrix Factorization Stochastic Gradient Descent Summary of ...
- 机器学习技法笔记:07 Blending and Bagging
Roadmap Motivation of Aggregation Uniform Blending Linear and Any Blending Bagging (Bootstrap Aggreg ...
- 机器学习技法笔记:04 Soft-Margin Support Vector Machine
Roadmap Motivation and Primal Problem Dual Problem Messages behind Soft-Margin SVM Model Selection S ...
- 机器学习技法笔记:05 Kernel Logistic Regression
Roadmap Soft-Margin SVM as Regularized Model SVM versus Logistic Regression SVM for Soft Binary Clas ...
随机推荐
- Laravel常见问题总结
1.Whoops, looks like something went wrong. 一般报这个问题是由于复制框架文件时没有把相应的env (隐藏文件) 复制 导致新复制的框架没有配置选项 解决方法: ...
- [转载]Python方法绑定——Unbound/Bound method object的一些梳理
本篇主要总结Python中绑定方法对象(Bound method object)和未绑定方法对象(Unboud method object)的区别和联系.主要目的是分清楚这两个极容易混淆的概念,顺便将 ...
- [原]PInvoke导致栈破坏
原, 总结, 调试, 调试案例 项目中遇到一个诡异的问题,程序在升级到.net4.6.1后会崩溃,提示访问只读内存区.大概现象如下: debug版不崩溃,release版稳定崩溃. 只有x64位的程 ...
- windows系统安装msi文件总提示2502、2503的错误
首先: 1.按WIN+R,在运行框中输入“gpedit.msc” 确认:2.打开本地策略组编辑器后依次展开 :“计算机配置”->“管理模板”->“windows组件”->“windo ...
- 37)PHP,获取数据库值并在html中显示(晋级2)
下面的是上一个的改进版,我知道为啥我的那个有问题了,因为我的__construct()这个函数的里面的那个变量名字搞错了,哎,这是经常犯得毛病,傻了吧唧,气死我了. 之前的那个变量的代码样子: cla ...
- Qt LNK1112: 模块计算机类型“x64”与目标计算机类型“X86”冲突问题
解决方法:1.找到选项: 2.点击构建套件kit,选择x86_amd64,之后便不会出现类似问题了
- jquery JavaScript如何监听button事件
下面的html页面中有两个按钮 <div class="layui-tab-item layui-show"> <form class="layui-f ...
- python学习笔记(23)-异常处理
#异常处理与调试 #异常:在运行代码过程中遇到的任何错误,带有error字样的都是异常 #异常处理,对代码中所有可能出现的异常进行的处理 #1.处理某个错误 2,处理某个类型的错误 3 有错就抓 一. ...
- Spring Boot: Jdbc javax.net.ssl.SSLException: closing inbound before receiving peer's close_notify
jdbc:mysql://127.0.0.1:3306/xxx?useSSL=false 在后面添加?useSSL=false即可 参考网站
- spring boot 测试插件使用及result风格实例1&打包启动
本节主要内容: 1:spring boot 小插件使用 2:构建第一个简单的result风格的实例并访问 3:将项目打成jar包后启动并访问. 一:添加boot devtools插件: 执行完成后,查 ...